В одной из предыдущих статьей мы рассказывали о том, что самым популярным фреймворком 2020 по данным Kaggle стал scikit-learn. Его использовали более 80% респондентов. Он был очень удобен и прост в применении, из-за чего он и сыскал такую популярность. Но все не так радужно и однозначно, как кажется на первый взгляд.
Например, студент краковского Научно-технического университет Jakub Adamczyk в своей работе раскрыл самые слабые точки этого фреймворка. Более того, он смог предложить альтернативу, которая позволяет получить значительный прирост в эффективности кластеризации k-средних: ускорить процесс в 8 раз и в 27 раз снизить общее число ошибок при 25 строчном коде в сравнении scikit-learn. Речь идет о библиотеке от FAISS (Facebook AI Research Similarity Search).
Команда LabelMe разбирается, как фреймворк обеспечивает такую высокую скорость и точность вычислений.

Scikit-learn vs FAISS
В обеих библиотеках мы должны указать гиперпараметры алгоритма: количество кластеров, количество перезапусков (каждый из которых начинается с других начальных предположений) и максимальное количество итераций.
K-Means - это итеративный алгоритм, который объединяет точки данных в k-кластеры, каждый из которых представлен средней / центральной точкой (центроидом). Обучение начинается с некоторых предварительных предположений, а затем чередуется между двумя этапами:
1. Присвоением - относим каждую точку ближайшему кластеру (используя евклидово расстояние между точкой и центроидами).
2. Обновлением - повторно вычисляем каждый центроид, определяя среднюю точку из всех точек, назначенных этому кластеру на текущем этапе.
Для прогнозирования мы выполняем поиск 1-ближайшего соседа (kNN с k = 1) между новыми точками и центроидами.
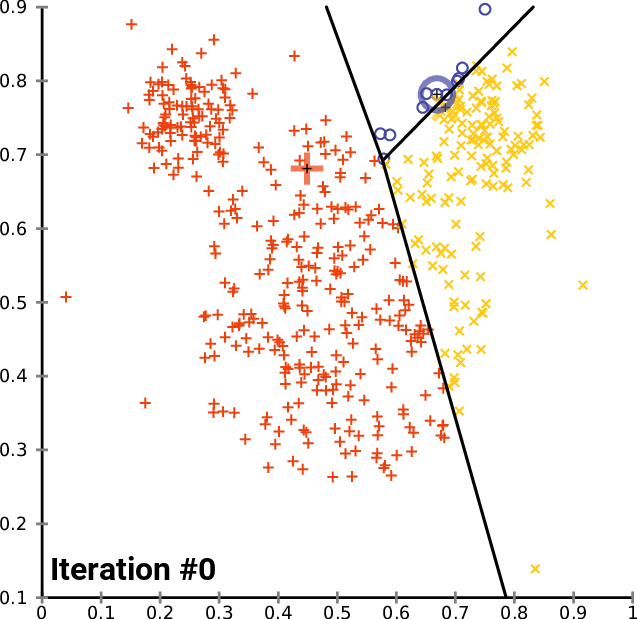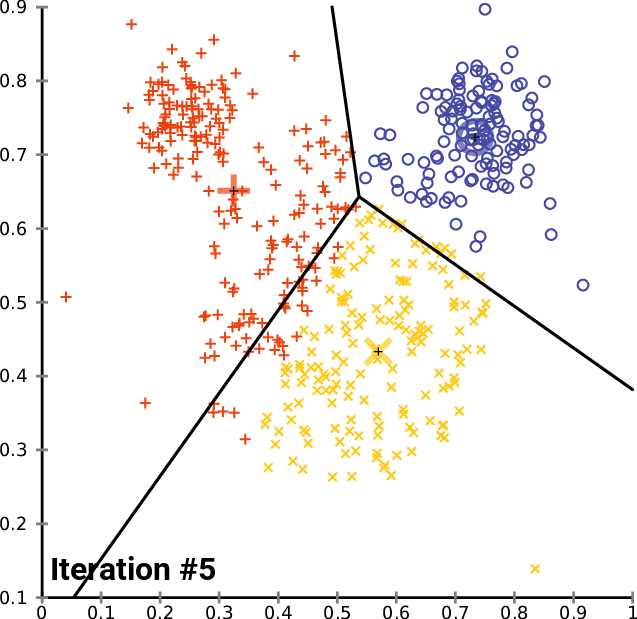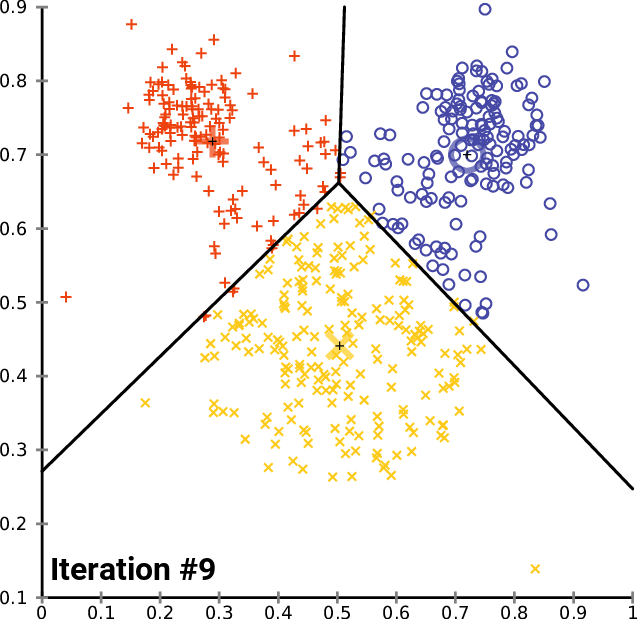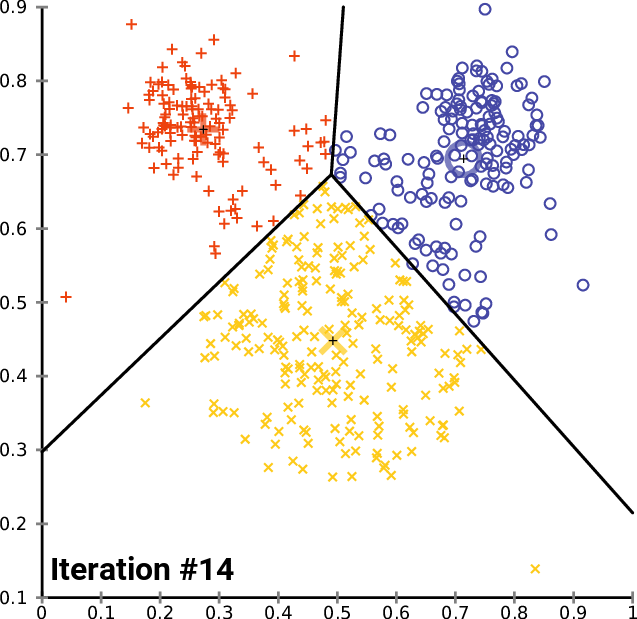
Как видно из примера, ядро алгоритма ищет ближайших соседей, в частности ближайших центроидов, как для обучения, так и для прогнозирования. И именно здесь FAISS на порядки быстрее, чем Scikit-learn. Он использует отличную реализацию C ++, параллелизм, где это возможно, и даже графический процессор. Кроме того, FAISS оптимизирован в части использования памяти и поиска на больших батчах.
Индексы
Одним из важнейших понятий при работе с FAISS является index. Это совокупность параметров и векторов, который могут сильно отличаться в зависимости от нужд пользователя. Имена векторов хранятся в индексе: либо в нумерации от 0 до n, либо в виде числа, влезающего в тип Int64.
Разобраться в работе индексов можно на примере кода из статьи Алексея Маркитантова (@AlexMFL на Хабре, очень рекомендуем). В его примере индекс лишь хранит в себе все вектора, а поиск по заданному вектору осуществляется полным перебором. Поэтому и обучать его не нужно: при работе с небольшими объемами данных такой простой индекс может покрыть нужды поиска.
Фрагмент кода:
import numpy as np
dim = 512 # рассмотрим произвольные векторы размерности 512
nb = 10000 # количество векторов в индексе
nq = 5 # количество векторов в выборке для поиска
np.random.seed(228)
vectors = np.random.random((nb, dim)).astype('float32')
query = np.random.random((nq, dim)).astype('float32')
Далее создание Flat индекса и добавление векторов без обучения:
import faiss
index = faiss.IndexFlatL2(dim)
print(index.ntotal) # пока индекс пустой
index.add(vectors)
print(index.ntotal) # теперь в нем 10 000 векторов
Теперь вычисляем 7 ближайших соседей для первых пяти векторов из vectors:
topn = 7
D, I = index.search(vectors[:5], topn) # Возвращает результат: Distances, Indices
print(I)
print(D)
Видим, что самые близкие соседи с расстоянием 0 – это сами векторы, остальные отранжированы по увеличению расстояния. Проведем поиск по нашим векторам из query:
D, I = index.search(query, topn)
print(I)
print(D)
Теперь расстояния в первом столбце результатов не нулевые, так как векторов из query нет в индексе.
Индекс можно сохранить на диск и затем загрузить с диска:
faiss.write_index(index, "flat.index" )
index = faiss.read_index("flat.index" )
Внедрение кластеризации K-средних с помощью FAISS
Замечательная особенность FAISS - наличие подробной инструкции по установке и сборке и отличная документация с примерами. После установки мы можем писать собственно кластеризацию. Код довольно прост и имитирует Scikit-learn API.
import faiss
import numpy as np
class FaissKMeans:
def __init__(self, n_clusters=8, n_init=10, max_iter=300):
self.n_clusters = n_clusters
self.n_init = n_init
self.max_iter = max_iter
self.kmeans = None
self.cluster_centers_ = None
self.inertia_ = None
def fit(self, X, y):
self.kmeans = faiss.Kmeans(d=X.shape[1],
k=self.n_clusters,
niter=self.max_iter,
nredo=self.n_init)
self.kmeans.train(X.astype(np.float32))
self.cluster_centers_ = self.kmeans.centroids
self.inertia_ = self.kmeans.obj[-1]
def predict(self, X):
return self.kmeans.index.search(X.astype(np.float32), 1)[1]
Несмотря на простоту кода, важно помнить о нескольких нюансах:
- В FAISS есть встроенный класс K-Means под работу с конкретными тасками, но названия некоторых параметров очень отличаются. Подробнее об этом можно почитать здесь.
- нужно убедиться, что вы используете формат np.float32 , так как другие FAISS просто не поддерживает;
- kmeans.obj возвращает список ошибок во время обучения, поэтому, чтобы получить только последнюю, как в Scikit-learn, мы используем индекс [-1];
- прогнозирование выполняется с помощью структуры данных Index , которая является основным строительным блоком FAISS и используется во всех поисках ближайших k-соседей;
- при прогнозировании мы выполняем поиск kNN с k = 1, возвращая индексы ближайших центроидов из self.cluster_centers_ (index [1], так как index.search () возвращает расстояния и индексы)
Сравнение времени и точности
Начнем с того, что FAISS демонстрирует нереальную эффективность при работе на GPU. При этом его реализация на CPU незначительно проигрывает hnsw (nmslib) и оптимизирован в части использования памяти и поиска на больших батчах. Смотрите пример ниже.
Для сравнения скорости и качества были выбраны популярные наборы данных, доступные в Scikit-learn. На их примере мы сравнили время обучения и прогнозирования обоих алгоритмов.
Чтобы было проще воспринимать эту информацию, мы составили таблиц, в которой расписано во сколько раз быстрее кластеризация на основе faiss, чем Scikit-learn. Также отдельно заполнили таблицу с ошибками в процессе обучения.
Важно: здесь время процесса измерялось функцией time.process_time () для получения более точных результатов. Они представляют собой средние показатели из 100 прогнозов, не считая MNIST, где Scikit-learn занял слишком много времени.
Как мы видим из таблиц, кластеризация k-средних для небольших наборов данных (первые 4 набора) проходит быстрее Scikit-learn, да и ошибок там значительно меньше. Если же говорить о более крупных наборах данных, например, MNIST, то FAISS ни оставляет ни шанса своему оппоненту. Обучение прошло в 20,5 раз быстрее, сокращая общую продолжительность с 3 минут до менее чем 8 секунд! Но еще больше впечатляет количество ошибок: в 27,5 раз меньше.
Вывод
После введения вы могли подумать, что мы тут собираемся совсем уж унижать и оскорблять Scikit-learn. Но нет, он по прежнему хорош и универсален с одной лишь оговорочкой: только если речь идет о небольших объемах исходных данных. Колдуете над простеньким алгоритмом с кластеризацией k-средних ? Тогда возможностей этого фрэймворка вам хватит за глаза.
Если же вы решили приблизить судный день и создать свой скайнет, тогда на его "эволюцию" уйдет примерно столько же, сколько и кожаных мешков. Поэтому, имея тысячи исходных образцов, вы значительно упростите себе жизнь, выбрав FAISS. Особенно если у вас есть графический процессор с высокой вычислительной мощностью. Главное - грамотно уместить свою задачу в 25ти строчный код.