Нам известно множество примеров долгоиграющих противостояний: iOS и Android, Mercedes и BMW, демократы и республиканцы. Приверженцы каждой из сторон готовы спорить до бесконечности, пытаясь доказать, что именно их выбор истинно и единственно верный.
Подобные войны кипят и в Data Science-сообществе. Наглядное тому доказательство — выбор способа визуализации. Специалисты, работающие на Python, сразу же ответ: “Конечно, Matplotlib”. Сторонники языка программирования R возразят и провозгласят королем визуализации Ggplot2 .
Чтобы разобраться, какой из методов действительно лучше, мы столкнем их лбами в открытом противостоянии. LabelMe — лишь беспристрастный рефери в этом поединке. Итак, удар гонга, первый раунд и пусть победит сильнейший.

Раунд 1: точечная диаграмма
Для построения диаграммы мы использовали статистические данные о о лишнем весе. Они включают замеры различных участков тела, начиная с шеи и заканчивая ногами. Brozek — это переменная, отображающая количество жира в организме. Графики показывают рост и вес выборочных данных, где цветовая градация и размер точек зависят от индивидуальных показателей.
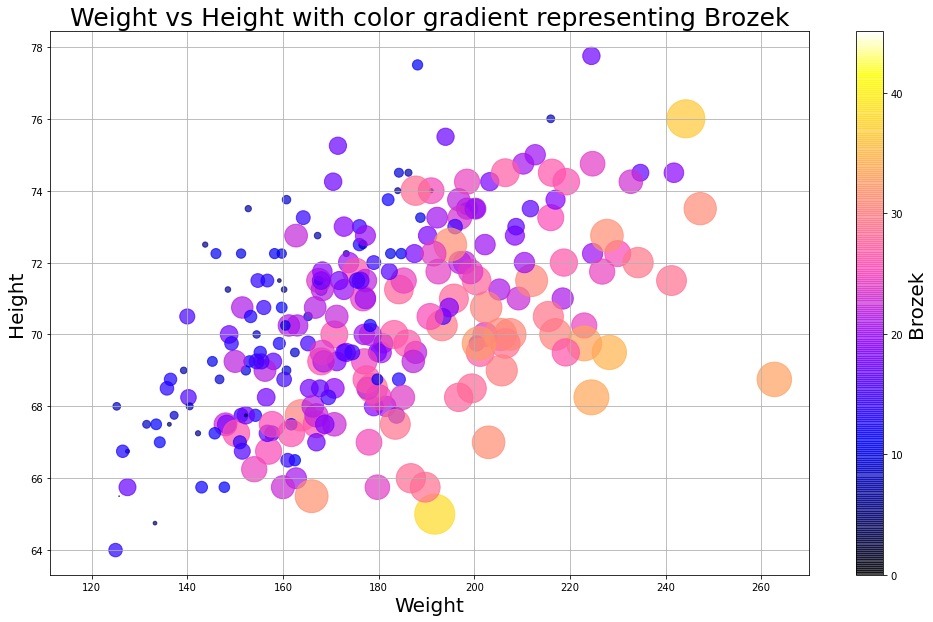
Фрагменты кода Matplotlib:
plt.figure(figsize=(17,10))
plt.scatter(fat['weight'], fat['height'], c=fat['brozek'],s=fat['siri']**2 , alpha=0.7,cmap = 'gnuplot2')
plt.title('Weight vs Height with color gradient representing Brozek',fontsize=25)
plt.xlabel('Weight', fontsize=20)
plt.ylabel('Height', fontsize=20)
plt.grid(True)
cb= plt.colorbar()
cb.set_label('Brozek', fontsize=20)
plt.show()
Фрагмент кода Ggplot2:
# Scatter plot
sp3<-ggplot(fat, aes(x=weight, y=height, color=brozek)) + geom_point(aes(size = siri), alpha=0.7) + ggtitle("Weight vs Height with color gradient representing Brozek")
sp3+ scale_color_gradient(low="blue", high="yellow")+ theme_bw()
ggsave( width = 7, height = 5, dpi = 300,"scatter_ggplot.png")
Оба способа визуализации показали одинаковые результаты и были достаточно просты в работе. Можем сказать лишь то, что в Matplotlib лучше схема цветовых градиентов.
Раунд 2: Контурный график
Здесь используется два разных набора данных. Для Matplotlib — данные психологических экспериментов, а именно переменные мозжечковой миндалины и фронтальной части поясной коры. Именно эти участки задействуются при принятии решений и отвечают за эмоции. Для Ggplot2 мы использовали данные о вулканической активности, измеряющие интервалы между “засыпанием” вулканов и извержениями.
Фрагменты кода Matplotlib:
fig, ax = plt.subplots(figsize=(15,15))
# gridx, gridy
divider = make_axes_locatable(ax)
ax_cb = divider.new_horizontal(size="5%", pad=0.05)
fig.add_axes(ax_cb)
c =ax.contour( np.rot90(np.fliplr(Z_error)), colors='white',extent=[xmin, xmax, ymin, ymax])
plt.clabel(c, inline=True, fontsize=8)
# contours = plt.contour(np.rot90(Z_error),3, colors='black')
im= ax.imshow(np.rot90(Z_error), cmap='viridis',
extent=[xmin, xmax, ymin, ymax], alpha = 1)
plt.colorbar(im, cax=ax_cb)
# ax.plot(amy, acc, 'k.', markersize=2)
ax.set_xlim([xmin, xmax])
ax.set_ylim([ymin, ymax])
ax.set_title('Conditional KDE contour plot of Error, orientation=2')
ax.set_xlabel('Amygdala')
ax.set_ylabel('Acc')
plt.show()
Фрагмент кода Ggplot2:
# contour bands
m + stat_density2d(aes(fill = ..density..), geom = "raster", contour = FALSE)+
stat_density2d(size = 0.5, colour = "white")+
scale_fill_viridis_c(option = "C",alpha =1)
ggsave( width = 10, height = 8, dpi = 300,"contour_ggplot.png")
Здесь мы также видим, что разница визуализации еле заметна. Однако линии и метки в Matplotlib гораздо четче и понятнее, чем в Ggplot2. Несмотря на то, что код у Matplotlib значительно длиннее, составить график в нем намного проще, так как настройки по умолчанию были лучше.
Раунд 3: тепловая карта
Здесь мы также использовали данные о лишнем весе из пункта один. Тепловая карта отображает корреляцию для всех переменных в датасете: желтый означает, что она высока, а синий, наоборот, отображает меньшую корреляцию.
Фрагмент кода Matplotlib:
f = plt.figure(figsize=(19, 15))
plt.matshow(fat.corr(), fignum=f.number,cmap ='viridis')
plt.xticks(range(18),fat.columns, rotation=45)
plt.yticks(range(18),fat.columns)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)
plt.title('Correlation Matrix', fontsize=16);
Фрагмент кода Ggplot2:
# create correlation matrix
cormat <- round(cor(fat),2)
melted_cormat <- melt(cormat)
# plot heatmap
ggplot(data = melted_cormat, aes(x=Var1, y=Var2, fill=value)) +
geom_tile()+
scale_fill_viridis_c(alpha = 1) +
theme(axis.text.x = element_text(angle=45, vjust=0.6))+ggtitle("Correlation Matrix")
Несмотря на схожие результаты, в Matplotlib были дополнительные сложности с выравниванием переменных. Это затруднило чтение заголовков. Настройки по умолчанию у Ggplot2 оказались лучше. С другой стороны в Matplotlib есть функция matshow () для корреляционной матрицы. В Ggplot2 такой функции нет, поэтому необходимо вручную подготовить корреляционную матрицу перед построением графика.
Раунд 4: Многострочный график регрессии
Для построения многострочного графика был использован известный датасет Iris. Для визуализации линии регрессии ширины лепестка, используется длина лепестка в качестве предиктивной переменной. Линии регрессии сгруппированы по видам.
Фрагмент кода Matplotlib:
groups = iris1.groupby("species")
plt.figure(figsize=(12,8))
colors = {'setosa':'darkviolet', 'versicolor':'cornflowerblue', 'virginica':'orchid'}
for name, group in groups:
plt.plot(group["sepal_length"], group["sepal_width"], marker="o", linestyle="",
label=name, ms=10, color=colors[name], alpha=.8)
m, b = np.polyfit(group["sepal_length"], group["sepal_width"], 1)
plt.plot(group["sepal_length"], m*group["sepal_length"]+b, linewidth=5,
color=colors[name], alpha=.5)
plt.legend()
plt.title('Iris Species classification')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
Фрагмент кода Ggplot2:
theme_set(theme_bw())
smooth <- ggplot(data=iris, aes(x=Sepal.Length, y=Sepal.Width, color=Species)) +
geom_point(aes(shape=Species), size=2.5) + xlab("Sepal Length") + ylab("Sepal Width") +
ggtitle("Scatterplot with smoothers")
# generalised additive model
smooth + geom_smooth(method="gam", formula= y~s(x, bs="cs"))
ggsave( width = 8, height = 5, dpi = 300,"iris_line_ggplot.png")
Matplotlib не может создавать теневую область для линий регрессии, в то время как в Ggplot2 это можно сделать легко и быстро. Пользователям Python в таком случае может помочь только набор Seaborn , но это уже совсем другая история. К тому же в Matplotlib приходилось строить каждый отдельный график с помочью функции groupby (). В то время как в Ggplot2 группировать можно сразу через функцию построения графика.
Раунд 5: Многострочный связанный график
Используемые здесь данные взяты из проекта перекрестной проверки, в котором сравнивалась линейная регрессия и k-ближайшие соседи с различными значениями k. На приведенных ниже графиках показана зависимость ошибки теста от числа итераций для перекрестной проверки по методу Монте-Карло.
Фрагмент кода Matplotlib:
plt.figure(figsize=(20,15))
plt.plot( 'KNN1', data=teall2, marker='^',alpha=.7, markersize=20, color='indianred', linewidth=5)
plt.plot( 'KNN9', data=teall2, marker='D',alpha=.7, markersize=20, color='mediumorchid', linewidth=5)
plt.plot( 'KNN5', data=teall2, marker='o',alpha=.7, markersize=20, color='rebeccapurple', linewidth=5)
plt.plot( 'LR', data=teall2, marker='s',alpha=.7, markersize=20, color='navy', linewidth=5)
plt.legend( prop={'size':20})
plt.xlabel('Number of iterations', fontsize=20)
plt.ylabel('Test Error', fontsize=20)
plt.title('Model error over 100 iterations of CV, matplotlib', fontsize=25)
plt.savefig('linegraph_matplot.png')
Фрагмент кода Ggplot2:
p <-ggplot(teall2, aes(x=1:nrow(teall2))) + geom_line(aes(y = KNN1), color = "indianred") +
geom_point(aes(y = KNN1,size = KNN1*2, alpha= 0.7), color = "indianred", shape = 15) +
geom_line(aes(y = KNN9), color="mediumpurple")+
geom_point(aes(y = KNN9,size = KNN9*0.8, alpha= 0.7), color="mediumpurple", shape = 16) +
geom_line(aes(y = LR), color="navy")+
geom_point(aes(y = LR,size = LR*0.5, alpha= 0.7), color="navy", shape = 17) +
geom_line(aes(y = KNN5), color = "darkorchid") +
geom_point(aes(y = KNN5,size = KNN5*0.5, alpha= 0.7), color = "darkorchid", shape = 18) +
theme_bw()+
ggtitle("Model error over 100 iterations of cross validation") +
xlab("Number of iterations") + ylab("Model Error")
p + theme(
plot.title = element_text(color="navy", size=14, face="bold"),
axis.title.x = element_text(color="navy", size=14, face="bold"),
axis.title.y = element_text(color="navy", size=14, face="bold")
,legend.title = element_blank())
# geom_line(aes(group=paste0(variable, InModule)))
ggsave( width = 10, height = 6, dpi = 300,"multilinegraph_ggplot.png")
И Matplotlib, и Ggplot2 одинаково хороши в визуализации для презентаций и не имели проблем с обработкой данных. Однако, Ggplot2 не показывал “легенду”: к каким моделям относятся те или иные линии. Да и код для Matplotlib был проще и понятнее. В Ggplot2 маркеры и линии нужно было добавлять отдельно для каждой модели.
Раунд 6: Круглая гистограмма
Круглая гистограмма в целом довольно сложный для быстрого понимания вид визуализации. Поэтому особенно важно, чтобы выбранный для работы инструмент позволял сделать ее удобочитаемой и легкой в восприятии. Для построения гистограммы в Ggplot2 использовались данные об автомобилях, чтобы показать разницу пробега в разных моделей. А для Matplotlib ввиду сложности визуализации были выбраны фиктивные данные. Не переживай, дальше все объясним.
Фрагмент кода Matplotlib:
# Dummy data
N = 15
theta = np.linspace(0.0, 2 * np.pi, N, endpoint=False)
r = np.array(
[0.9928, 0.9854, 0.9829, 0.9794, 0.9727, 0.9698, 0.9657, 0.9641, 0.9651, 0.9482,
0.9557, 0.9404, 0.9360, 0.9270,0.9253])
width = np.array([0.4] * N)
label = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "l", "m", "n", "o", "p"]
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
ax = plt.subplot(111, projection='polar')
ax.set_rlim(0.9, 1)
ax.set_rticks(np.arange(0.94, 1, 0.02))
ax.set_thetagrids(theta * 180 / np.pi)
ax.set_rlabel_position(-15)
ax.bar(x=theta, height=r-.9, width=width, bottom=0.9, alpha=0.8, tick_label=label,color=colors)
plt.show()
Фрагмент кода Ggplot2:
mtcars$car = row.names(mtcars)
theme_set(theme_bw())
p = ggplot(mtcars, aes(x=car, y=mpg, fill=mpg))
+geom_col(width = 1, color = "white")
p <- p + coord_polar()+
scale_fill_viridis_c(option = 'C', alpha = .8)
Это один из случаев, когда Matplotlib с треском уступает. Несмотря на то, что в теории построить круговую гистограмму в нем возможно, мы не смогли использовать изначальный фрейм данных. Ggplot2 был гораздо более интуитивно понятным и создал полярную диаграмму с помощью всего одной строчки кода. Это не потребовало предварительной обработки данных. Поэтому в этому раунде лидерство остается за Ggplot2.
Раунд 7: коробчатая диаграмма
Для визуализации коробчатых диаграмм в Ggplot2 мы также использовали данные по пробегу автомобилей из предыдущего раунда. А для Matplotlib — фиктивные данные. Думаем, вы уже догадываетесь почему.
Фрагмент кода Matplotlib:
fig = plt.figure(1, figsize=(20, 8))
# Create an axes instance
ax = fig.add_subplot(111)
bp = ax.boxplot(data_to_plot, patch_artist=True)
# # change outline color, fill color and linewidth of the boxes
for box in bp['boxes']:
# change outline color
box.set( color='navy', linewidth=2)
# change fill color
box.set( facecolor = 'lavender' )
# # change color and linewidth of the whiskers
for whisker in bp['whiskers']:
whisker.set(color='navy', linewidth=2)
# # change color and linewidth of the caps
for cap in bp['caps']:
cap.set(color='mediumorchid', linewidth=2)
# # change color and linewidth of the medians
for median in bp['medians']:
median.set(color='mediumorchid', linewidth=2)
# # change the style of fliers and their fill
for flier in bp['fliers']:
flier.set(marker='o', color='navy', alpha=1)
plt.xlabel('Group', fontsize=30)
plt.ylabel('Scores', fontsize=30)
plt.title('Boxplot using Matplotlib', fontsize=35)
plt.savefig('box_matplot.png')
Фрагмент кода Ggplot2:
theme_set(theme_bw())
# multi boxplot
g <- ggplot(mpg, aes(manufacturer, cty))
g + geom_boxplot() +
geom_dotplot(binaxis='y', stackdir='center',
dotsize = .5, fill="red") +
theme(axis.text.x = element_text(angle=65, vjust=0.6)) +
labs(title="Box plot + Dot plot",
subtitle="City Mileage vs Class: Each dot represents 1 row in source data",
caption="Source: mpg",
x="Class of Vehicle",
y="City Mileage")
Это еще один пример того, что у Matplotlib есть определенные сложности и костыли, с которыми совладают только ярые питонисты. Например, исправить положение можно, используя Seabor или Pandas. Но камон: все это дополнительные трудности, которые никому из нас не нужны. А без них нам просто не удалось использовать фрейм данных с авто в нем.
Если же говорить про Ggplot2, то мы просто сгруппировали пробег по производителям автомобилей, чтобы получить несколько коробчатых диаграмм. Вуаля!
Раунд 8: Бонус
Здесь мы рассмотрим разные виды визуализации, с которыми лучше всего справляется один из двух претендентов без дополнительных инструментов. Учитывая то, что Ggplot2 и Matplotlib идут вровень, для них это отличный шанс получить недостающие очки.
Цветовые картограммы (Chloropeth maps)
Да, Python очень хорош в хлороплетах, но для их создания вам потребуются folium или plotly. Сам по себе Matplotlib в них не умеет.
Для картограммы ниже была использована информация об арестах в США, чтобы отобразить количество нападений в каждом штате.
Использованная цветовая схема очень похожа на эффект “плазмы” в Matplotlib. Но в R это опция “С” в функции Viridis.
Фрагмент кода Ggplot2:
# Retrieve the states map data and merge with crime data
states_map <- map_data("state")
arrests_map <- left_join(states_map, arrests, by = "region")
# Create the chloropelth for assault rate
ggplot(arrests_map, aes(long, lat, group = group))+
geom_polygon(aes(fill = Assault), color = "white")+
scale_fill_viridis_c(option = "C")
Трехмерный визуализация поверхности
Здесь использовались стандартный инструмент для создания 3D-визуализации на Python — plotly. Matplotlib выполняет достойную работу, хотя для создания трехмерной сетки требуется немало усилий. Matplotlib имеет отличный выбор цветовых схем и очень хорошо выполняет градацию цветов. Отметим, что в приведенном ниже коде много места занимает оценщик плотности ядра Гаусса, который в основном является функцией сглаживания. Для самой визуализации он не требуется.
Фрагмент кода Matplotlib:
from scipy import stats
gridno = 40
min_data = data.min(0)
max_data = data.max(0)
# max_data is [0.0812 0.0559]
# min_data is [-0.0676 -0.0377]
inc1 = (max_data[0]-min_data[0])/gridno
inc2 = (max_data[1]-min_data[1])/gridno
# create mesh grid
gridx, gridy = np.meshgrid( np.arange(min_data[0], max_data[0]+inc1/2,inc1),
np.arange(min_data[1], max_data[1]+inc2/2,inc2) )
gridall = [gridx.flatten(order = 'F'), gridy.flatten(order = 'F')]
gridall = (np.asarray(gridall)).T
# gaussian smoothing function
def gaussian_kernel(x):
return (1/np.sqrt(2*np.pi))*(np.e**(-(sum(x**2))/2))
# Kernel density estimate
def kde(xy, x_all, h):
px = 0
for x_i in x_all:
px += 1/h*gaussian_kernel((x_i-xy)/h)
return px/len(x_all)
h = 0.008
px_all = []
for xy in gridall:
px = kde(xy, data, h)
px_all.append(px)
# # # #
mkde = np.reshape(px_all, gridx.shape)
fig = plt.figure(figsize=(40,30))
ax=fig.add_subplot(111, projection='3d')
ax.plot_surface(gridx, gridy, mkde,cmap="Spectral")
plt.title("3D plot for multi dimentianl histogram with smoothing,
h=0.008", fontsize=40)
plt.xlabel("Amygdala",fontsize=30)
plt.ylabel("Acc",fontsize=30)
plt.savefig('3d_Spectral.png')
plt.show()
Финальный гонг: судья подсчитывают очки
Да, это противостояние было не простым. Досрочной победы не было, но, подсчитав все баллы, мы наконец можем назвать победителя. В битве за визуализацию побеждает Ggplot2 (R).
Оба пакета являются мощными инструментами для визуализации. В руках более опытного специалиста они могут дать еще более впечатляющие результаты. Matplotlib может создавать красивые графики и имеет изысканный стиль представления. Причина, по которой Ggplot2 выиграла, заключалась в его возможностях обработки данных.
Опять же, результаты могли быть совсем другими, если бы мы использовали заранее подготовленные датасеты под каждый конкретный инструмент. Именно поэтому мы рекомендуем отдавать предпочтение не разношерстным датасетам в бесплатном доступе, а собирать данные под ваши конкретные задачи.
А чтобы быть уверенным в качестве разметки и не столкнуться с проблемами при дальнейшем использовании, вы можете обратиться в LabelMe. Наличие собственного ПО и обученной базы разметчиков позволяет нам оперативно выполнять даже крупные заказы, не жертвуя качеством. К слову, убедиться в этом вы можете, оформив бесплатный тестовый датасет. Мы подготовим его уже через 3 часа после финальных обсуждений.