Меня, как и многих, периодически терзают мысли по поводу того, "кто я?", "чем занимаюсь?", про "что я?" и "какой я?" Этакая синхронизация с внешним миром, с теми смыслами, которые несу людям.
Решил провести интересный эксперимент. Многие ученые отмечаю, что человек в своей устной и письменной речи может неосознанно включать большое количество косвенной информации о себе, по тем словам, которые чаще всего употребляет. Проверю эту гипотезу!
Взял текст всех своих публикаций и скопировал в один большой документ - получилось более 50 страниц и более 20 тысяч слов. И вот эти данные big data решил проверить в анализаторах текста и сделать выводы: про что мой блог и какие смыслы я несу аудитории.
Подобные онлайн-анализаторы позволяют проверить частотность употребления слов - это самые часто употребляемые слова, сделать семантический анализ (выделение смыслового ядра). Семантическое ядро определяется путем выделения из часто встречаемых слов, существительных, которые наполняют текст смыслом. Анализаторы работают по-разному и имеют отличающийся функционал. Далее расскажу о трех сервисах и результатах их работы.
Первый сервис https://advego.com/text/seo/ - позволяет проводить анализ текста на антиплагиат и еще делать много разных интересных вещей, в том числе, проведение семантического анализа, но сервис не разрешил мне анализировать более 100 000 символов.
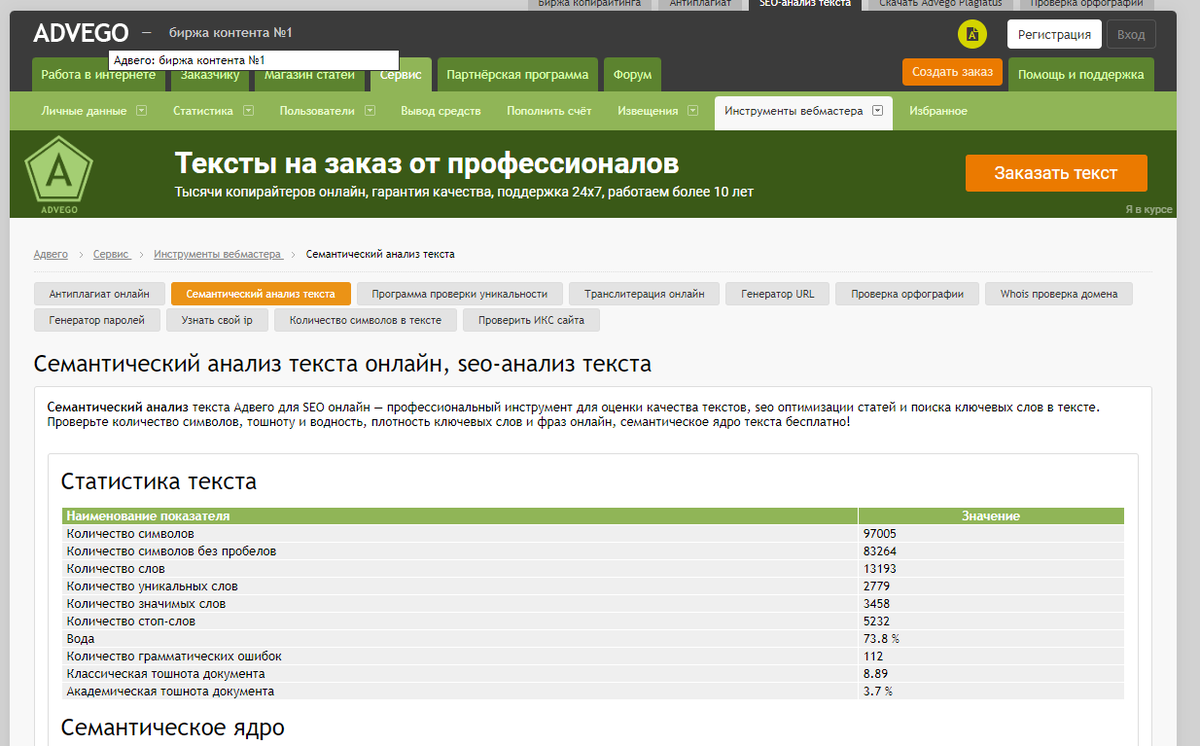
Результат работы сервиса на скриншоте. Семантическое ядро составили слова: работа, книга, образование, вопрос, навык. Действительно пишу про работу, образование, полезные навыки, пока все верно.
Второй сервис https://miratext.ru/ Этот сайт понравился - большой функциональностью, проглотил весь текст, дал много разной аналитики. Единственное - сервис требует регистрации и текст ставится в очередь на анализ, но еще есть платный функционал.
Результаты по частотному анализу получились очень похожими, снова: работа, человек, книга и другие. Вот тут я начал задумываться, что в анализаторах еще проскакивают слова мочь, нужно, должно. И вдруг меня посетила мысль, что чаще всего это слова, связанные с ответственностью, которая мне очень свойственна, и даже если я об этом в блоге не задумывался писал, из письменной речи я это исключить не могу. Ну и конечно, меня радует, тот факт, что много говорю о книгах, хотя до 30 лет не был особо читающим книголюбом.
Еще у сервиса есть интересная функция - выделения смысловых словосочетаний (n-граммы). Некоторые слова сами по себе не способны нести смысл, а вот уже когда объединятся в словосочетание, то появляется смысл, например, мастер-класс или социальная сеть.
Разбирался с этим инструментом - "текст по закону Ципфа" - показывает, как часто используются слова в соответствии с нормальностью речи естественного языка (частота употребляемости слов). Данная характеристика показывает, насколько понятен текст. Нашел в сети, что очень хороший показатель 50%, у меня получилось 48 - это радует, но еще можно повысить результаты (больше конкретики и меньше воды).
Вот это визуальный вариант часто встречаемых слов и ссылок в тексте - облако слов. Еще одна замечательная плюшка - возможность выгрузить все в виде электронной таблицы для дальнейшего анализа. Замечательный сервис мне понравился больше всего!
Третий сервис https://istio.com/ - интерфейс и функционал будет попроще, но все самое важное есть - частотный и семантический анализ.
Результаты получились очень похожими на предыдущие, но лучше проведена работа по стоп-словам (слова, которые не несут смысловой нагрузки, а предназначены для связи слов). Список получился таким: работа, человек, книга, вопрос, команда.
Вот так понял, что я трудоголик, который пишет про книги и образование, но на самом деле я хотел посвятить свой блог именно фиксации рабочих приемов, которые помогают сделать труд в области обучения более эффективным и приятным.
Такую проверку текста сделать очень быстро и результаты получаются интересные. В качестве данных можно взять блог, личный дневник, переписку с самим собой, интервью, можно анализировать чаты (только их нужно почистить от технических данных), а затем получить количественный и качественный анализ своей устной и письменной речи. Когда я затевал этот эксперимент, даже не думал, что слово "работа" может оказаться на первом месте. Но на самом деле для меня это странно, не воспринимаю любимое дело как "работу", а вам всем желаю найти такое занятие!
Жду комментариев и подписок.