
Ссылки на предыдущие статьи текущего цикла:
- Природа языкового родства, статья 1. Родство языков и их взаимопонятность;
- Природа языкового родства, статья 3а. Такие разные и такие похожие языки: фонетика;
- Природа языкового родства, статья 3б-1. Такие разные и такие похожие языки: грамматика. Часть 1, существительные;
- Природа языкового родства, статья 3б-2. Такие разные и такие похожие языки: грамматика. Часть 2, глаголы.
Ссылки на предыдущие циклы статей
- Вводный цикл: Родство языков.
Родство языков, статья 1. Близкородственные языки
(ссылки на остальные статьи цикла смотрите внутри Статьи 1).
- Первый цикл: Язык и письменность.
Язык и письменность, статья 1. Похожие буквы и похожие языки
(ссылки на остальные статьи цикла смотрите внутри Статьи 1).
Здравствуйте, уважаемые читатели!
Предлагаю вашему вниманию очередную статью из цикла «Мифы и заблуждения: природа языкового родства», целью которого является разбор наиболее распространённых ошибочных представлений о том, что кроется за понятием «родственные языки». Среди тех, кто интересуется языкознанием на непрофессиональном уровне, далеко не все отдают себе отчёт, на основе чего можно судить о родственных отношениях между языками, а на основе чего об этом судить нельзя. Не все также правильно понимают, что именно следует ожидать от родственных языков, а чего от них ожидать не стоит.
Два наиболее типичных ошибочных представления – это отождествление понятий 1) «родственные языки» и «взаимопонятные языки» (некоторые уверены, что если языки родственны, то их носители непременно должны быть способны друг друга понимать без всякой предварительной подготовки) и 2) «родственные языки» и «похожие языки» (многие считают, что если языки родственны, то они во всём должны быть похожи, а если языки хоть в чём-то похожи, то они наверняка родственны).
В первом выпуске данного цикла мы рассматривали вопрос о взаимопонятности языков и сошлись в итоге на том, что даже самые близкородственные языки вовсе не всегда оказываются взаимопонятными. Во втором выпуске этого цикла мы начали обсуждать, чем различаются понятия «родственные языки» и «похожие языки». Как мы смогли убедиться на конкретных примерах, наши собственные ощущения сходства нередко бывают субъективными и у разных людей зачастую не совпадают мнения о том, что можно назвать похожим, а что нельзя. В поисках способа непредвзятого сравнения языков, который бы не зависел от наших субъективных оценок, мы разложили человеческий язык на отдельные его уровни: на фонетику, грамматику и лексику.
В Статьях 3а и 3б мы провели сравнение отдельных особенностей фонетики и грамматики в пятнадцати широко известных языках Европы и Азии (в Статье 3а был сделан упор на сравнение фонетических особенностей этих языков, тогда как Статья 3б была главным образом посвящена сравнению их грамматических особенностей: в первой части Статьи 3б мы в основном разбирали особенности существительных, а во второй её части – особенности глаголов, а также вопросы порядка слов). Для того чтобы осуществить подобное сравнение, я специально отбирал как родственные, так и неродственные друг другу языки, сопоставляя некоторые из наиболее значимых отличительных черт их звуковых и грамматических систем в виде сравнительных таблиц. Как вы могли увидеть исходя из собранного в этих таблицах материала, родство языков не всегда влечёт за собой их сходство, а сходство вовсе не обязательно означает родство.
Сегодня, как я и обещал, мы начинаем разговор о сравнении слов из лексики разных языков. Это очень обширная тема, и ей будет посвящена не одна статья. В текущем выпуске мы ещё раз поговорим о различии между исконными словами-когнатами и заимствованиями и о том, почему так важно понимать эту разницу при рассуждении о возможном родстве каких-либо языков.
Словарные совпадения и языковое родство (начало)
Большинство из вас, я думаю, знают или хотя бы догадываются, что именно лексические совпадения, то есть совпадения слов (точнее, совпадения корней), являются первейшим и наиболее надёжным признаком родственных отношений между языками. Однако не все, к сожалению, понимают, что лексические соответствия в разных языках – вопрос гораздо более сложный, чем могло бы показаться на первый взгляд: с одной стороны, далеко не любое созвучие слов подтверждает наличие у языков родственных связей, а с другой стороны, нередко случается так, что слова из родственных языков, действительно связанные общим происхождением, оказываются попросту незамеченными непрофессионалами ввиду отсутствия между ними явного, лежащего на поверхности сходства. Достоверное установление языкового родства на основе лексических совпадений требует глубоких и кропотливых исследований, с анализом древних письменных источников, с привлечением данных исторической фонетики, с учётом межкультурных контактов соседних народов и с использованием материалов по целому ряду смежных языков.
Итак, давайте посмотрим, какие подводные камни поджидают того, кто решил испытать свои силы в поиске родственных связей между языками путём сопоставления слов.
Ещё раз о заимствованиях
О принципиальном различии между заимствованиями и когнатами я рассказывал ещё в Статье 2а вводного цикла. Но так как этот вопрос имеет ключевое значение для понимания природы языкового родства, позвольте мне снова к нему вернуться.
Напомню, что заимствованные слова, или просто заимствования, – это такие слова, которые были почерпнуты одним языком из другого.
Причины заимствования слов бывают самыми разными – это могут быть как прямые контакты между народами (чаще всего соседними): культурные, торговые, технические, военные; так и массовое влияние какой-то одной доминирующей культуры на целую группу других (необязательно только на соседние): религиозное, научно-техническое, политическое, общекультурное. В разные исторические эпохи и в разных географических регионах языками таких доминирующих культур становились греческий и латинский (в древней и в средневековой Европе), английский (в современной Европе, да и большей частью во всём современном мире), русский (в Царской России, в республиках бывшего СССР и среди национальных меньшинств Российской Федерации), арабский (среди исламских народов Азии и Африки), санскрит* (в странах Южной и Юго-Восточной Азии), китайский (в странах Восточной Азии) и т. д.
* Примечание. Санскрит – классический литературный язык Индии, см. Статью 2б вводного цикла.
Какова бы ни была конкретная причина заимствования слов, данный процесс никак не зависит от происхождения того или иного языка, то есть от его родословной, а потому наличие в одном языке заимствований из другого ничего нам не может сказать о родственных отношениях между ними: оно их не подтверждает, но в то же время и не исключает.
Иное дело когнаты (см. Статью 2а вводного цикла). Напомню, что когнатами в лингвистике называют слова, существующие в двух или более языках и имеющие общее происхождение, то есть берущие своё начало от единого древнего источника.
В той же Статье 2а вводного цикла был показан схематический рисунок, иллюстрирующий различие между заимствованиями и когнатами. Здесь же я приведу ещё один рисунок на данную тему.
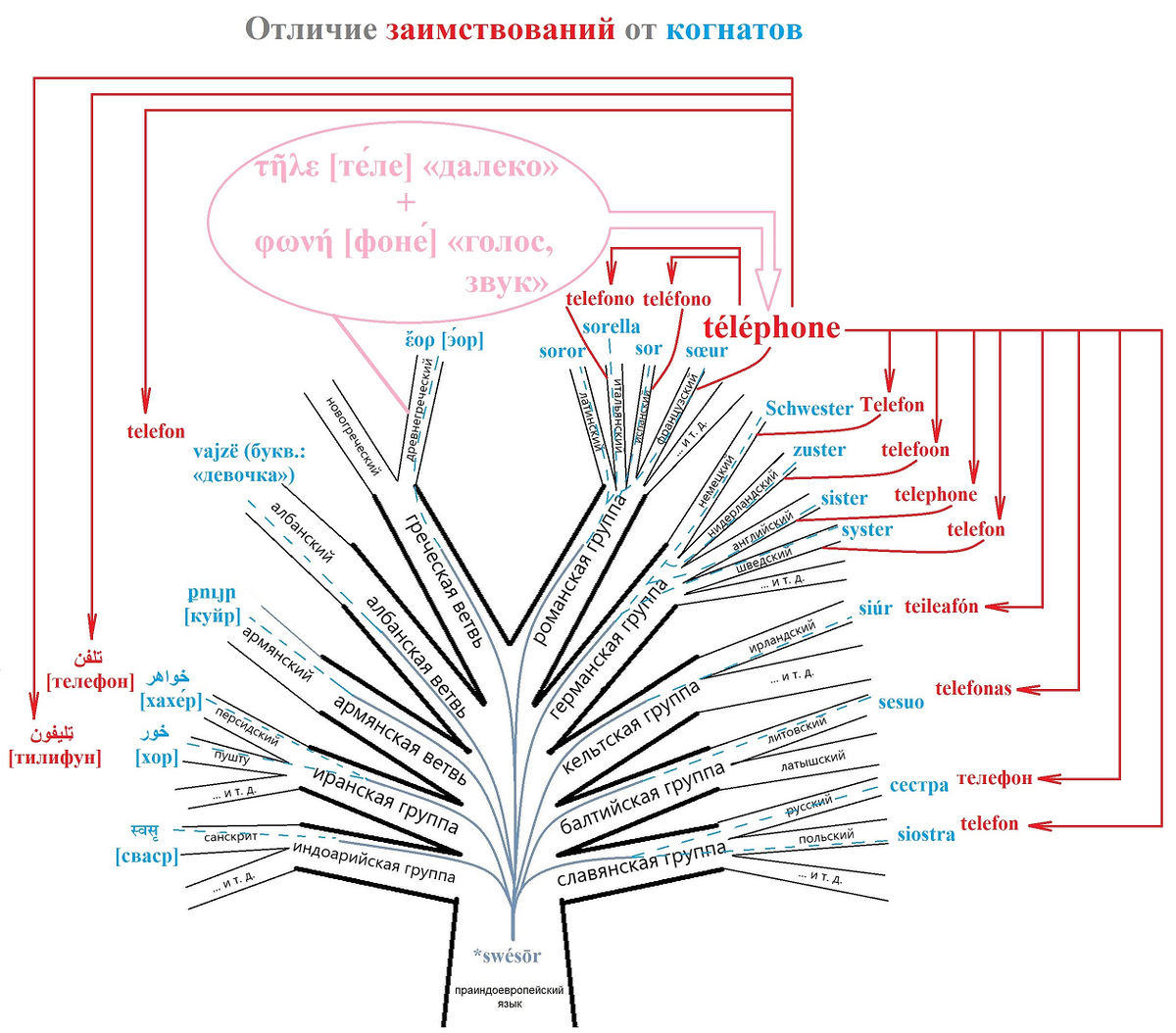
На рисунке выше вы видите упрощённое схематическое изображение генеалогического древа (см. Статью 3а вводного цикла) индоевропейской семьи языков. Чтобы не загромождать рисунок обилием мелких деталей, я лишь выборочно отметил на нём отдельные языки в составе основных десяти ветвей (вымершие языковые группы на рисунке не представлены).
Примечание. Порядок расположения ветвей на схеме никакого значения не имеет: я просто-напросто расставил их так, чтобы удобнее было прорисовать стрелки.
Синим цветом подписано слово «сестра» на некоторых индоевропейских языках: все указанные на рисунке варианты этого слова являются между собой когнатами, так как все они восходят к одному и тому же праиндоевропейскому слову *swésōr, что обозначено на рисунке разветвляющимися кривыми линиями внутри ствола, плавно переходящими в синий пунктир в ветвях. К сожалению, ограниченное пространство рисунка не позволило мне показать на нём промежуточные стадии развития данного слова в различных языковых группах; всё, что вы видите, – это лишь общее слово-источник и несколько его слов-потомков на отдельных современных языках. На деле же в каждой из ветвей индоевропейской семьи слово «сестра» прошло целый ряд звуковых преобразований за многие века и даже тысячелетия своей истории, прежде чем оно приняло знакомый нам сейчас фонетический облик на том или ином языке.
* Примечание. Здесь и далее «звёздочка» перед записью слова из древнего языка-предка означает, что подобная форма в письменных источниках не встречается: это результат лингвистической реконструкции вероятного звучания слова в дописьменную эпоху.
Пусть вас не смущает, что звучание слова «сестра» на некоторых из указанных языков на первый взгляд мало напоминает то, как оно произносится по-русски (таковы, например, древнегреческое ἔορ [э́ор], албанское vajzë, которое к тому же означает «девочка», армянское քույր [куйр], означающее «сестра», персидское خواهر [хахе́р] и слово خور [хор] на языке пушту), – все перечисленные слова всё же являются когнатами, а о причинах их кажущейся непохожести мы поговорим чуть позже, в статье под названием «Ложные и неочевидные когнаты».
Красным цветом подписано слово «телефон» на ряде индоевропейских языков: как нетрудно заметить, все указанные на рисунке варианты этого слова звучат практически идентично или же очень похоже, так как все они по своему происхождению являются заимствованиями. Согласно информации из Викисловаря, данное слово первоначально возникло во французском языке, в котором оно имеет написание téléphone и где оно, в свою очередь, было образовано из древнегреческих корней τῆλε [те́ле] «далеко» и φωνή [фоне́] «голос, звук». Из французского вышеупомянутое слово проникло во многие другие языки, порой – непосредственно, а порой – через посредничество третьих языков, что, однако, не меняет общей картины, – на схеме направления заимствований условно обозначены прямыми красными линиями со стрелками на конце.
Примечание 1. Красные искривлённые линии без стрелок служат исключительно для того, чтобы показать, к какому именно языку относится тот или иной вариант слова, – я использовал их во избежание путаницы там, где на рисунке несколько языков оказались скученными на малом расстоянии друг от друга.
Примечание 2. Хотя на рисунке вы видите одну только индоевропейскую семью языков, в реальности слово téléphone просочилось далеко за её пределы: так, например, на иврит оно переводится как טלפון [те́лефон], на турецкий и на венгерский – как telefon, на африканский язык йоруба, распространённый главным образом в Нигерии, – как tẹlifoonu, на индонезийский – как telepon (звук [f] несвойственен индонезийскому языку, хотя в отдельных заимствованиях он всё же встречается), а на гавайский – как kelepona (в гавайском языке нет также и согласного [t]).
Как видно из примеров, наличие в каком-либо языке слова «телефон» с более или менее похожим звучанием вовсе не является показателем того, что данный язык родственен русскому (равно как и греческому, французскому, английскому и т. д.): с большой долей уверенности можно утверждать, что подобное созвучие есть результат банального заимствования. Отсюда вытекает первая заповедь лингвиста, ищущего родственные связи между языками: любые заимствования при установлении языкового родства должны быть беспощадно отсеяны – исследователь должен сосредоточиться исключительно на исконном материале каждого из рассматриваемых им языков.
Те из читателей, кто хотя бы немного подкован в языкознании, могут, наверное, подумать, что придерживаться указанной заповеди нетрудно, ведь заимствования, если судить о них по известным нам примерам из русского языка, как правило, «видно за версту». И действительно, кто не знает, что такие слова, как телефон, температура, климат, принтер, компьютер, менеджер, ньюсмейкер, астероид, фотон, электрон, гравитация, субсидия, элегантный, галантный, активировать и т. п., являются в русском языке заимствованиями? Следует просто исключить подобные слова из анализа – и дело в шляпе!
В реальности с этим не всё так просто. Сложности начинаются тогда, когда мы имеем дело со старыми заимствованиями, усвоенными сотни и даже тысячи лет назад и прочно закрепившимися в языке. Такие слова обычно воспринимаются носителями как родные, и этому дополнительно способствует то, что за длительную историю «службы» подобных слов в заимствующем языке их звуковой облик зачастую претерпевает существенные изменения, подстраиваясь под звуковую систему своего нового «языка-хозяина», в результате чего такого рода заимствования уже ничем в наше время не выделяются на фоне собственных, исконных слов данного языка. А потому невозможно со стопроцентной надёжностью отделить исконные слова от заимствований, полагаясь на одну только интуицию, – часто для этого требуется полноценное исследование специалистов. Как правило, оно включает в себя сопоставление сохранившихся письменных материалов на разных языках и из разных эпох, также берутся в расчёт и различные принципы звуковых преобразований, на основе которых в ту или иную эпоху менялось звучание слов в каждом из рассматриваемых языков. Совокупность всех этих данных позволяет установить, в каком приблизительно веке искомое слово впервые появилось в интересующем нас языке и откуда оно туда пришло.
Чтобы не быть голословным, приведу несколько примеров подобного рода старых заимствований в русском языке – многие из вас наверняка даже не подозревают о том, что все эти слова не исконные:
- огурец – из византийского греческого ἀγγούριον [ангу́рион], буквально «огурчик», – это слово пришло к нам в Средние века;
- свёкла – из древнегреческого σεῦκλον [сэ́уклон];
- хлеб – из древнегерманского *hlaib, – очень старое заимствование (сравните: древнеанглийское hlāf, древневерхненемецкое hleib, готское 𐌷𐌻𐌰𐌹𐍆𐍃 = hlaifs);
- известь – из древнегреческого ἄσβεστος [а́збестос] (в византийском произношении – [а́звестос]) «неугасимый, вечный, неразрушимый», – это слово известно в новгородских летописях с XII века; интересно, что более позднее заимствование асбест, которое пришло к нам через немецкий, того же самого происхождения;
- изъян – из персидского زیان зиян «вред», что позже было переосмыслено как производное от глагола «изъять»;
- чулок – заимствовано из тюркских языков в период Золотой Орды, сравните: киргизское чулга «обматывать, завёртывать», татарское чолчак «портянки»;
- жесть (и его производные: жёсткий, жестокий) – предположительно, заимствовано из тюркских языков в период Золотой Орды, сравните: казахское, киргизское, карачаево-балкарское жез «медь»;
- лошадь – старое заимствование из тюркских языков, сравните: татарское и казахское алаша, чувашское лаша, – исконным славянским названием данного животного является слово конь, сравните: украинское кінь, белорусское конь, польское koń [конь], чешское kůň [кунь], болгарское кон и т. д.;
- собака – предположительно, из среднеперсидского, сравните: сабах на зороастрийском дари, spā́kəʰ на мидийском, спака «собакоподобный» на авестийском, – исконным славянским названием данного животного является слово пёс, сравните: польское pies [пес], чешское pes [пэс], сербское пас, словенское pes [пэс] и т. д.;
- кот (и его производное – кошка) – происхождение данного слова до сих пор вызывает споры: согласно традиционной версии, праславянское *kotъ, так же как и прагерманское *kattuz, были заимствованы из позднелатинского cattus (350 г. н. э.), восходящего к латинскому catta (75 г. н. э.), которое, в свою очередь, пришло из афроазиатских языков (к ним, в частности, относится и древнеегипетский), – указанная цепочка воспроизводит путь распространения домашних кошек с Ближнего Востока в Европу через Грецию и Италию, в особенности после того, как кошки приобрели популярность в Египте.
Данный список, конечно же, далеко не полный: в него включена лишь мизерная доля от всех широкоупотребительных старых заимствований, успешно маскирующихся под исконные русские слова. Но и этого списка вполне достаточно, чтобы у вас сложилось общее понимание, насколько бывает легко обмануться неспециалисту в вопросе о происхождении того или иного слова.
И раз уж представился такой подходящий случай, позвольте мне им сейчас воспользоваться для исправления одной старой ошибки, что я допустил в Статье 2а вводного цикла. Если вы следили за всеми моими публикациями, то вы, должно быть, ещё помните, что в упомянутой статье я проводил сопоставление английского и русского текстов на предмет наличия в них когнатов. Тогда в числе общеиндоевропейских когнатов я среди прочих назвал английское слово cat и русское кот. Один из моих читателей впоследствии указал мне на данную ошибку, справедливо заметив, что означенные слова являются не когнатами, а общими заимствованиями, вошедшими в языки Европы из неиндоевропейского источника. Итак, пусть и с некоторым запозданием, но я всё же приношу свои извинения за введение вас в заблуждение по поводу происхождения «кота»: как видите, не будучи профессиональным учёным-лингвистом, я тоже разок попался на старом заимствовании.
Наученный этим промахом, я всё же извлёк из него урок и при написании своей предыдущей статьи (см. Статью 3б2 текущего цикла) решил обратиться к специалистам с просьбой прокомментировать явное созвучие слов на двух заведомо неродственных языках. В той самой статье, а именно в подглаве «Порядок слов», я переводил на разные языки предложение «Брат читает книгу» и, к своему удивлению, обнаружил, что глагол «читать» звучит практически одинаково на тайском и на кхмерском: ан. Заметим, что в обоих языках гласный [а] в этом слове долгий, только в тайском он произносится низким тоном, а кхмерский язык нетональный, и, следовательно, тон в нём вообще неважен. Почему меня это удивило? Потому что указанные языки принадлежат к совершенно разным языковым семьям: тайский – к тай-кадайской семье, а кхмерский – к австроазиатской; отсюда понятно, что никаких когнатов между ними существовать не может.
Выходит, что в случае с глаголом «читать» мы имеем дело либо со случайным совпадением (такое тоже возможно, и об этом я ещё расскажу), либо – что более вероятно – с заимствованием. Вообще говоря, мне известно о том, что в тайском языке есть заимствования из кхмерского, но в основном это слова, относящиеся к придворной (королевской) лексике, а вот чтобы такой, казалось бы, повседневный глагол, как «читать», был заимствован из того же источника, мне представлялось маловероятным. Кроме того, и в тайском, и в кхмерском есть ещё большое количество общих заимствований из классических языков Индии (из санскрита и пали), однако такие слова, как правило, многосложные и нередко довольно длинные и насыщенные согласными, тогда как краткое односложное ан на них явно не тянет – оно скорее похоже на исконную лексику языков Юго-Восточной Азии.
Тогда я отправился со своим вопросом на англоязычный сайт Quora. Этот ресурс мне нравится, в частности, тем, что он предоставляет возможность задавать вопросы из любых областей знаний (равно как и вопросы житейского характера) и запрашивать при этом ответы у конкретных пользователей из предлагаемого системой списка, в котором указан детальный профиль участников (страна, образование, учёная степень, специальность, род занятий, жизненный опыт и т. д.). Запросив ответ у ряда лингвистов, специализирующихся на языках Юго-Восточной Азии, я получил разъяснение от доктора наук по лингвистике из Корнеллского университета о том, что тайский глагол อ่าน а̀н «читать» действительно был заимствован из кхмерского អាន ан «читать» в период Ангкора (это период расцвета Кхмерской империи, когда Ангкор был её столицей), то есть где-то между IX и XV веками.
Данный пример ещё раз подтверждает: прежде чем воскликнуть «Ура! Я нашёл когнаты – значит, эти языки родственные», стоит проверить, не имеем ли мы здесь дело с заимствованиями.
__________________________________________________________________________________________
Итак, наличие в двух разных языках похожих по звучанию слов с совпадающими значениями ещё не является достаточным доказательством родства данных языков: в первую очередь необходимо проверить, не заимствованы ли эти слова одним языком из другого либо обоими языками из какого-то третьего. Однако отличить исконные слова-когнаты от заимствований не всегда бывает так просто, как можно было бы поначалу подумать. Тем не менее профессиональные лингвисты, ведущие поиск родственных связей между языками, просто обязаны отличать одно от другого, ведь родство языков устанавливается исключительно на основе когнатов, а на основе заимствований никакого вывода о родстве сделать нельзя.
На сегодня всё, ну а в следующей статье мы продолжим наш разговор о заимствованиях: я расскажу о таких языках, в которых заимствований из какого-то одного конкретного источника больше, чем собственных исконных слов, и объясню, почему даже в этом случае подобные языки остаются неродственными своему основному поставщику заимствований.
Спасибо, что вы были со мной. Оставайтесь на связи! Всем всего наилучшего и до новых встреч!
Ссылки на следующие статьи:
- Природа языкового родства, статья 4б. Слова словам рознь – когда чужого больше, чем своего;
- Природа языкового родства, статья 5б-1. Знакомьтесь: неочевидные когнаты. Часть первая: дай пять!
- Природа языкового родства, статья 5б-2. Знакомьтесь: неочевидные когнаты. Часть вторая: жизнь не перестаёт удивлять;
- Природа языкового родства, статья 5б-3. Неочевидные когнаты: порядок среди хаоса. О соответствиях между звуками;
- Природа языкового родства, статья 5б-4. Неочевидные когнаты: время меняет всё. О законах звуковых изменений;
- Природа языкового родства, статья 6а. Народы и языки: родство по крови против родства по слову;
- Природа языкового родства, статья 6б. Народы и языки: о спорах бессмысленных и беспощадных.
Ссылка на следующий цикл статей
- Третий цикл. Мифы и заблуждения: география родственных языков.
География родственных языков, статья 1а. Общегеографические заблуждения: языки Европы
(ссылки на остальные статьи цикла смотрите внутри Статьи 1).