
Все статьи серии "Метрики в 1С ERP":
Серия статей написана для разъяснения:
- Результатов стресс-теста ООО "Производственное предприятие": Метрики KPI - Финансовых показателей - Мастер-бюджетов
Статья 7: Тревожные сигналы: когда бить в колокола?
Вы построили систему KPI, автоматизировали сбор данных, создали красивые дашборды. Но теперь перед вами новый вызов: как понять, какое отклонение — нормальная волатильность, а какое — сигнал к немедленным действиям? Как не превратиться в паникера, который собирает совещание из-за каждого процента, и не проспать настоящую катастрофу?
Сегодня мы разберём, как создать систему раннего предупреждения, которая отделяет шум от сигналов и точно подсказывает, когда нужно бить в колокола.
Ошибка №1: Реагировать на всё подряд
Представьте себе врача, который при каждом чихе пациента назначает антибиотики. Через месяц у пациента нет иммунитета, зато есть резистентность к лекарствам. Примерно так же руководители, реагирующие на каждое отклонение KPI:
- Понедельник: Конверсия упала на 2% → срочное совещание с отделом продаж
- Вторник: Время отгрузки увеличилось на 1 час → разбор полётов с логистами
- Среда: Брак вырос на 0,3% → внеплановая проверка производства
Результат:
- Сотрудники в постоянном стрессе
- Руководитель тонет в операционке
- Настоящие проблемы остаются незамеченными
Три уровня сигналов: зелёный, жёлтый, красный
Вернёмся к нашему производственному предприятию. Вот как у них настроена система оповещений:
Уровень 1: Зелёный (норма, мониторинг)
- Отклонение: до 5% от плана или в пределах статистической погрешности
- Действия: Никаких. Это нормальная волатильность бизнеса.
- Пример: Конверсия 94% при плане 95%
Уровень 2: Жёлтый (внимание, анализ)
- Отклонение: 5-10% от плана или выход за допустимый коридор
- Действия: Анализ причин, корректировка в рабочем порядке
- Пример: Брак 1,8% при плане 1,5%
Уровень 3: Красный (тревога, немедленные действия)
- Отклонение: более 10% от плана или критическое нарушение процесса
- Действия: Внеочередное совещание, экстренные меры
- Пример: Кассовый разрыв, срыв крупного заказа, массовый брак
Как отличить случайное отклонение от системной проблемы?
Правило трёх сигм
В статистике есть простое правило: если показатель выходит за пределы трёх стандартных отклонений от среднего — это не случайность.
Пример:
- Средний процент брака за год: 1,5%
- Стандартное отклонение: 0,2%
- Нормальный диапазон: 1,5% ± 0,6% = от 0,9% до 2,1%
- Тревога: Если брак превышает 2,1%
Анализ трендов
Одноразовое отклонение — не проблема. Системная — когда показатель меняет тренд.
Как анализировать:
- Взгляд назад: Как показатель вел себя последние 30 дней?
- Сравнение: Отклонение только у нас или у всех в отрасли?
- Причинность: Есть ли объяснимые причины (сезонность, праздники)?
Пример из практики:
Ситуация: Конверсия упала на 8% в понедельник.
Анализ:
1. Последние 30 дней: Конверсия стабильно 94-96%
2. В прошлом году в этот день: Конверсия 93% (был праздник в регионе)
3. У конкурентов: Аналогичное падение на 5-10%
Вывод: Сезонное явление, не требует вмешательства.
Пороговые значения для ключевых KPI
Вот какие пороги установило наше производственное предприятие:
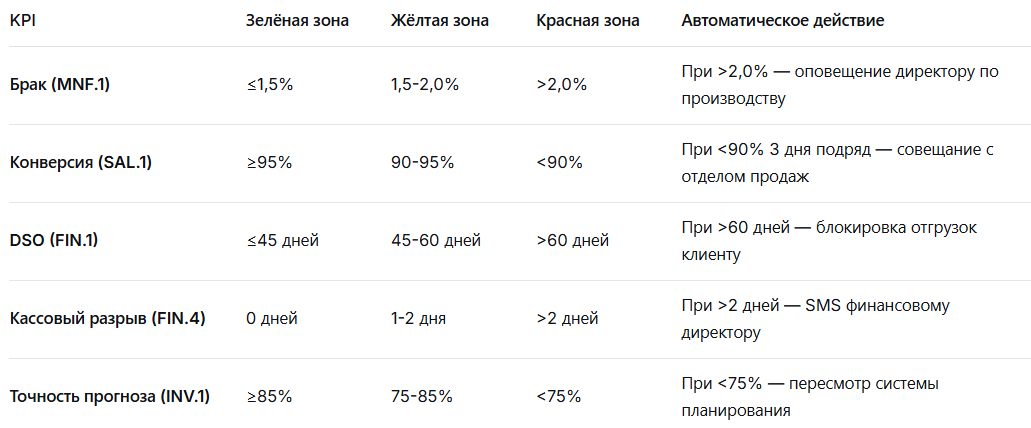
Кейс: как система раннего предупреждения спасла компанию от кризиса
Ситуация: Компания "МебельПро" заметила рост брака с 1,5% до 1,7%. По отдельности — не критично. Но система выдала жёлтый сигнал, потому что:
- Совокупность факторов:
Брак вырос на 0,2%
Выход годного упал на 1%
Время цикла увеличилось на 5% - Анализ тренда:
Брак растёт третий день подряд
Тренд указывает на достижение 2% через неделю - Финансовый прогноз:
При текущем тренде потери составят 500 тыс. рублей в неделю
Риск срыва крупного заказа на 5 млн рублей
Действия:
- День 1: Система отправила уведомление начальнику производства
- День 2: Проведён экспресс-анализ — найдена проблема с новым поставщиком фурнитуры
- День 3: Закуплен материал у старого поставщика, брак стабилизировался
- День 5: Показатели вернулись в зелёную зону
Результат: Предотвращены потери на 2,5 млн рублей, сохранён клиент.
Инструменты для создания системы раннего предупреждения
1. Business Intelligence системы (Power BI, Tableau)
- Что делают: Автоматически отслеживают KPI, строят тренды, визуализируют отклонения
- Пример: В Power BI настраиваются "линии тренда" и "предсказательные модели"
2. RPA-боты с элементами ИИ
- Что делают: Не просто собирают данные, но и анализируют их, отправляют оповещения
- Пример: Бот, который каждые 4 часа проверяет ключевые KPI и при отклонениях формирует отчёт с анализом причин
3. Специализированные системы мониторинга (адаптированные для бизнеса)
- Что делают: Мониторят бизнес-процессы как IT-системы
- Пример: Дашборд, где каждый KPI — как датчик температуры сервера
4. Простые решения на Google Sheets/Excel
- Что делают: Условное форматирование + формулы + уведомления
- Пример:
=ЕСЛИ(B2>2%; "🔴 КРИТИЧЕСКОЕ ОТКЛОНЕНИЕ";
=ЕСЛИ(B2>1,5%; "🟡 ВНИМАНИЕ";
"🟢 НОРМА"))
Чек-лист: настройка системы раннего предупреждения
Этап 1: Определение критических KPI
- Выбрали 5-7 самых важных показателей для бизнеса
- Определили, как их измерять
- Установили нормальные значения
Этап 2: Установка порогов
- Для каждого KPI определили зелёную, жёлтую и красную зоны
- Учли сезонность и отраслевую специфику
- Проверили пороги на исторических данных
Этап 3: Настройка оповещений
- Определили, кто получает оповещения
- Установили каналы (email, SMS, Telegram, Teams)
- Настроили частоту проверок
Этап 4: Создание регламентов действий
- Для каждого типа сигнала прописали действия
- Определили сроки реагирования
- Назначили ответственных
Этап 5: Тестирование и корректировка
- Протестировали на исторических кризисах
- Скорректировали пороги по результатам тестов
- Обучили команду
Как реагировать на сигналы: алгоритм для руководителя
Шаг 1: Оценка срочности
Вопросы:
1. Насколько критично отклонение? (финансовый эффект)
2. Как быстро проблема будет развиваться?
3. Есть ли угроза клиентам/репутации?
Шаг 2: Анализ причин
Инструменты:
1. "5 почему" — метод поиска корневой причины
2. Диаграмма Исикавы — визуализация всех возможных причин
3. Анализ временных рядов — было ли такое раньше?
Шаг 3: Принятие решения
Варианты:
1. Ничего не делать (если случайное отклонение)
2. Корректирующие действия (если системная ошибка)
3. Изменение процесса (если проблема повторяется)
Шаг 4: Контроль выполнения
Метрики контроля:
1. Время реагирования (от сигнала до действий)
2. Эффективность действий (возврат KPI в норму)
3. Стоимость решения (не должно превышать стоимость проблемы)
Ошибки, которые сведут систему к нулю
1. Слишком чувствительные настройки
- Симптом: Оповещения приходят каждый час
- Лечение: Увеличить пороги, учитывать статистическую погрешность
2. Игнорирование сигналов
- Симптом: Руководитель отключает уведомления
- Лечение: Внедрить обязательные отчёты о реакции на сигналы
3. Отсутствие регламентов
- Симптом: Приходит оповещение, но никто не знает, что делать
- Лечение: Для каждого типа сигнала — чёткий план действий
4. Фокус только на красных сигналах
- Симптом: Жёлтые сигналы игнорируются, пока не станут красными
- Лечение: Ввести KPI по количеству жёлтых сигналов и скорости их устранения
Практическое задание: создайте систему для своего отдела
Задание на неделю:
День 1-2: Выберите 3 ключевых KPI для вашего отдела
День 3-4: Установите пороговые значения на основе исторических данных
День 5: Настройте простую систему оповещений в Google Sheets:
- Создайте таблицу с KPI
- Добавьте формулы для определения статуса
- Настройте уведомления по email
Пример для отдела продаж:
KPI: Конверсия звонков в заявки
Норма: 20%
Жёлтая зона: 15-20%
Красная зона: <15%
Формула в Google Sheets:
=ЕСЛИ(B2<0,15; "🔴 СРОЧНО ВМЕШАТЬСЯ";
=ЕСЛИ(B2<0,2; "🟡 ТРЕБУЕТ ВНИМАНИЯ";
"🟢 НОРМА"))
Уведомление: При статусе 🔴 — письмо руководителю отдела.
Тест: насколько ваша компания готова к кризисам?
Ответьте на вопросы (да/нет):
- У вас есть список ключевых KPI с чёткими целевыми значениями?
- Вы знаете, какое отклонение каждого KPI считается критическим?
- Есть автоматическая система оповещений при отклонениях?
- Прописаны регламенты действий для каждого типа сигнала?
- Команда знает, что делать при получении тревожного сигнала?
- Вы анализируете не только фактические значения, но и тренды?
- Система учитывает сезонность и отраслевые особенности?
- Вы регулярно тестируете систему на исторических данных?
- Есть ответственность за ложные срабатывания?
- Система постоянно улучшается на основе обратной связи?
Результаты:
- 8-10 "да": Вы хорошо защищены от неожиданностей
- 5-7 "да": Есть риски, нужны улучшения
- 0-4 "да": Вы управляете бизнесом вслепую
Эволюция системы: от реактивной к предиктивной
Поколение 1: Реактивное (что случилось?)
- Принцип: Фиксируем отклонение, когда оно уже произошло
- Пример: "Брак сегодня 2,1% — превышение на 0,6%"
Поколение 2: Проактивное (почему случилось?)
- Принцип: Анализируем причины отклонений
- Пример: "Брак вырос из-за нового поставщика фурнитуры"
Поколение 3: Предиктивное (что случится?)
- Принцип: Предсказываем отклонения до их возникновения
- Пример: "На основе данных о поставщике прогнозируем рост брака до 2,3% через 3 дня"
Поколение 4: Пресциптивное (что делать?)
- Принцип: Система сама предлагает оптимальные действия
- Пример: "Рекомендуем вернуться к старому поставщику, это предотвратит потери на 500 тыс. рублей"
Вывод
Система раннего предупреждения — это не роскошь, а необходимость в современном бизнесе. Она позволяет перейти от управления "по факту" (когда проблемы уже нанесли ущерб) к управлению "по прогнозу" (когда проблемы предотвращаются на подлёте).
Но даже самая совершенная система обнаружения проблем бесполезна без эффективных корректирующих мероприятий. В следующей статье мы разберём, как не просто находить проблемы, а решать их системно — от разработки мероприятий до контроля их выполнения.
Примеры в статье основаны на реальном опыте внедрения систем раннего предупреждения в производственных компаниях, где это позволило сократить финансовые потери от операционных сбоев на 40% за первый год.