
Попробуем разобраться в том, как писать асинхронный код на Python и как работать с IO-задачами с помощью модуля acyncio, aiohttp.
Задание 1. Удаление запрещённой библиотеки
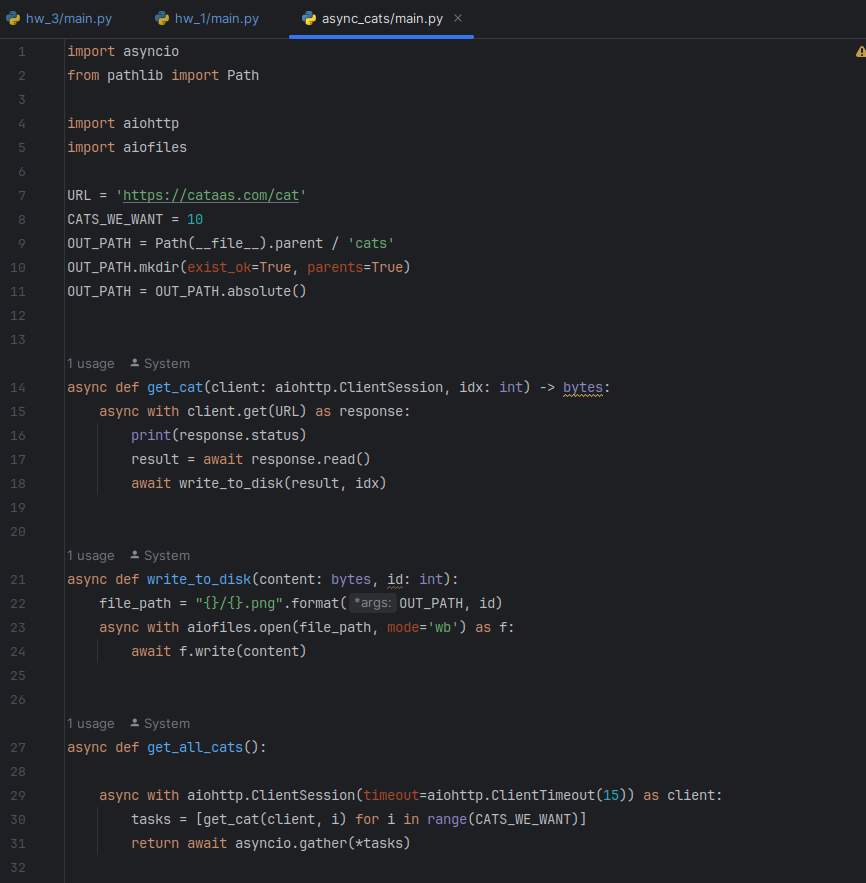
Итак, в данном задании нужно переделать код из лекций (скачивание изображение котиков), написанный под библиотеку aiofiles, чтобы асинхронность работы сохранялась а сохранение файла на жесткий диск осуществлялось при помощи стандартной функции open.
С помощью документации можно разобраться как это работает...
Проблема в данном задании и как следствие - следующем - это неработающий сайт, с которого мы должны скачать "котиков". Или может быть иногда неработающий, или только у меня не работающий... Но я нашел нечто похожее для этой цели:
Итак, вроде бы "котики" грузятся с помощью скрипта указанного выше (изменен только сайт и немного подправлен метод того как это происходит), можно переделать код под использование стандартной функции open().
Иногда при скачивании котиков возникают ошибки (видимо некоторые ссылки бывают пустые и выдают значение типа None), их я обработал с помощью try-except.
Собственно говоря код не сильно изменился от начального:
Плюс добавил измерение скорости работы функции скачивания котиков, которая нужна для отчета во втором задании.
Задание 2. Реализация на тредах и процессах
- Напишите реализацию котиков на тредах и процессах, также возьмите уже готовую реализацию на корутинах.
- Измерьте время работы каждого из подходов на 10/50/100 картинках. Измерьте прочие метрики и оформите результаты в виде Markdown-таблицы.
- Не забудьте проверить время работы вашей реализации записи в файл из прошлого задания. Время работы не должно существенно отличаться от реализации на aiofiles.
В данном задании реализация была такой: отдельный файл для скачивания котиков на тредах, отдельный на процессах, и отдельный на корутинах и объединяет все их главный файл main.py, который запускает эти скрипты и сохранение котиков происходит в разные директории. Выглядит это так:
Ну и соответственно скрипты по-порядку, thread_cats.py:
multiprocessing_cats.py:
Хотя смысла большого выкладывать код на корутинах нет смысла, я всё же его выложу, потому как есть небольшие нюансы его запуска. coroutine_cats.py:
Ну и главный (main.py) файл, который запускает по очереди все эти скрипты и затем выдает таблицу с отчетом в формате MarkDown:
Все скрипты выполняются довольно таки много времени, при использовании примера с корутинами даже возникла ошибка таймаута и пришлось увеличить время таймаута. Библиотека markdown_table сформировала вот такой отчет:
В конце которого я добавил измерения из первого задания.
Задание 3. Реализация интернет-краулера
В этом задании мы реализуем классическое приложение для асинхронных задач — интернет-краулер.
Принцип его работы таков: на вход краулеру даётся ссылка или ссылки. Далее он запрашивает контент этих страниц, парсит их, достаёт оттуда все доступные ссылки и идёт по ним. Иначе говоря, он работает рекурсивно. Нас будут интересовать только ссылки на внешние ресурсы.
Приложение необходимо реализовать с помощью модуля aiohttp, используя асинхронный Python. Сделайте так, чтобы количество итераций можно было сконфигурировать (по умолчанию пусть это будет 3).
Все ссылки, которые краулер найдёт по ходу работы, необходимо записать в файл.
Все довольно таки просто когда у тебя только одна ссылка на сайт, в котором ты хочешь покопаться, а когда сайт выдает несколько ссылок на другие сайты, а те в свою очередь еще на сколько то, тогда эта задача не кажется простой. Плюс ко всему на многих сайтах имеется защита, которая реагирует на DDOS-атаки, а подобная программа может быть вредоносной. Ну и когда количество ссылок растет в геометрической прогрессии, возникает куча различных ошибок, на которые приходилось реагировать.
Эта программа чем то похожа на "котиков", описанных выше или в лекциях, я взял за основу версию с использованием aiofiles.
Начинаем с того что определяем стартовый сайт, в эту же переменную будут записываться и найденные ссылки на другие сайты, я использовал set(), а не список чтобы все ссылки в данной переменной были разные. А так же глубину сканирования:
Вызываем наш краулер:
Дополнительно прописывал настройки соединения, чтобы защитные программы сканируемых сайтов не обрывали соединение, увеличил таймаут сессии. Пока в переменной tasks только одна задача с одним адресом, но когда программа просканирует этот адрес у нас появятся много других адресов, которые добавятся в переменную URL и будут рекурсивно вызваны далее:
с каждой итерацией, глубина сканирования будет уменьшаться, пока полностью цикл задач не отработает все полученные адреса сайтов.
Вот так у меня отработала программа...
Вот пожалуй и всё.
Мою работу за истину не воспринимайте, возможно ваш куратор думает иначе, а мне как старому пер..ну делают поблажки... Типа пущай закончит этот курс и валит с нашей платформы...