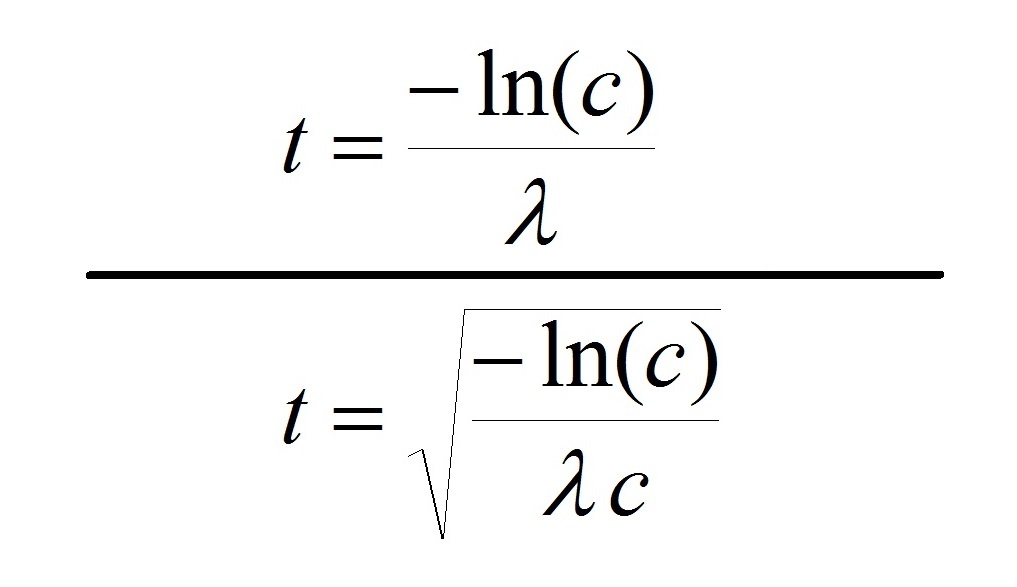
Данная статья в продолжение популярной статьи об основах глоттохронологии - науки, позволяющей лингвистам оценивать времена расхождения языков и строить лингвогенетические древа (дендрограмы), наглядно отображающие рождение и смерть языков в виде графических схем.
Все необходимые вычисления производятся по формулам глоттохронологии, устанавливающим соответствие между степенью совпадения 2 языков и временами их расхождения (как, например некогда разошлись предки славянских и романских языков 4900 лет назад), либо отделения одного языка от другого (предка английского языка от группы средневековых германских языков в 5 веке н.э.).
На заре глоттохронологии, в 1950-х годах, лингвисты пользовались наиболее простой формулой, предложенной основателем глоттохронологии английским лингвистом Моррисом Сводешом (верхняя формула на титульной картинке).
В дальнейшем, после ряда критических замечаний, как справедливых, так и нет, появились модификации формулы. Одни из самых известных модификаций - формула выдающегося советского и российского лингвиста Сергей Старостина (нижняя формула на титульной картинке).

Изменения здесь, если судить зрительно - в знаменателе формулы появляется член c, а из общего выражения извлекается квадратный корень.
Разберем эффект этих нововведений, их целесообразность и возникшие вследствие этого парадоксы, мешающие принять формулу. Сразу оговоримся, что соответствие расчетов по формуле практическим данным никогда не является достоинством формулы само по себе - все старые и новые вводимые в формулы переменные должны иметь лингвистический смысл, а результаты вычислений не должны приводить к парадоксам.
В обоих формулах c - коэффициент совпадения слов в списках основной (базовой) лексики 2 сравниваемых в одно время языков (например, современного русского и македонского) либо 2 разделенных временем состояний языка (древнеанглийского и современного английского).
Коэффициент совпадения подсчитывают лингвисты-компаративисты путем сличения предварительно составленных списков базовой лексики с целью выявления числа совпадений (т.е. подвергшихся замене) слов. Слова заменяются как в процессе естественного развития языка, так и в результате заимствования слов чужого языка в результате языковых контактов с соседями, с завоеванными племенами либо с завоевателями.
Показатель λ в формуле Сводеша - это т.н. скорость изменения языка, которую Сводеш полагал неизменной для всех времен и языков. Именно это положение подверглось сомнению в первую очередь. Здесь начинается ряд недоразумений, породив миф о многократном уменьшении скорости изменения лексики "по Старостину" в сравнении со скоростью "по Сводешу". Сводешевское значение 0,14 Старостин предложил заменить значением 0,05. Если бы значение изменилось на 5-10%, это было бы объяснимо и понятно. Сам Сводеш на основании ряда оценок, своих собственных и коллег, в 1950-е годы оценивал значение λ в пределах от 0,16 до 0,27, и эти значения согласовывались с практикой. Обычно же значение λ принималось равным 0,14.
Ошибиться почти в 3 раза в оценке скорости изменения ни коллеги Сводеша, ни Старостин не могли, здесь явно крылось нечто иное. Суть в том, что λ в формулах Сводеша и Старостина - это совершенно разные понятия, по недоразумению обозначаемые одним символом.
В формуле Сводеша λ - скорость изменения языка, а в формуле Старостина - его ускорение. Из физики известно, что при начальной нулевой скорости скорость равна произведению ускорения на время, и в формуле Старостина λ и является ускорением. Такая вот досадная неразборчивость в выборе обозначений.
Время в лингвистике обратно пропорционально скорости (в формуле Сводеша числитель аналог расстояния, и как и в физике расстояние делится на скорость, чтобы узнать время), и обратно пропорционально корню квадратному из ускорения.
Поскольку λ в формуле Сводеша ускорение, из знаменателя формулы Старостина извлечен квадратный корень, вот и вся разгадка. Корень из принятого значения λ=0,05 равен 0,224, что в пределах интервала значений, оцененных Сводешем, тем самым никакого особого значения скорости Старостин не вводил.
Но данный этап разработки формулы явился промежуточным, показатель λ по-прежнему считался скоростью и полагался равным 0,05. Далее Старостин сделал предположение о непостоянстве скорости изменения лексики и об увеличении ее с ростом времени на основе "старения" слов, что потребовало перехода от модели равномерного развития лексики к модели ее равномерно-ускоренного движения (что и потребовало введения λ как показателя ускорения). Подобная возможность была предусмотрена в работе 1974 года советских исследователей М.В. Арапова и М.М. Херц).
С учетом того, что формула равномерно-ускоренного движения удовлетворительно датировала близкие события, но многократно удревняла события далеких эпох, что не согласовывалось с письменными источниками и археологическими данными (датировавшимися в основном радиоуглеродным методом), было решено ужать шкалу времени путем извлечения квадратного корня.
Здесь все тоже явно - если по расчету получалось 1 тысячелетие, значение оставалось без изменения, а вот 9 тысячелетий умолаживались до √9=3 тысячелетий.
Когда было обнаружено, что извлечение корня приводит к перекомпенсации, т.е. "ужатие" оказывается чрезмерным, и при малых коэффициентах совпадения результаты применения формулы Старостина оказываются хуже, чем формулы Сводеша, в знаменателе формулы значение λ=0,05 было предложено умножать на коэффициент совпадения c.
Поскольку для ближнего времени коэффициент совпадения близок к 1, умножение на с не сказывается на ближних датировках, но удревняет далекие. В таком окончательном виде формула была обнародована в 1989 году, снабжена необходимыми пояснениями и предложена к использованию. Сам Старостин на основе своей формулы построил ряд дендрограмм, в частности, индоевропейских языков.
Остается рассмотреть формулу подробнее. Введение в знаменатель c обосновывается тем, что слова основного списка имеют разную вероятность выпадения - сначала выпадают менее устойчивые, затем более устойчивые. Эта закономерность была отмечена Сводешем, давшим для 2 вариантов своего списка основной лексики разные значения коэффициента сохранности за 1000 лет: 0,86 для 100-словного списка и 0,81 для 200-словного.
Очень грубо можно считать, что 100-словный список - это первая половина 200-словного и содержит более устойчивые слова. 0,81 доля от 200 слов - это 162 слова. Итого, из первой сотни слов сохраняется 86 слов, а из второй 162-86=76. Разницу между разной сохранностью разных частей списка автор формулы решил учесть введением коэффициента c в знаменатель формулы.
В итоге, сравнение формулы Сводеша при λ=0,141 и формулы Старостина при λ=0,05 позволяет построить нижеследующий график зависимости между датировками по Сводешу и Старостину.
Видно, что после введения в новую формулу 2 новых переменных (c в знаменателе и извлечение квадратного корня) результаты вычислений фатально не изменили. В районе глубины времени порядка 6-7 тысяч лет (времена расхождения 3000-3500 лет) данные почти совпадают, на малых и больших временах датировки по Старостину удревняются.
К этому, впрочем, одно замечание - коллеги Сводеша на заре глоттохронологии и Старостин пользовались разными методами сличения списков. У Сводеша учитывались все замены слов, у Старостина учитывались лишь замены без учета заимствований. Сам же учет заимствований требовал их выявления, что оказывается более трудоемкой и связанной с погрешностями работой, чем простой подсчет числа выживших слов.
Но ряд языков в своем развитии обходился практически без заимствований или малом их числе (например, итальянский или македонский языки, или непальский на основе хинди мало заимствовал чужие слова); другие же, как например пиджины или креольские языки, заимствованиями буквально нашпигованы.
Один из языков с огромным числом заимствований - цыганский язык, до ухода цыган с Индостана близкий к центральному языку индоарийской языковой группы (хинди на основе пракритов - народных диалектов литературного санскрита). Заимствования языки цыган обрели за время миграции народа.
Оттого "по Старостину" коэффициент сохранности лексики одной и той же пары языков больше, чем "по Сводешу". В качестве примера - совпадения персидского и русского языков на 28% при сравнении списков Старостина и 15,6% списков, составленных коллективом автором Дайен, Крускал, Блэк.
Все бы ничего, но нас ждет еще одна неожиданность при исследовании формулы Старостина. Из формулы Сводеша можно вывести значения λ в зависимости от коэффициента совпадения и времени (аналогия - скорость равна расстоянию, деленному на время, а логарифм коэффициента совпадения пропорционален расстоянию между языками), но это значение в концепции Сводеша постоянно по определению.
Подставляя в формулу Сводеша для λ значение времени t для ряда значений c, получаем зависимость скорости изменения лексики "по Старостину" от времени. График ниже.
Буквально убивает то, что график начинается в начале координат (а начало координат с отметкой времени 0 - это текущий момент времени, современность) и практически линеен до некоторой глубины времени порядка 1,5 тысяч лет с наклоном 0,05 на тысячелетие, затем рост замедляется с достижением максимума скорости 0,136 при глубине времени 7400 лет, и далее плавным ее снижением.
Сталкиваться на практике со значениями λ менее 0,022 по формуле Старостина нет никакой возможности, поскольку выпадение всего 1 слова из 100-словного списка (которым пользовался Старостин) дает коэффициент совпадения c=0,99, что соответствует времени 451 год при минимальном расхождении между списками.
Проблема в том, что на современность теория формулы дает значение λ=0, т.е. лексические изменения языка исключаются, язык застывает в своем развитии. Непонятно, чем оказался выделенным 1989 год, год создания формулы, что именно к этому моменту все языки мира застыли в своем лексическом развитии. Продолжение тенденции требует отрицательных значений λ уже в настоящее время, 2020-е годы.
А отрицательное значение λ - это тяжелый удар по лингвистике, это значение лишено лингвистического смысла. По формуле Сводеша это означает замену распада списка его восстановлением (согласитесь, это звучит красиво - со временем мы заговорим на языке Ломоносова, затем времен Ивана Грозного, и возможно даже Александра Невского).
Для формулы Старостина отрицательные значения λ означают отказ от действительного времени и переход к мнимому - это уже из области научного фэнтези.
Время, фигурирующее в формуле Старостина, не является знакомым и привычным для нас физическим временем, которое аддитивно. Аддитивность означает, что время можно складывать и вычитать. Юноша, поступивший в университет в возрасте 18 лет, при 5-летнем сроке обучения вправе рассчитывать на выпуск в возрасте 18+5=23 лет.
Не то с формулой Старостина, она концептуально пригодна лишь для расчетов в определенный момент времени, а именно создания формулы с ее калибровкой по фактическим данным.
Поясним сказанное примером. Представим современный гипотетический язык, по которому составлены списки, отражающие его состояние 2000 лет назад (список А), 1000 лет назад (список Б) и современность. Подставив в формулу Старостина значение t=2 тысячелетия, находим c=0,845 . Для t=1 находим c=0,953. Пока все логично.
Перемещаемся (мысленно) на 1000 лет назад. Список Б становится современным, список А – устаревшим на 1000 лет (с позиций нашей современности). Сравниваем списки, список А за 1000 лет сохранился на 0,845/0,953=0,887 долю. Рассчитываем его древность по формуле Старостина, получаем 1640 лет, а не ожидаемые 1000 лет. Расхождение за счет того, что мы считаем, согласно формуле, что 2000 лет назад язык изменялся быстрее, чем 1000 лет назад, для жившего же 1000 лет назад человека отсчет времени назад начинается с момента его современности, отсюда более медленное изменение языка, что потребовало увеличения интервала времени на реализацию отмеченных изменений в списках.
Причина парадокса объяснена выше – формула Старостина, вне точности ее калибровки и соответствия историческим данным, это формула "к случаю", пригодная лишь для расчета дивергенции пары языков в момент времени создания формулы, предположительно 1989 год. Время в формуле Старостина не линейно и неаддитивно, что не отвечает его интуитивно воспринимаемым свойствам.
В целом мы придерживаемся мнения, что необходимости в отходе от положений классиков глоттохронологии о неизменности скорости изменения лексики на всем временном диапазоне нет.
Спасибо за долготерпение и чтение статьи до конца. Надеемся, она позволила разобраться в одном из вопросов лингвистики.
Для чтения:
Новая глоттохронология