Как известно, стоит перейти от простого языка к сложному, в котором есть ООП и прочее, так и программы становятся больше, и работать они начинают медленнее, и всё это ради удобства разработки. Будем смотреть, до каких пределов мы можем добавлять ООП в чистый C, чтобы скомпилированные программы не начинали распухать и тормозить.
Предыдущая часть:
Итак, в чистом C для эмуляции ООП мы используем структуру как класс и набор функций как методы класса.
В C++, как известно, классы это те же структуры, а методы классов это по-прежнему набор функций, только не самостоятельных, а принадлежащих конкретному классу. Влияет ли это как-то на скомпилированную программу?
Нет, по факту и в том, и в другом случае в машинном коде мы увидим одни и те же структуры и один и тот же набор функций. Но в тексте программы на C++ их будет проще организовать и структурировать. Значит, C++ удобнее при прочих равных.
Наследование
До сих пор говорилось про очень простую схему "структура и функция", но что будет, если мы начнём применять всё более продвинутое ООП?
Сделаем класс Parent и отнаследуем от него класс Child. Как делается наследование, видно в самом коде:
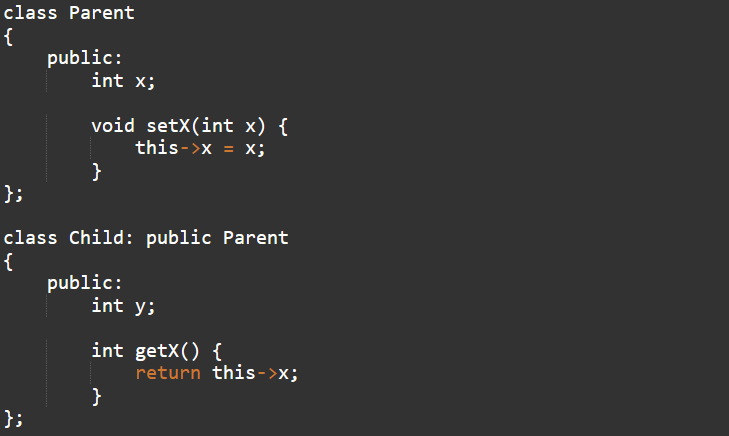
Единственное, на что хочу обратить внимание – я первый раз в жизни вижу, чтобы наследование происходило с модификатором доступа, т.е. public / protected / private. Это очень необычно и не очень понятно, зачем вдруг. Пока не буду отвлекаться и просто скажу, что модификатор public даёт обычное наследование "как у всех", и этого должно быть достаточно.
Итак, Child наследует от Parent свойство x и метод setX(), при этом имеет собственное свойство y и метод getX(). Посмотрим, изменится ли что-то в машинном коде.
Если Parent это структура, состоящая из одного поля x, то Child это структура, состоящая из двух полей x, y. На уровне машинного кода это просто и банально её собственные поля, которые ниоткуда не заимствуются. Также есть функция setX(), куда можно передавать указатель на любую из структур, так как обе они имеют поле x, расположенное по одному и тому же смещению.
То есть данное наследование пока ещё ничего никак не усложнило. Никаких родственных связей между Parent и Child в машинном коде нет, это просто две разные структуры. В тексте программы мы, получается, просто используем некий синтаксический сахар, чтобы не объявлять повторно свойство x и метод setX() в Child.
Я использую слово "поле", когда говорю про структуру, и "свойство", когда про класс, но это одно и то же, синонимы. Просто так исторически сложилось.
Но теперь предположим, что мы добавили в Parent некий конструктор:
Это приводит к тому, что у Child появляется имплицитный конструктор, который мы не добавляли. И этот конструктор состоит из вызова конструктора Parent. И даже если мы явно напишем точно такой же конструктор для Child, который делает абсолютно то же самое:
всё равно сначала будет вызван конструктор Parent.
И вот это уже наглядная родственная связь и усложнение. Если бы Parent и Child были независимы, то у каждого был бы просто собственный конструктор. Но будучи отнаследован, Child совершает лишние телодвижения, вызывая родительский конструктор даже тогда, когда это по факту не нужно. Можно представить себе цепочку наследования длиной в 10 потомков, и каждый будет вызывать конструктор своего родителя...
Переопределение методов
С конструкторами понятно. Что, если теперь в Child добавить метод setX(), который ничем не отличается от родительского? Результат: в программе появляются два идентичных метода setX(), один из которых "принадлежит" классу Parent, а другой классу Child.
Уточню: методы не обязаны быть идентичные по содержанию, а только по сигнатуре, т.е. void setX(int x).
Соответственно, если у класса Child есть свой метод void setX(int x), родительским он уже не пользуется. Это называется переопределением метода.
Если Child всё же захочет вызвать родительский метод из своего метода, то вызов будет выглядеть так:
Parent::setX(x);
Два двоеточия :: в своё время породили целую субкультуру и до сих пор используются для создания некого "кулхакерского вайба".
Ну а по сути это определитель контекста. Такая запись указывает, откуда именно берётся функция setX(), так как функций с одинаковыми именами может быть много. В общем, понятно, что setX() в данном случае относится к Parent.
Можно ли использовать функцию из другого класса? Например, сделаем класс Test, который никак ни с кем не связан, и имеет метод setX(), и попробуем вызвать его из класса Child:
Test::setX(x);
В принципе-то да, но нет. Дело в том, что в такой метод неявно должен передаваться текущий экземпляр класса, который известен как this. Из метода Child мы можем передать его собственный экземпляр в другие методы Сhild и в методы Pаrent, а вот в методы Test не можем, потому что это отдельный класс и работает он только с экземплярами класса Test. Так что получаем ошибку:
error: cannot call member function ‘void Test::setX(int)’ without object
Метод будет можно вызвать статически, но про это потом.
В итоге, переопределение метода ведёт к просто появлению ещё одного метода и таким образом ничего не усложняет.
Усложнение продолжится в следующих выпусках, а пока небольшой курьёз.
Пустые объекты
В комментариях к прошлым материалам высказывалась такая мысль. Вот объект состоит из каких-то данных, он, можно сказать, материален. Но если сделать класс, который состоит только из методов, то как будет выглядеть объект этого класса, и не будет ли это профанацией слова "объект", так как ничего материального в нём нет?
Давайте посмотрим.
Создание объекта мы явно запрашиваем, когда пишем Test test, но по факту в коде ничего не резервируется и не создаётся, а просто сразу вызывается подпрограмма Test::test() с аргументом 123.
В данном случае объекта действительно нет, но он существует для компилятора как мета-объект, у которого есть как минимум одно материальное свойство: класс со значением Test. И именно по этому свойству компилятор понимает, какой метод test() нужно вызывать.
Ладно, а что будет, если такой пустой объект передать в функцию как аргумент?
Формально создано 4 объекта, на деле ни одного. Но что интересно: в каком количестве ни создавай эти объекты, на стеке всегда резервируются 16 байт, которые никак не используются.
Каждый вызов функции test() происходит без какой-либо передачи аргументов, хотя формально они указаны.
Сама функция test() также бессмысленно резервирует 16 байт на стеке, ничего с ними не делая. Как будто она готовилась сохранить туда входные параметры, но не задалось. Дальше интересно: она должна вызвать метод Test::test(), и передать туда указатель на объект, то есть this. Несмотря на то, что объект пустой, this должен быть по определению, поэтому функция делает его, насколько понимаю, фиктивным, резервируя в своём фрейме... один байт. Да, ровно один байт, видимо потому что меньше нельзя.
Короче говоря, такой объект подменяется некой минимальной пустышкой и просто нигде не используется. Однако заставляет гонять туда-сюда регистры и резервировать стек впустую. Это скорее всего решается оптимизацией, но если я её включу, от текущей программы вообще ничего не останется, так как она бессмысленна.
Указатели на пустые объекты
Давайте теперь в функцию test() передадим указатель на пустой объект. Объекта нет, но указатель-то должен быть?
Функция main() на этот раз действительно создаёт указатели и передаёт их в функцию test(), а та уже передаёт эти указатели в метод Test::test() в качестве this, т.е. всё происходит как бы штатно. Но что из себя представляют эти указатели? Из зарезервированных на стеке 16 байт для каждого из объектов obj1, obj2... выделяется ровно один байт, то есть они получают смещения в стековом фрейме bp[-1], bp[-2] и т.д. Кстати, впервые вижу использование смещений, не кратных 2. И снова это объекты-пустышки, указатели на которые создаются лишь формально.
И всё-таки видно, что если завести более 16 объектов, то зарезервированных 16 байт перестанет хватать. Значит, должно зарезервироваться больше? Да, как только появляется 17-й объект, на стеке выделяется уже не 16 и не 17, а 32 байта. Получается, что пустыми, абсолютно бесполезными объектами тоже можно забить стек.
А что там с new?
Когда мы вызываем оператор new, то под объект должна быть динамически выделена память в куче. Что же происходит, когда мы пишем new Test(), запрашивая выделить память под абсолютно пустой объект? Она действительно выделяется в размере один байт. То есть по-прежнему имеем объект-пустышку. Правда, последствия на этот раз более серьёзные, так как эту память надо будет потом освободить.
Как же это понимать?
А вот так:
В скомпилированном коде уже нет ни структуры программы, ни задекларированных объектов. Это просто код, набор отдельных инструкций. Поэтому говорить о соблюдении там какой-то идеологии просто бессмысленно. Это уже сваренный суп, или даже переваренный, где исходные куски продуктов уже расщепились на молекулы.
Где объекты есть, так это в исходном коде. А это как рецепт супа. Поэтому мы оперируем понятием "объект" именно на уровне рецепта. И хотя наш объект пустой, у него есть мета-свойство класса. Следовательно, он НЕ пустой, он содержит информацию. Поэтому мы и можем спокойно считать его объектом и куда-либо передавать. Передаём мы информацию о классе, которая открывает доступ к методам класса.
Но в результате это будет приводить к некоторому "зашумлению" скомпилированного кода лишними и бессмысленными действиями по сравнению с чисто процедурным вариантом. Вся надежда на оптимизатор.
Читайте дальше: