Сделали обновление, все хорошо, ошибок нет, пользователи не жалуются. Вечером выясняется, что весь день не работали обмены с внешней системой из-за программной ошибки. Обмены выполнялись регламентным заданием, из-за этого ошибка не была замечена сразу.
Чтобы избежать подобных ситуаций, нужна система мониторинга ошибок. Например, в Мониторе этот функционал есть, и он бесплатен - для мониторинга и анализа ошибок используется показатель Ошибка ТЖ.
При включении показателя в технологическом журнале начинают фиксироваться события EXCP, то есть различные ошибки и исключения.
Если просто выводить ошибки одним большим списком, то разобраться в этом море информации будет довольно сложно. Чтобы избежать хаоса, в Мониторе работает категоризация ошибок. Каждой ошибке присваивается определенная категория, и дальнейший анализ выполняется уже в разрезе этих категорий.
Правила для категоризации заданы по умолчанию, но их можно поменять или создать свои.
Принцип действия очень простой: в категории указываются условия, и если ошибка подходит хотя бы под одно из условий, ей присваивается эта категория.
Пример на скрине ниже можно трактовать следующим образом: если текст ошибки (свойство Descr) соответствует хотя бы одному из трех шаблонов регулярного выражения, то ошибке назначается данная категория. В данном случае регулярные выражения простые, фактически если текст ошибки содержит хотя бы одну из трех фраз, ошибке будет присвоена данная категория.
Более подробно про настройку и работу с категориями можно почитать в документации.
Рассмотрим на примерах как показатель Ошибка ТЖ помогает отслеживать состояние системы.
Ситуация 1.
Необходимо получать уведомление в Телеграм, если случилось падение рабочего процесса.
Решение:
Для начала заполним настройки уведомлений, чтобы иметь возможность получать сообщения от Монитора.
Монитор может отправить сообщение по почте либо в Телеграм, либо сразу по обоим каналам.
Соответствующие параметры указываются в разделе Настройки - Уведомления.
Подробности по настройке уведомлений описаны в документации.
Ошибки, связанные с падением рабочего процесса, попадают в категорию "Падение рабочего процесса".
Создадим новый триггер и заполним его как на скрине ниже.
Рассмотрим основные настройки.
Вид события - определяет за какими именно событиями (показателями) будет следить данный триггер. Каждому показателю соответствует одноименное событие. В данном случае мы отслеживаем ошибки, поэтому и тип события выбираем соответствующий - "Ошибка из тех. журнала".
Обрабатывать события за последние ... минут - период, за который будут обработаны события. Если нужно обработать событие сразу при появлении, можно поставить 1 минуту. Если условие накопительное, например 4 таймаута за час, тогда для этого примера параметр будет равен 60 минутам.
Алгоритм - алгоритм обработки выбранных событий. Именно в алгоритме происходит проверка условий и выполнение необходимых действий. Есть набор уже готовых алгоритмов, хотя можно написать и свой собственный. Все алгоритмы написаны на языке 1С.
В данном случае алгоритм отправляет уведомление, если появилась хотя бы одна ошибка из указанной категории ("Падение рабочего процесса") в течение выбранного времени.
Ситуация 2.
Необходимо проверять - появились ли какие-либо программные ошибки после обновления, изменения настроек и пр.
Решение:
Нужно открыть форму анализа ошибок Анализ - Ошибки тех. журнала.
Далее выбираем нужный период и базу.
Все программные ошибки попадают в категорию Программные. Рекомендуется регулярно просматривать данную категорию на предмет появления новых ошибок, особенно после выполнения обновлений.
Ситуация 3.
Появилось большое количество ошибок "Рабочий процесс не найден". Нужно определить критичность проблемы и выяснить причину.
Решение:
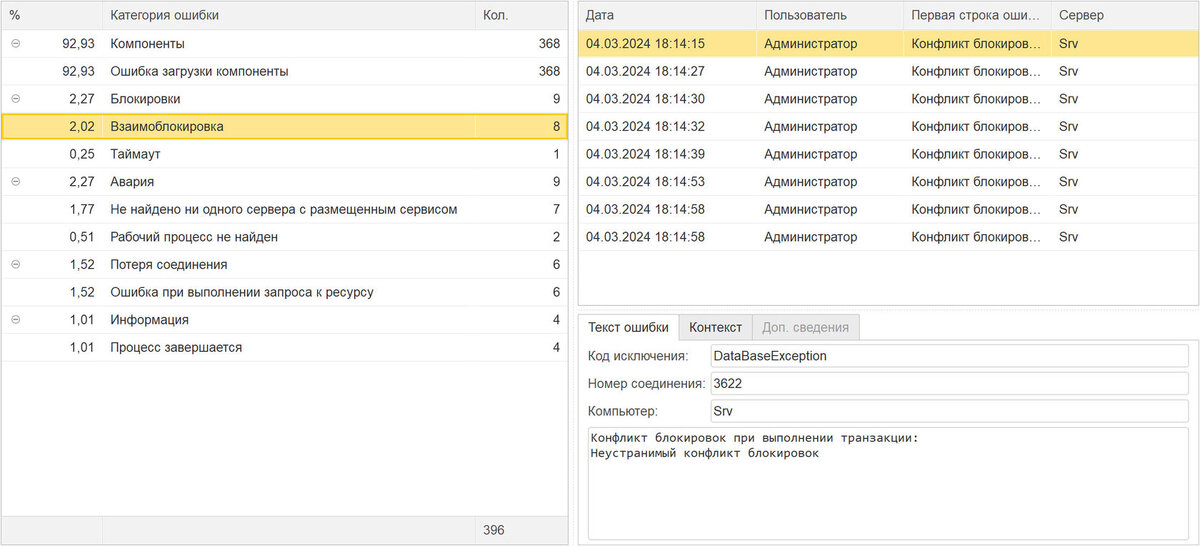
В форме анализа ошибок находим необходимую категорию.
Судя по данным, ошибка возникает каждые несколько минут, хотя жалоб от пользователей не поступает. Поиск в интернете не внёс ясности, кроме рекомендаций обновить платформу.
Чтобы выявить какие-то закономерности, решили посмотреть появление ошибки на линии времени.
На графике видно, что нет ярко выраженных пиков ошибки, и она повторяется почти равномерно с интервалом в несколько минут.
Возникло предположение, что кто-то поменял время перезапуска процессов в настройках кластера. Проверили - перезапуск стоял раз в сутки.
Заодно посмотрели другие настройки кластера и заметили, что в свойствах сервера параметр Количество соединений на процесс установлен в значение 256, что очень близко к количеству пользователей, работающих в базе.
Решили провести эксперимент, создали новый кластер с одной тестовой базой. Для сервера в данном кластере поставили Количество соединений на процесс в значение 5 и настроили технологический журнал на сбор ошибок по этой базе.
При попытке подключения шестого пользователя был создан новый рабочий процесс. Потом оставили 4 активных сеанса, завершив 2. Через несколько минут второй рабочий процесс штатно завершил свою работу, но при этом в технологический журнал попала строка:
20:55.183005-0,EXCP,0,process=rphost,OSThread=20868,Exception=acea3e6e-3687-4792-8319-09c009274c9a,Descr='src\rserver\src\RPHostImpl.cpp(1564):
acea3e6e-3687-4792-8319-09c009274c9a: Рабочий процесс не найден'
Получается, что запись об ошибке попадает в лог даже в том случае, если процесс штатно завершил свою работу.
В данном случае количество соединений в кластере колебалось возле пороговой величины в 256 соединений, в итоге постоянно стартовали и завершались рабочие процессы, что и приводило к большому числу подобных записей в логах.
После изменения значения параметра до 300 количество подобных сообщений сильно сократилось.
Ситуация 4.
Необходимо найти пользователей, у которых ошибки наблюдаются чаще всего.
Решение:
Форму анализа ошибок ТЖ использовать не получится, так как там идёт разбивка по категориям, а не по пользователям.
Для выполнения задачи можно использовать отчет "Ошибки тех. журнала", вариант "Пользователи".
Как видно из отчета, 97% записей технологического журнала не содержат имени пользователя. Зачастую эти записи даже не являются ошибками и у пользователей не появляются. В этом отчете нам они не интересны - установим отбор, исключающий пустое значение пользователя.
Сразу определились два лидера по количеству ошибок, и если под DefUser скрывается пользователь по умолчанию, под которым запускается большое число регламентных заданий, то деятельность пользователя ...ваОК требует внимательного рассмотрения.
Далее можно сделать расшифровку только по этому пользователю и принимать очередные действия по анализу.
Используя отчеты и всю мощь СКД, можно получить необходимую информацию в любых разрезах.
Монитор позволяет не только собирать ошибки, но и классифицировать, группировать и формировать отчеты.
Возможность анализировать ошибки тех. журнала доступна в Мониторе бесплатно.
Показатель "Ошибка ТЖ" описанный в данном кейсе, доступен в бесплатной версии Монитора.