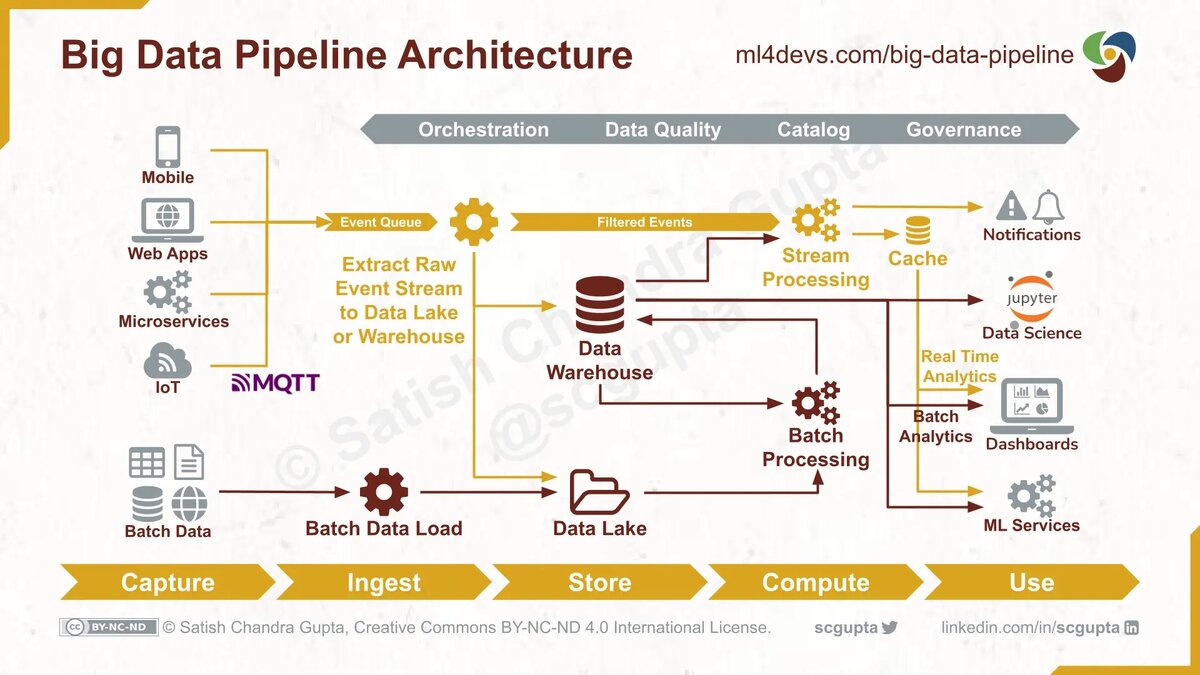
Существует несколько архитектурных вариантов, предлагающих различные компромиссы между производительностью и стоимостью. Технически лучший вариант не обязательно может быть самым подходящим решением в производстве. Вы должны внимательно изучить свои требования:
- Вам нужна информация в режиме реального времени?
- Какова устойчивость вашего приложения к устареванию?
- Каковы ограничения по стоимости?
Архитектура конвейера больших данных с использованием open-source-решений
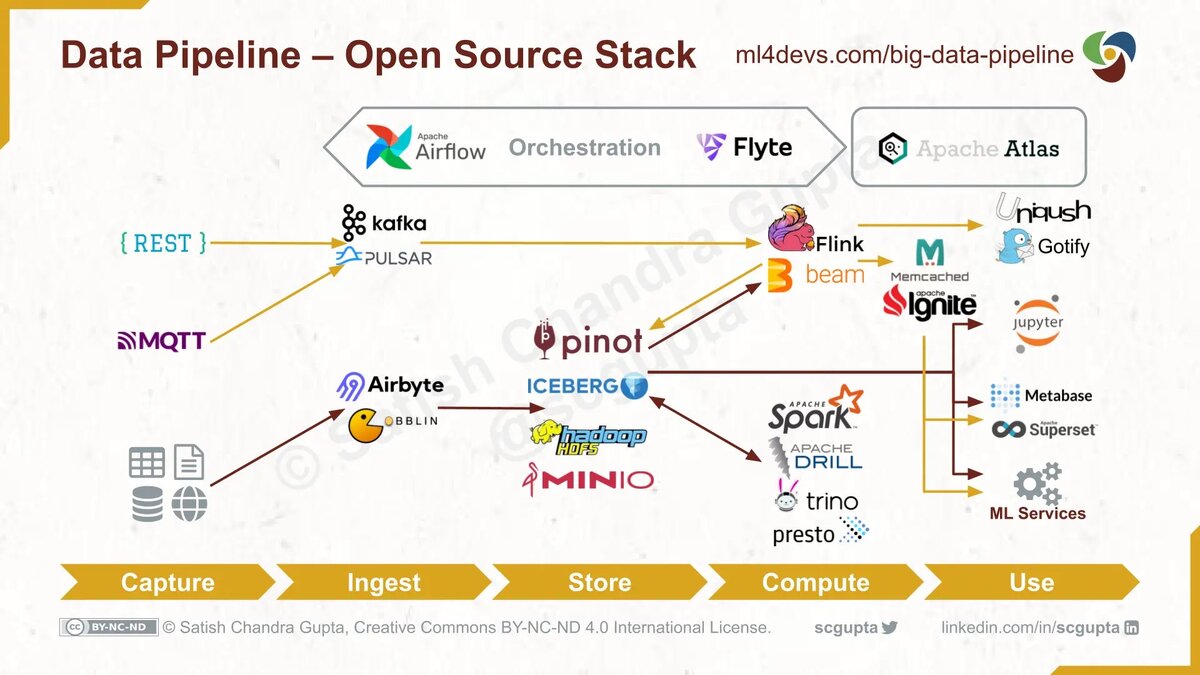
Ключевые компоненты архитектуры больших данных и выбор технологий следующие:
- Конечные точки HTTP/MQTT для приема данных и возвращения результатов. Для этого существует несколько фреймворков и технологий.
- Очередь сообщений Pub/Sub для приема больших объемов потоковых данных. Kafka в настоящее время является хорошим выбором. Доказано в боях, что она хорошомасштабируется.
- Недорогое хранилище данных большого объема для data lake, Hadoop HDFS или облачного хранилища BLOB-объектов, такого как AWS S3.
- Инфраструктура запросов и каталогов для преобразования data lake в хранилище данных. Apache Hive — популярный язык запросов.
- Механизм пакетных вычислений Map-Reduce для высокопроизводительной обработки, например Hadoop Map-Reduce, Apache Spark.
- Потоковые вычисления, например Apache Storm , Apache Flink. Apache Beam, для обработки потока данных. Его можно развернуть в Spark или Flink.
- Платформы машинного обучения. Scikit-Learn, TensorFlow и PyTorch — популярные варианты реализации машинного обучения.
- Хранилища данных с низкой задержкой для хранения результатов. Существует множество устоявшихся вариантов хранилищ данных SQL и NoSQL в зависимости от типа данных и варианта использования.
- Варианты оркестрации развертывания — Hadoop YARN, Kubernetes / Kubeflow.
Масштаб и эффективность контролируются следующими инструментами:
- Пропускная способность зависит от масштабируемости приема (т. е . конечных точек REST/MQTT и очереди сообщений), емкости хранилища данных и пакетной обработки.
- Задержка зависит от эффективности очереди сообщений, потоковых вычислений и баз данных, используемых для хранения результатов вычислений.
Архитектура конвейера больших данных на базе облачных провайдеров
Рассмотрим AWS, Azure и Google Cloud, в чем реализация совпадает:
1. Прием структурированных или неструктурированных данных.
2. Хранение необработанных данных.
3. Обработка данных, включая фильтрацию, преобразование, нормализацию и т. д.
4. Хранилище данных, включая хранилище «ключ-значение», реляционную базу данных, базу данных OLAP и т. д.
5. Контроль состояния с информационными панелями и уведомлениями в реальном времени.
Интересно видеть, что разные поставщики облачных услуг имеют разные названия для одного и того же типа продуктов.
Например, продукт называется «lambda» в AWS и «function» в Azure и Google Cloud.
P.S. Можете привести аналогичную диаграмму в разрезе отечественных облачных решений?