В ежегодном отчете MDR (пример, 2023, стр. 9) мы публикуем время обработки инцидента. Велик соблазн сравнить это время с метрикой времени реакции в SLA, например, укладывается ли время обработки для High в один час. Однако, время обработки инцидента, или "Скорость обнаружения инцидента", как это обозначается в отчете, лишь незначительно коррелируют с метрикой соглашения об уровне сервиса, об этом и поговорим в статье.
Как устроено время реакции, адресуемое метрикой SLA я рассказывал здесь. Если обратиться все к тем же отчетам (см. раздел Эффективность реагирования на странице 15), то в подавляющем большинстве инцидентов уровня High мы имеем более одного алерта, они разбросаны во времени и аналитик может найти их далеко не все сразу. Нередка ситуация, когда в процессе анализа релевантных алертов, собранных на данный момент, находятся новые артефакты, по которым уже находятся еще более ранние алерты. О процессе поиска событий по индикаторам и извлечении новых индикаторов из найденных событий мы говорили здесь. Итак, для High инцидента алертов может быть очень много, время на обработку алерта ненулевое, поэтому время на их анализ тоже может быть немаленькое.
Чем больше алертов, тем больше мы имеем информации, которую необходимо изложить в карточке инцидента для заказчика. При этом, если карточка не будет содержать важную информацию, инцидент будет считаться не дорасследованным, что по нашей классификации - ошибка среднего уровня. Да, у нас есть шаблонизатор и кое-какие автоматики для ускорения подготовки описания, однако, логика неумолима: чем больше нам надо описать в карточке, тем дольше мы будем эту карточку писать. Перефразирую: чем сложнее инцидент, тем дольше готовится его описание в карточке инцидента.
Согласно SLA, о критичном инциденте необходимо оповестить, уже с рекомендациями, меньше чем за 1 час, поэтому на практике применяется стандартный прием: когда аналитик видит, что времени на полноценное расследование и оформление не хватает, он публикует карточку инцидента с имеющимся на данный момент, если есть понимание как реагировать - пишет рекомендации или назначает подходящие респонсы, но указывает, что по кейсу продолжается работа и он будет обновляться по мере появления новой информации. Т.е. время реакции в SLA - это время от создания первых алертов по инциденту, взятых аналитиком в работу, до момента публикации карточки. Далее, инцидент может обновляться и перепубликовываться, по нему могут находиться новые, еще более ранние алерты, но все эти обновления уже не влияют на метрику SLA. Звучит как будто не очень, да? Сценарий, когда в ходе расследования были найдены более ранние алерты, пропущенные на тот момент (а это ошибка!), выглядит несправедливо не учитывемым в SLA, однако, это не совсем так, и, возможно, заслуживает отдельной статьи. Но если кратко, то аргументы примерно следующие: намного проще оценивать прошлое, когда вскрылись новые факты, о которых на момент принятия решения в прошлом не было известно; глубина телеметрии MDR ограничена, поэтому связывать события в реальном времени не всегда получается (на слайде 8 - иллюстрация для ограничений телеметрии MDR).
Итак, думаю, сейчас стало понятно, что информация выполнении метрик SLA не привносит ничего в характеристику ландшафта угроз, а отчет, все-таки, преследует такую цель, поэтому в ежегодном отчете MDR мы под временем обработки инцидента показываем несколько иное. Для объяснения приведу вот такую картинку.
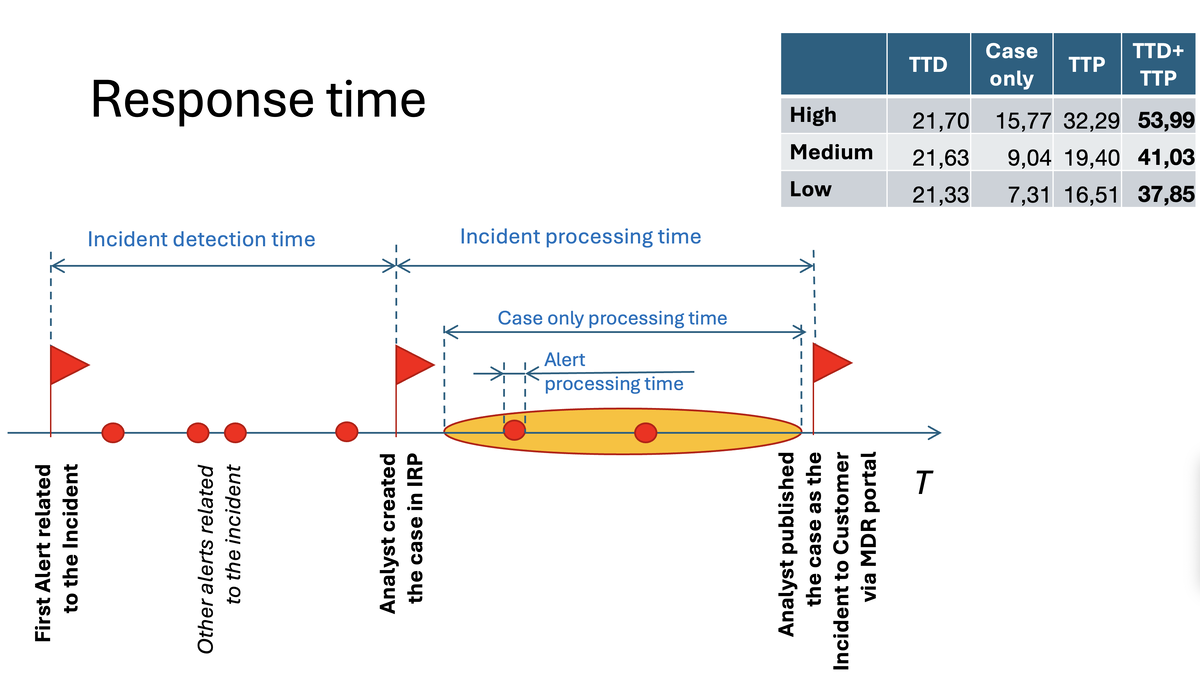
TTD - Time to detect (Incident detection time) - время от самого раннего алерта в инциденте до времени создания кейса во внутренней IRP. Я не раз рассказывал как происходит обработка алертов, можно посмотреть, например, вот эту презентацию. Числа в табличке - по данным статистики инцидентов за 2024, из них следует, что TTD практически не зависит от критичности инцидента, а это, кстати, означает, что каких-то пропущенных алертов, которые потом нашли в ходе расследования, например, для High инцидентов, в 2024 практически не было.
TTP - Time to process (Incident processing time) - время обработки инцидента. Это время состоит из времени работы над самим кейсом (Case only processing time) - фактически, это сколько длилось расследование на уровне кейса, где значимое время оставляет оформление карточки инцидента, и суммы времен обработки всех релевантных кейсу алертов (Alert processing time - это время от момента создания алерта в IRP до момента его импорта в кейс). Видно, что и Case only и TTP в значительной мере зависят от критичности. Несложно смекнуть, что разность TTP и Case only - это время, потраченное на обработку всех релевантных кейсу алертов. Так как разность эта тоже зависит от критичности, а время анализа алерта варьируется незначительно, получаем, что количество релевантных алертов зависит от критичности и для High оно, в среднем, наибольшее, что в общем-то из года в год подтверждается аналитиков (раздел Эффективность реагирования, на стр. 15).
В аналитическом отчете хочется одновременно дать оценку и времени обнаружения и времени обработке кейса, поэтому представленные там числа - это сумма TTD и TTP, так как она достоверно характеризует и как долго не замечали инцидент и сколько потратили на его расследование перед публикацией. Возможно, в новых отчетах, имеет смысл давать отдельно TTP и TTP, я об этом еще подумаю.