Введение
При обучении специализированных языковых моделей (LLM) одна из ключевых проблем — overfitting (переобучение). Модель, идеально запомнившая обучающий датасет, может плохо работать на новых данных. Поэтому важно не только обучить LLM, но и проверить её реальную применимость.
В этой статье рассмотрим:
✔ Что такое overfitting и почему он опасен для LLM
✔ Методы предотвращения переобучения
✔ Как оценить реальную применимость модели
✔ Какие тестовые методики и метрики использовать
1. Что такое overfitting и почему он опасен?
Overfitting (переобучение) — это когда модель слишком хорошо запоминает обучающие данные, но теряет обобщающую способность.
1.1 Признаки overfitting в LLM
📌 Высокая точность на обучающем наборе данных, но низкая на тестовом
📌 Модель повторяет тексты из датасета вместо генерации новых
📌 Ошибки при генерации новой информации, не встречавшейся в обучении
📌 Низкая адаптация к изменяющимся контекстам
1.2 Почему переобучение особенно критично для LLM?
🔹 Сложные паттерны: LLM работают с текстами, где важно понимание контекста
🔹 Специализированные домены: в медицине, юриспруденции и финансах ошибка может стоить очень дорого
🔹 Риск утечки данных: если модель запомнит конфиденциальные данные, это приведёт к утечкам информации
2. Методы предотвращения переобучения в LLM
Чтобы избежать overfitting, применяют следующие методы:
2.1 Разделение данных на тренировочные, валидационные и тестовые
Обычно используется разбиение 80/10/10:
✔ 80% – обучающий датасет (train set)
✔ 10% – валидационный датасет (validation set)
✔ 10% – тестовый датасет (test set)
💡 Пример разбиения с помощью Python (Hugging Face)

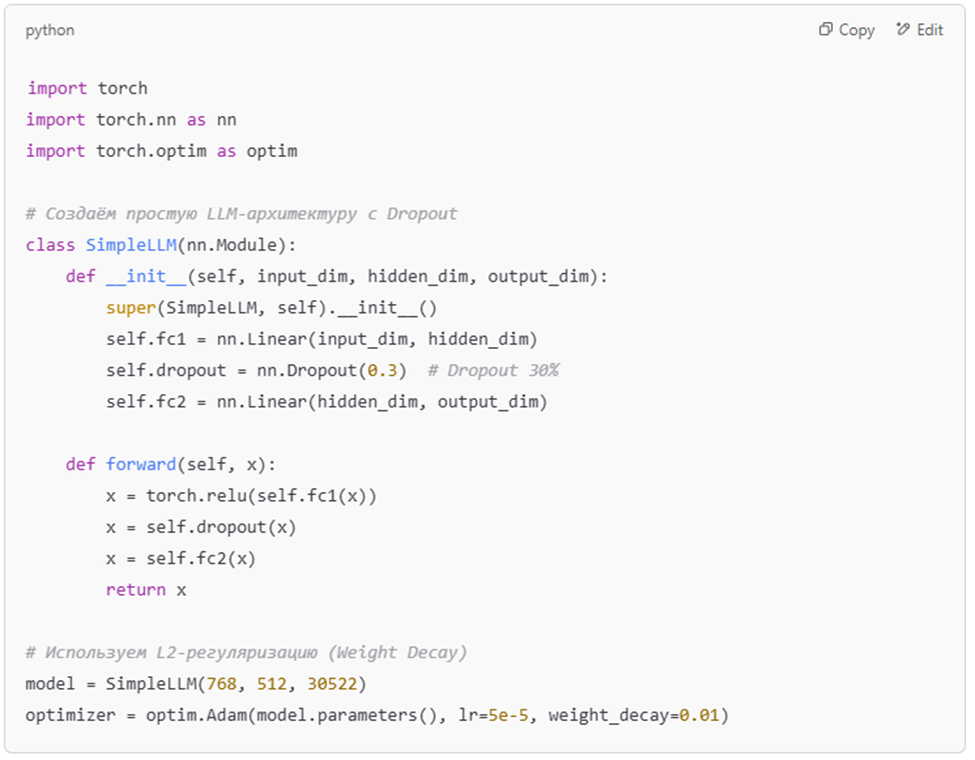
2.2 Регуляризация (Regularization)
Используются три ключевых метода:
📌 Dropout – случайное отключение нейронов во время обучения
📌 L2-регуляризация (Weight Decay) – предотвращает переобучение, уменьшая влияние слишком сложных весов
📌 Early Stopping – остановка обучения, если качество на валидационном наборе ухудшается
💡 Пример настройки регуляризации в PyTorch
2.3 Использование техники Data Augmentation
Data Augmentation – искусственное увеличение количества обучающих данных:
📌 Парафразирование – изменение формулировок фраз
📌 Добавление ошибок – имитация реальных ошибок пользователей
📌 Генерация дополнительных данных с помощью GPT
💡 Пример парафразирования с помощью Hugging Face Transformers
2.4 Применение Transfer Learning и LoRA
Вместо полного fine-tuning можно использовать адаптивные методы (LoRA, PEFT, P-tuning).
Это позволяет минимизировать переобучение и адаптировать LLM к новым задачам.
💡 ПримерLoRA в Hugging Face PEFT
3. Как проверить реальную применимость модели?
После предотвращения overfitting важно убедиться, что LLM работает корректно в реальных условиях.
3.1 Тестирование на out-of-distribution (OOD) данных
💡 Идея: проверить, как LLM справляется с неизвестными примерами, которых не было в обучении.
📌 Метод: запустить модель на данных из других источников и сравнить результаты.
3.2 Ручное тестирование с экспертами
📌 Привлечь медиков, юристов, финансовых аналитиков для проверки качества ответов модели.
📌 Оценивать точность, полноту, связанность и корректность вывода.
💡 Пример таблицы оценки качества
3.3 A/B-тестирование
📌 Пользователям даются два варианта ответа (модель A и модель B)
📌 Они выбирают, какой лучше
📌 Сравниваем статистику выбора
4. Выводы
✅ Overfitting – опасная проблема, снижающая реальную применимость LLM
✅ Лучшие способы борьбы – разделение данных, регуляризация, data augmentation и адаптивные методы (LoRA, PEFT)
✅ Оценка реальной применимости включает тестирование на OOD-данных, экспертное тестирование и A/B-эксперименты
📌 Главное правило: LLM должна быть не только точной на обучающих данных, но и эффективной в реальном мире! 🚀
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Использование LoRA и других методов адаптации без полного fine-tuning: сравнение LoRA, QLoRA, P-Tuning, Adapter Layers- https://dzen.ru/a/Z6sPdqyfbxrSAAyZ
Тонкости fine-tuning LLM: стратегии и лучшие практики- https://dzen.ru/a/Z6sMG0FvPVkTx6K4
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru