
Введение
Большие языковые модели (LLM) демонстрируют высокую универсальность, но для эффективного решения конкретных задач требуется их адаптация. Существует три ключевых метода кастомизации LLM:
- Дообучение (Fine-tuning) – обновление весов модели на специализированном датасете.
- Адаптация с LoRA (Low-Rank Adaptation) – упрощенный вариант fine-tuning, позволяющий обновлять только часть параметров модели.
- Инжиниринг промптов (Prompt Engineering) – настройка входных данных без изменения модели.
В этой статье разберем каждый из методов, их преимущества и недостатки, а также приведем примеры реализации.
1. Дообучение (Fine-tuning)
Описание метода
Дообучение предполагает адаптацию существующей модели путем обновления ее весов на новом датасете. Этот метод позволяет модели запоминать специализированные знания и термины.
Применение
- Юридическая или медицинская документация
- Генерация текстов в специализированных областях
- Улучшение качества ответов на узкоспециализированные вопросы
Пример реализации fine-tuning (Hugging Face + PyTorch)
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset
# Загрузка модели и токенизатора
model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Загрузка специализированного датасета
dataset = load_dataset("scientific_papers", "arxiv")
train_texts = [item["abstract"] for item in dataset["train"]]
train_encodings = tokenizer(train_texts, truncation=True, padding=True, max_length=512)
# Настройки обучения
training_args = TrainingArguments(
output_dir="./fine_tuned_model",
per_device_train_batch_size=4,
num_train_epochs=3,
save_steps=100,
logging_dir="./logs"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_encodings
)
trainer.train()
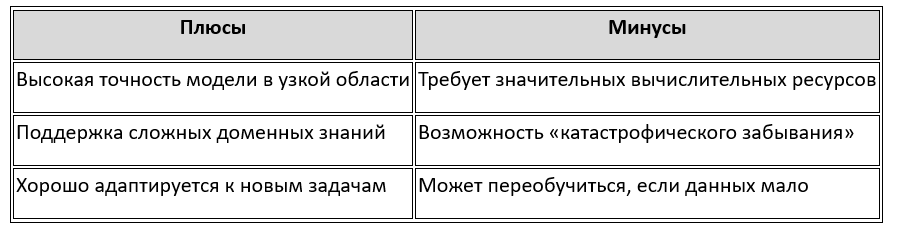
Плюсы и минусы
2. Адаптация с LoRA (Low-Rank Adaptation)
Описание метода
LoRA – метод, позволяющий обновлять только небольшое количество параметров модели, не изменяя всю архитектуру. Это снижает требования к ресурсам и ускоряет адаптацию модели.
Применение
- Быстрая адаптация моделей к новым данным
- Улучшение ответов на специфические запросы
- Поддержка мультиязычных приложений
Пример реализации LoRA
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
# Загрузка модели и токенизатора
model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_8bit=True)
# Настройка LoRA
config = LoraConfig(r=8, lora_alpha=32, lora_dropout=0.1, task_type="CAUSAL_LM")
model = get_peft_model(model, config)
Плюсы и минусы
3. Инжиниринг промптов (Prompt Engineering)
Описание метода
Инжиниринг промптов – это настройка входного текста для улучшения работы модели без изменения ее весов. Используется как самый простой и доступный способ кастомизации.
Применение
- Оптимизация взаимодействия с пользователем
- Формирование структурированных ответов
- Улучшение точности модели без дополнительного обучения
Пример инженерии промптов
from transformers import pipeline
# Загрузка предобученной модели
model_name = "gpt-3.5-turbo"
generator = pipeline("text-generation", model=model_name)
# Оптимизированный промпт
prompt = "Вы юрист. Ответьте на следующий юридический вопрос подробно: Какие основные аспекты защиты интеллектуальной собственности?"
response = generator(prompt, max_length=200)
print(response[0]['generated_text'])
Плюсы и минусы
Выводы
Fine-tuning подходит для сложных специализированных задач.
LoRA – эффективный компромисс между качеством и затратами.
Инжиниринг промптов – самый быстрый способ оптимизации LLM без затрат.
Выбор метода кастомизации зависит от ресурсов, доступных данных и целевых задач. В реальных проектах часто комбинируют эти подходы для достижения наилучших результатов.
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru