Определение требований к датасету для конкретной задачи
Введение
Обучение больших языковых моделей (LLM) требует качественных данных, соответствующих задаче, для достижения высокой точности и релевантности ответов. Неправильный выбор или подготовка датасета могут привести к низкой производительности модели, появлению ошибок и смещений в данных.
В этой статье разберем, как правильно определить требования к датасету, выбрать подходящие источники данных, очистить их и подготовить к обучению.
1. Определение требований к датасету
Перед сбором данных необходимо четко определить цели обучения модели.
Основные параметры
- Тип данных:
- Структурированные (таблицы, базы данных)
- Неструктурированные (тексты, изображения, аудиофайлы)
- Полуструктурированные (JSON, XML)
- Тематика:
- Медицина
- Финансы
- Юриспруденция
- Техническая документация
- Объем данных:
- Минимальный объем для базового обучения
- Оптимальный объем для стабильной генерации ответов
- Качество данных:
- Наличие ошибок, дубликатов
- Достоверность источников
- Язык и формат:
- Поддержка одного или нескольких языков
- Преформатирование текста (разметка, токенизация)
2. Выбор источников данных
Типы источников
- Открытые датасеты
- Hugging Face Datasets (например, Wikipedia, PubMed, The Pile)
- Kaggle (различные специализированные датасеты)
- Common Crawl (интернет-корпус)
- Arxiv.org (научные статьи)
- Корпоративные данные
- Внутренние базы знаний
- CRM-системы
- Документация компаний
- Генерация данных
- Использование существующих LLM для создания синтетического корпуса
- Автоматическая аннотация данных
Примеры специализированных датасетов
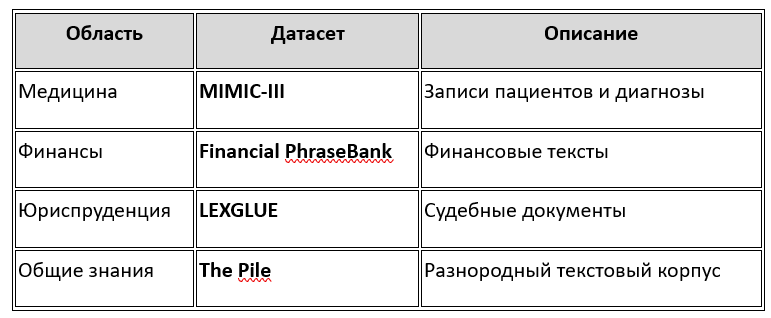
3. Очистка и препроцессинг данных
Этапы предобработки
1. Удаление дубликатов и шума

2. Очистка текста (приведение к нижнему регистру, удаление знаков)
3. Токенизация и приведение к стандартному формату
4. Аугментация и балансировка данных
Если данных недостаточно или есть дисбаланс классов, можно использовать аугментацию.
1. Перефразирование текстов
2. Добавление синтетических данных
5. Разделение данных на обучающую, валидационную и тестовую выборки
Разделение данных 80/10/10
Создание JSON-файла для обучения
Выводы
- Четко определите требования к датасету: тема, объем, качество.
- Выберите надежные источники: открытые датасеты, корпоративные данные, синтетические данные.
- Очистите и обработайте данные: удаление шума, токенизация.
- Используйте аугментацию для увеличения объема данных.
- Разделите данные на обучающую, валидационную и тестовую выборки.
Правильный подход к выбору и подготовке данных – залог успешного обучения LLM! 🚀
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru