Введение
Большие языковые модели (LLM, Large Language Models), такие как GPT, LLaMA и Falcon, представляют собой мощные инструменты, способные выполнять широкий спектр задач, включая генерацию текста, анализ данных, машинный перевод и многое другое. Однако для решения специализированных задач, например, анализа медицинских текстов или работы с юридическими документами, требуется адаптация модели к конкретному контексту.
В этой статье мы разберем, чем дообучение (fine-tuning) LLM отличается от обучения с нуля (training from scratch), а также приведем примеры кода для реализации обоих подходов.
1. Различия между обучением с нуля и дообучением
Обучение LLM с нуля
Обучение модели с нуля предполагает создание новой языковой модели с использованием большого количества текстовых данных и мощных вычислительных ресурсов. Этот процесс включает:
- Сбор и подготовку данных: требуется огромный корпус текстов, охватывающий различные темы и стили.
- Оптимизацию архитектуры модели: выбор количества слоев, внимания, размерности эмбеддингов и других параметров.
- Длительное обучение: используются тысячи GPU/TPU в течение нескольких недель или месяцев.
🔹 Пример использования: обучение новой модели для специфического языка, не охваченного существующими LLM (например, редкие диалекты).
Плюсы:
✔ Полный контроль над моделью и ее архитектурой.
✔ Отсутствие "лишних" данных, не относящихся к целевой задаче.
Минусы:
❌ Требует огромных вычислительных ресурсов.
❌ Длительный процесс обучения.
❌ Высокий риск ошибок на этапе разработки архитектуры.
Дообучение LLM (Fine-tuning)
Дообучение подразумевает адаптацию уже обученной модели под специфические задачи. Вместо создания модели с нуля мы берем предобученную LLM (например, LLaMA 2) и продолжаем ее обучение на специализированном датасете.
🔹 Пример использования: настройка модели для юридического анализа документов или медицинской диагностики.
Плюсы:
✔ Существенно снижает требования к ресурсам.
✔ Позволяет быстро адаптировать модель под конкретные задачи.
✔ Использует уже накопленные знания модели.
Минусы:
❌ Возможен эффект "катастрофического забывания" (модель может забыть исходные знания).
❌ Требуется тщательно подготовленный датасет.
2. Практическая реализация
2.1 Обучение LLM с нуля (на PyTorch + Hugging Face)
Обучение новой языковой модели требует использования библиотеки transformers и datasets.
Шаг 1: Определение архитектуры модели
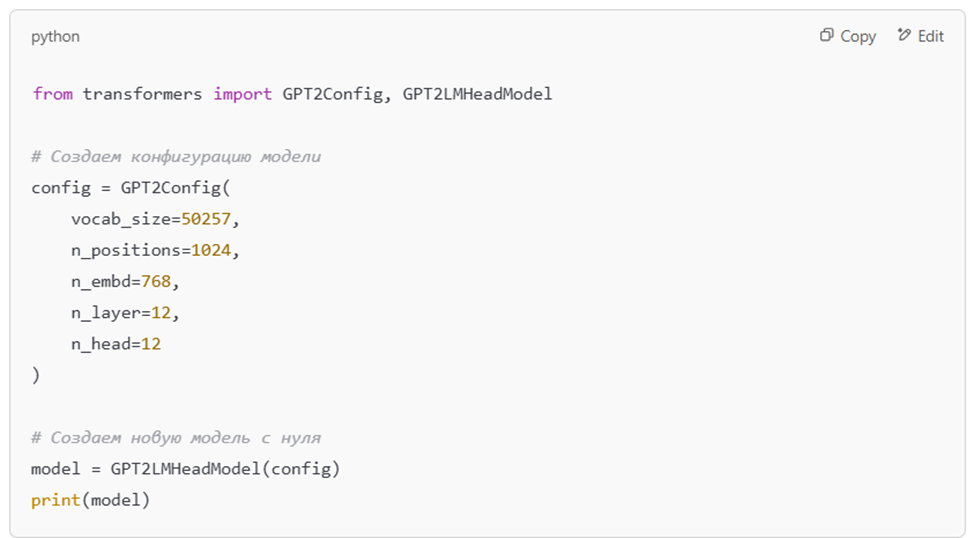
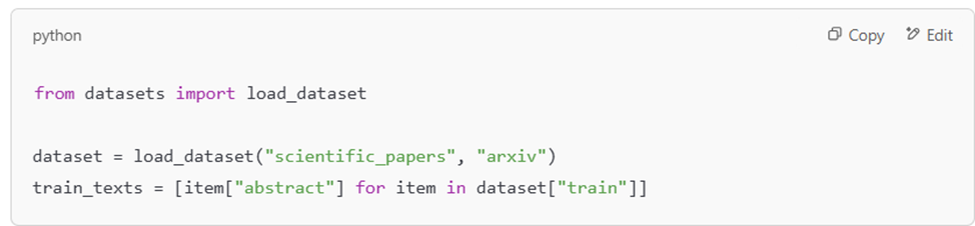
Шаг 2: Подготовка данных
Допустим, у нас есть корпус научных статей, который нужно использовать для обучения.
Шаг 3: Токенизация
Шаг 4: Обучение модели
2.2 Дообучение готовой модели (Fine-tuning LLaMA 2 с LoRA)
Для ускоренного fine-tuning можно использовать LoRA (Low-Rank Adaptation), что снижает требования к GPU.
Шаг 1: Установка зависимостей
Шаг 2: Загрузка предобученной модели и LoRA-адаптера
Шаг 3: Настройка LoRA
Шаг 4: Подготовка специализированного датасета
Допустим, мы хотим обучить LLaMA 2 на юридических текстах.
Шаг 5: Обучение модели
Выводы
Обучение LLM с нуля целесообразно только в исключительных случаях. Для большинства бизнес-задач fine-tuning дает оптимальный баланс качества и затрат. LoRA и другие методы делают этот процесс еще более доступным.
Если вам нужна дополнительная кастомизация, стоит рассмотреть RAG (Retrieval-Augmented Generation), который позволяет подгружать знания без переобучения модели.
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru