Введение
Адаптация больших языковых моделей (LLM, Large Language Models) под специфические задачи — сложная и ресурсоемкая задача. Полный fine-tuning модели, такой как Llama-2-13B или GPT-3, требует огромного количества вычислительных ресурсов и памяти, что делает его неэффективным для большинства пользователей.
В ответ на эту проблему появились параметро-эффективные методы адаптации (PEFT, Parameter-Efficient Fine-Tuning), которые позволяют обучать только небольшую часть модели, сохраняя основную структуру неизменной.
📌 Основные PEFT-методы:
- LoRA (Low-Rank Adaptation) – добавляет малые матрицы для адаптации весов.
- QLoRA (Quantized LoRA) – использует квантованные модели для еще большей экономии памяти.
- P-Tuning (Prompt Tuning) – адаптирует работу модели путем добавления обучаемых токенов.
- Adapter Layers – вставляет дополнительные слои в архитектуру модели.
Что рассмотрим в статье?
✅ Разберем принцип работы каждого метода.
✅ Проведем сравнение потребления памяти, вычислений и качества.
✅ Рассмотрим примеры кода и рекомендации по выбору метода.
1. Как работают адаптивные методы?
🔹 Основная идея: вместо того чтобы изменять все параметры модели, мы адаптируем только часть весов, что снижает требования к памяти и ускоряет обучение.
1.1. LoRA (Low-Rank Adaptation)
🔹 LoRA добавляет обучаемые матрицы маленького ранга к слоям модели, изменяя только их малую часть.
🔹 Как работает?
- Вместо обновления всей матрицы весов W (размером d × k)
- LoRA добавляет две маленькие матрицы A (d × r) и B (r × k)
- Итоговая формула:
W′=W+A×BW' = W + A \times BW′=W+A×B
📌 Код применения LoRA в Hugging Face PEFT
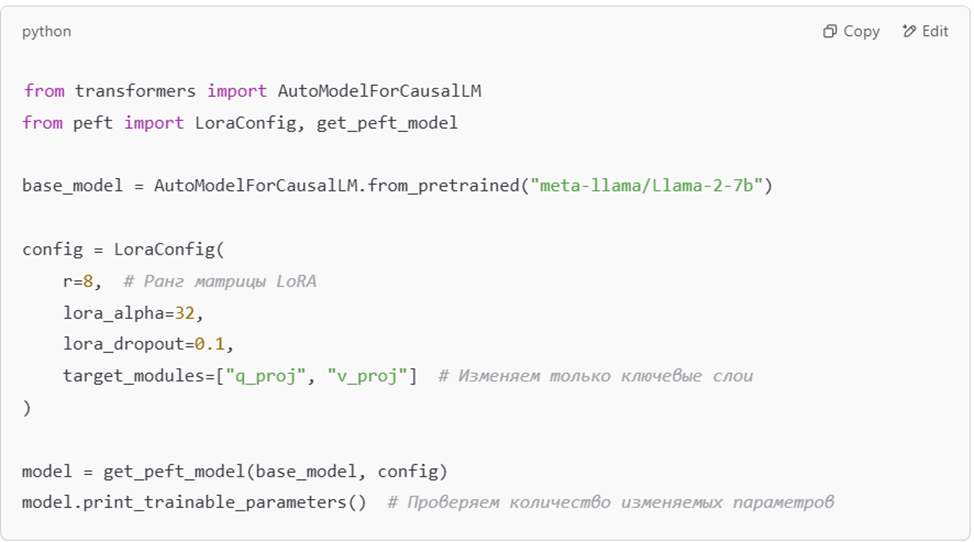
🔹 Плюсы LoRA:
✅ Снижает потребление памяти (VRAM) в 10-100 раз
✅ Можно обучать даже на средних GPU (16-24GB VRAM)
✅ Сохраняет базовую модель неизменной
🔹 Минусы LoRA:
❌ Не всегда подходит для сложных задач, требующих глубокого fine-tuning
1.2. QLoRA (Quantized LoRA)
📌 QLoRA = LoRA + 4-bit квантование модели
🔹 Как работает?
- Использует NF4 4-bit квантование для уменьшения размера модели.
- Добавляет LoRA-адаптацию на квантованные веса.
📌 Пример кода использования QLoRA
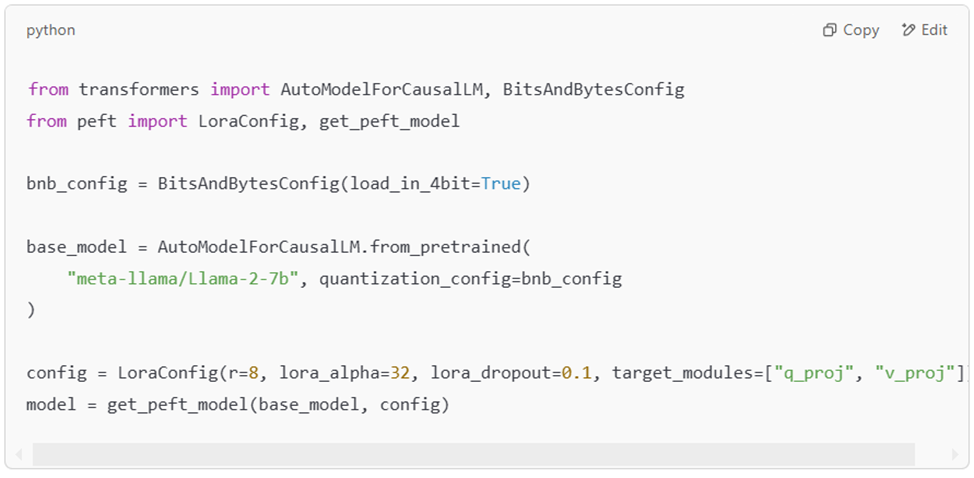
🔹 Плюсы QLoRA:
✅ Можно обучать модели 13B+ даже на одной GPU с 24GB VRAM
✅ Качество почти такое же, как у обычного LoRA
🔹 Минусы QLoRA:
❌ Дополнительные затраты на квантование и обратное деквантование
❌ Иногда снижает точность модели
1.3. P-Tuning (Prompt Tuning)
📌 P-Tuning не изменяет веса модели, а добавляет обучаемые токены перед входным текстом.
🔹 Как работает?
- Добавляет обучаемые префиксные токены к входным данным.
- Эти токены корректируют работу модели без изменения ее структуры.
📌 Пример использования P-Tuning
🔹 Плюсы P-Tuning:
✅ Минимальные затраты по памяти и вычислениям
✅ Быстрое обучение
🔹 Минусы P-Tuning:
❌ Работает хуже на сложных задачах
❌ Ограниченная адаптация модели
1.4. Adapter Layers
📌 Adapter Layers – добавляют специальные обучаемые слои в модель.
🔹 Как работает?
- Вставляются небольшие обучаемые модули между слоями модели.
- Основные параметры остаются неизменными.
📌 Пример кода использования Adapter Layers
🔹 Плюсы Adapter Layers:
✅ Лучше сохраняет старые знания модели
✅ Гибкий механизм адаптации
🔹 Минусы Adapter Layers:
❌ Чуть больше затрат на вычисления, чем у LoRA
❌ Требует изменения структуры модели
2. Сравнение методов PEFT
Выводы
✅ LoRA – лучший вариант, если нужен баланс между качеством и экономией ресурсов.
✅ QLoRA – если у вас ограниченная память (8GB VRAM).
✅ P-Tuning – подойдет, если нужен максимально быстрый и дешевый вариант.
✅ Adapter Layers – лучше для глубокой адаптации модели.
🔹 Если у вас 8GB VRAM – выбирайте QLoRA.
🔹 Если есть 16GB+ VRAM – LoRA оптимальный вариант.
🎯 Выбор метода зависит от ваших задач, ресурсов и модели! 💡
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru