Выбор гиперпараметров и оптимизаторов для эффективного обучения
Введение
Fine-tuning больших языковых моделей (LLM) — сложный процесс, требующий тщательного подбора гиперпараметров и оптимизаторов. Выбор неправильных параметров может привести к недообучению (модель не адаптируется под задачу) или переобучению (модель запоминает обучающие данные, но плохо работает на новых).
В этой статье разберем:
- Как выбрать гиперпараметры для fine-tuning.
- Какие оптимизаторы лучше подходят для LLM.
- Как избежать переобучения и нестабильности обучения.
- Приведем примеры кода для настройки fine-tuning.
1. Основные гиперпараметры fine-tuning
Fine-tuning LLM требует настройки множества параметров, но ключевыми являются:
- Размер батча (batch size)
- Коэффициент обучения (learning rate)
- Количество эпох (epochs)
- Максимальная длина токенов (max sequence length)
- Градиентное накопление (gradient accumulation)
- Регуляризация (weight decay, dropout)
Разберем каждый из них подробно.
1.1. Размер батча (batch size)
🔹 Что это? Количество примеров, обрабатываемых за один шаг обновления весов модели.
🔹 Как влияет?
- Большой batch (16-64) → Быстрое и стабильное обучение, но требует больше VRAM.
- Маленький batch (1-8) → Экономия памяти, но обучение может быть нестабильным.
🔹 Как выбрать?
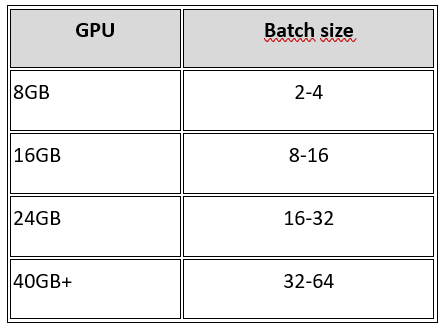
🔹 Решение при нехватке памяти: использовать градиентное накопление.
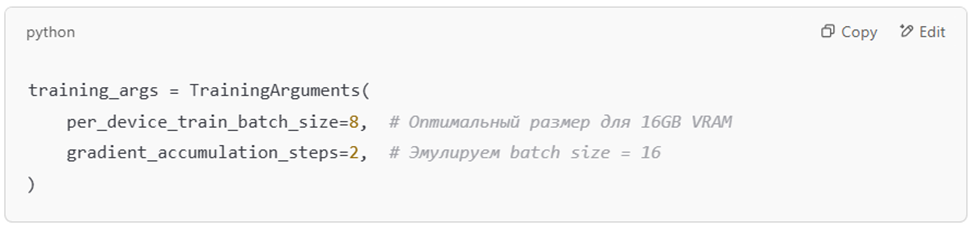
Пример настройки batch size:
1.2. Коэффициент обучения (learning rate, LR)
🔹 Что это? Определяет, насколько сильно обновляются веса модели при каждом шаге градиентного спуска.
🔹 Как влияет?
- Слишком высокий LR → модель может "перескакивать" оптимальное решение.
- Слишком низкий LR → модель будет обучаться слишком медленно или застрянет в локальном минимуме.
🔹 Рекомендации по LR:
Пример настройки LR:
1.3. Количество эпох (epochs)
🔹 Что это? Один полный проход по датасету.
🔹 Как влияет?
- Слишком мало эпох → недообучение.
- Слишком много эпох → переобучение.
🔹 Оптимальное количество эпох:
Пример настройки:
1.4. Градиентное накопление (gradient accumulation)
🔹 Что это? Позволяет имитировать большой batch size на GPU с ограниченной памятью.
🔹 Как выбрать?
- Если batch size = 8 и gradient_accumulation_steps = 4, то эффективный batch = 32.
Пример:
1.5. Регуляризация (weight decay, dropout)
🔹 Weight decay — предотвращает переобучение, добавляя штраф за большие веса.
🔹 Dropout — отключает случайные нейроны во время обучения, предотвращая переобучение.
Пример:
2. Выбор оптимизатора
Оптимизатор определяет, как обновляются веса модели.
Пример настройки AdamW:
3. Как избежать проблем при fine-tuning?
🔹 Переобучение → Использовать early stopping и weight decay.
🔹 Медленное обучение → Увеличить batch size и использовать адаптивный LR.
🔹 Нехватка памяти → Использовать LoRA, gradient accumulation и Adafactor.
Пример использования early stopping:
Выводы
🔹 Размер batch и LR — ключевые параметры.
🔹 Оптимальный оптимизатор — AdamW или Adafactor.
🔹 Регуляризация (dropout, weight decay) помогает избежать переобучения.
🔹 Градиентное накопление спасает от нехватки VRAM.
🚀 Fine-tuning LLM — это баланс между вычислительными ресурсами и качеством обучения. Грамотный подбор гиперпараметров и оптимизаторов — залог успешного обучения!
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/