Введение
Большие языковые модели (LLM) могут демонстрировать впечатляющие результаты в обработке естественного языка, но их знания ограничены моментом их обучения. В быстроразвивающихся областях, таких как медицина, финансы, юриспруденция и технологии, информация постоянно обновляется, а устаревшие данные могут привести к ошибкам.
📌 Проблемы традиционного обучения LLM:
1️⃣ Статичность знаний – модель не может учитывать новые законы, медицинские протоколы или научные открытия.
2️⃣ Большие вычислительные затраты – fine-tuning требует ресурсов, а частое переобучение невозможно в реальном времени.
3️⃣ Риск катастрофического забывания – при дообучении новая информация может вытеснить старые знания.
💡 Решение: Retrieval-Augmented Generation (RAG) и другие retrieval-based методы. Они позволяют обогащать LLM актуальными данными без необходимости переобучения всей модели.
1. Retrieval-based подходы для актуализации знаний
Что такое Retrieval-Augmented Generation (RAG)?
RAG — это метод, который сочетает поиск информации (retrieval) и генерацию текста (generation). Вместо того, чтобы полагаться только на внутренние знания модели, LLM обращается к внешним источникам, чтобы уточнить ответ.
🔹 Как это работает?
- 🔎 Retrieval: Поиск релевантных документов в базе знаний (например, векторного хранилища).
- 🤖 Generation: LLM использует найденные данные для генерации ответа.
📌 Преимущества RAG:
✅ Модель всегда использует актуальные данные без полного переобучения.
✅ Объяснимость – можно показать, на каких источниках основан ответ.
✅ Экономия ресурсов – обучение можно заменить обновлением базы знаний.
2. Построение retrieval-based системы для LLM
Шаг 1: Подготовка базы знаний
Перед обучением необходимо собрать актуальные отраслевые данные. Например:
- 📚 Медицина: базы данных PubMed, FDA, MIMIC-III.
- ⚖ Юриспруденция: судебные решения, законы, нормативные акты.
- 💰 Финансы: отчеты SEC, финансовые новости, исследовательские статьи.
Формат хранения данных:
- Текстовые документы (PDF, DOCX, TXT)
- SQL- или NoSQL-базы данных
- Векторные хранилища (FAISS, Chroma, Pinecone)
Шаг 2: Индексация данных с векторным поиском
Используем векторное представление текстов для быстрого поиска релевантной информации.
🔹 Пример кодовой реализации с FAISS:
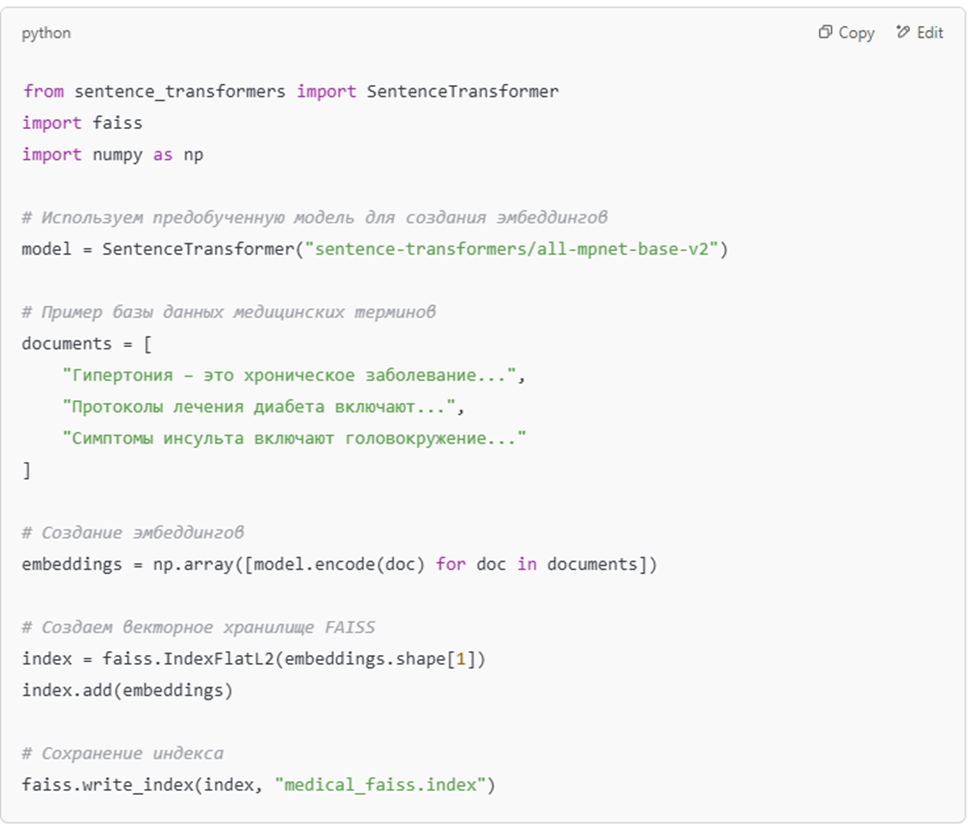
Шаг 3: Поиск информации в базе перед генерацией ответа
Теперь LLM может использовать базу знаний перед генерацией текста.
🔹 Пример поиска в FAISS:

Шаг 4: Интеграция retrieval в генерацию ответа LLM
Теперь мы передаем найденные документы в промпт LLM.
🔹 Пример интеграции с GPT:
✅ Теперь LLM отвечает, используя актуальную информацию из retrieval-хранилища.
3. Сравнение retrieval-based методов с fine-tuning
4. Примеры использования retrieval-based обучения в разных сферах
📌 Медицина:
🔹 Автоматический анализ новых клинических исследований.
🔹 Обновление медицинских рекомендаций в реальном времени.
📌 Юриспруденция:
🔹 Поиск актуальных законов и судебных решений.
🔹 Поддержка юридических консультаций на основе последних правовых норм.
📌 Финансы:
🔹 Мониторинг экономических отчетов и финансовых прогнозов.
🔹 Анализ последних изменений в налоговом законодательстве.
📌 Технологии и наука:
🔹 Поиск свежих публикаций в arXiv и IEEE.
🔹 Автоматический анализ патентных заявок.
Выводы
✅ Retrieval-based методы (RAG, FAISS, Pinecone) позволяют LLM использовать актуальные данные без переобучения.
✅ Векторные базы данных позволяют эффективно искать информацию, снижая нагрузку на вычисления.
✅ Сочетание retrieval и LLM особенно полезно в сферах, где знания быстро устаревают.
Вывод: Retrieval-based обучение — наиболее эффективный способ адаптации LLM к отраслевой терминологии в реальном времени. 🚀
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Использование LoRA и других методов адаптации без полного fine-tuning: сравнение LoRA, QLoRA, P-Tuning, Adapter Layers- https://dzen.ru/a/Z6sPdqyfbxrSAAyZ
Тонкости fine-tuning LLM: стратегии и лучшие практики- https://dzen.ru/a/Z6sMG0FvPVkTx6K4
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru