1. Введение
Большие языковые модели (LLM) доказали свою эффективность в широком спектре задач: от генерации текста до сложного анализа данных. Однако их размер, потребление ресурсов и сложность развертывания делают их неоптимальными для специализированных приложений с узкими требованиями.
⚡ Альтернатива – малые языковые модели (SLM, Small Language Models), которые:
✔️ Имеют меньший размер (до 3B параметров)
✔️ Работают быстрее и требуют меньше ресурсов
✔️ Легко кастомизируются для конкретных отраслей
📌 В этой статье рассмотрим, почему SLM становятся важным элементом будущего кастомизации, их преимущества и примеры использования.
2. Проблемы больших языковых моделей (LLM) в узких задачах
Хотя LLM (например, GPT-4, LLaMA 2, Gemini) справляются с широким спектром задач, у них есть существенные ограничения:
❌ Огромные вычислительные затраты – запуск модели на уровне 7B+ параметров требует дорогих серверов (A100, H100).
❌ Высокая латентность – генерация ответа занимает больше времени из-за сложных вычислений.
❌ Сложность кастомизации – дообучение LLM требует больших объемов данных и ресурсов.
❌ Проблемы с приватностью – хранение и обработка данных на внешних API несет риски безопасности.
Вывод: для узких задач LLM избыточны, и не всегда оправданы с точки зрения затрат и скорости.
3. Что такое малые языковые модели (SLM)?
SLM – это компактные языковые модели, специально оптимизированные под конкретные задачи. Они имеют от 100M до 3B параметров и могут эффективно работать на локальных серверах или даже на мобильных устройствах.
🔹 Основные преимущества SLM:
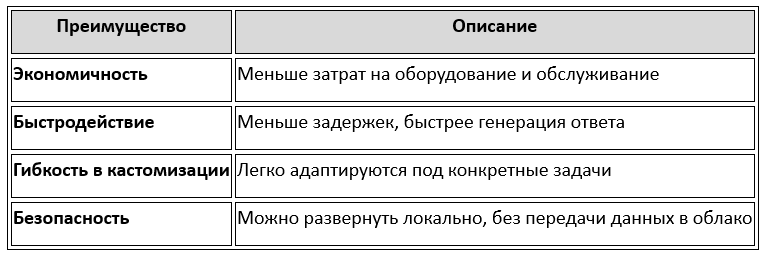
🔹 Технические отличия SLM от LLM

4. Где малые языковые модели полезнее больших?
🔹 4.1. Специализированные отрасли
SLM идеально подходят для задач, требующих глубокого понимания узкоспециализированных данных.
📌 Примеры:
✅ Медицина: обработка медицинских записей, анализ симптомов
✅ Юриспруденция: обработка контрактов, анализ юридических документов
✅ Финансы: автоматизированный анализ отчетности, прогнозирование
✅ Техническая документация: интерпретация сложных спецификаций
🔹 4.2. Локальное развертывание и защита данных
🔐 Банки, госструктуры, медицинские учреждения не могут передавать данные в облако.
📌 SLM позволяет развернуть модели локально, сохраняя конфиденциальность информации.
🔹 4.3. Встроенные решения и edge-компьютинг
📱 Малые модели можно запускать прямо на устройствах (смартфоны, встраиваемые системы, IoT).
📌 Пример:
- Автомобильные голосовые ассистенты
- Переводчики в режиме офлайн
- Распознавание команд в умных домах
5. Методы кастомизации SLM
🔹 5.1. Fine-tuning на небольших датасетах
Можно быстро дообучить SLM на 50K–100K примерах и получить высокую точность на узких задачах.
📌 Пример кода на Hugging Face (Fine-tuning GPT-2 на юридических текстах):
🔹 5.2. LoRA / QLoRA для экономии ресурсов
Позволяет адаптировать модель, не обновляя все веса, что снижает затраты на обучение в 10–20 раз.
🔹 5.3. RAG (Retrieval-Augmented Generation)
SLM можно комбинировать с retrieval-механизмами, чтобы получать актуальные данные из базы знаний в реальном времени.
📌 Пример: в финансовой аналитике SLM может искать последние новости перед генерацией прогноза.
6. Будущее малых языковых моделей
🚀 Тренды развития SLM:
✔️ Модели с 1B–3B параметров станут стандартом для узких задач
✔️ Рост популярности гибридных методов (SLM + retrieval-based approaches)
✔️ Оптимизация для edge-вычислений (работа на мобильных устройствах, IoT)
✔️ Интеграция с онтологическими знаниями для объяснимого ИИ
7. Выводы
✔️ SLM – это новый тренд кастомизации LLM для узких задач.
✔️ Малые модели выигрывают в скорости, экономичности и гибкости.
✔️ Они подходят для локального развертывания и защиты данных.
✔️ Будущее – за адаптивными моделями, интегрированными в бизнес-процессы и устройства.
📌 Вывод:
LLM остаются мощным инструментом, но SLM – это практичное решение для бизнеса, позволяющее сэкономить ресурсы и ускорить внедрение ИИ. 🚀
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Использование LoRA и других методов адаптации без полного fine-tuning: сравнение LoRA, QLoRA, P-Tuning, Adapter Layers- https://dzen.ru/a/Z6sPdqyfbxrSAAyZ
Тонкости fine-tuning LLM: стратегии и лучшие практики- https://dzen.ru/a/Z6sMG0FvPVkTx6K4
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/