1. Введение
Кастомизация больших языковых моделей (LLM) требует использования специализированных датасетов. Однако при их сборе и использовании компании сталкиваются с серьезными юридическими и этическими вопросами:
✅ Авторское право – можно ли использовать защищенные авторским правом тексты?
✅ Лицензирование – какие лицензии разрешают обучение моделей?
✅ Этика – справедливо ли обучать LLM на чужом контенте без согласия авторов?
В этой статье разберем ключевые юридические и этические аспекты кастомизации LLM и дадим рекомендации по работе с данными.
2. Авторское право и использование данных
2.1. Что защищено авторским правом?
🔹 Авторское право распространяется на:
- Книги, статьи, научные исследования
- Программный код, базы данных
- Медиафайлы (изображения, видео, музыка)
🔹 НЕ защищено авторским правом:
- Факты и идеи (но их выражение в тексте – да)
- Документы госорганов (в большинстве стран – общественное достояние)
- Материалы с истекшим сроком защиты (например, тексты до 1924 года в США)
💡 Вывод: нельзя просто взять контент из интернета и использовать его для обучения LLM без проверки его статуса.
2.2. Юридический статус использования защищенных данных
Использование защищенного авторским правом контента для обучения LLM находится в серой зоне. Основные аргументы:
🔹 В пользу использования:
✅ В США есть доктрина "fair use" – ограниченное использование материалов без разрешения, если оно не наносит вред правообладателю.
✅ В ЕС и других странах – возможны исключения для научных исследований и разработки ИИ.
🔹 Против использования:
❌ Обучение LLM – это не просто чтение, а создание производного продукта (генерируемого контента).
❌ Если LLM может воспроизвести исходный контент, это нарушение авторского права.
💡 Рекомендация: использовать разрешенные источники данных (см. раздел 3).
3. Лицензирование датасетов
3.1. Открытые лицензии
При использовании данных для кастомизации LLM важно учитывать их лицензионные условия.
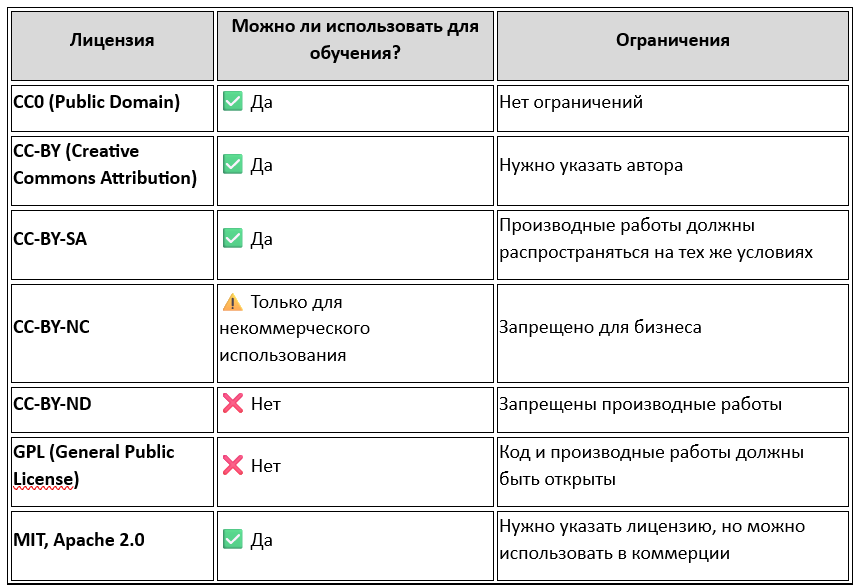
💡 Вывод: безопаснее всего использовать CC0, CC-BY и MIT/Apache лицензированные данные.
3.2. Коммерческие лицензии и закрытые данные
Некоторые компании продают лицензии на использование их данных для обучения LLM:
✅ Пример: лицензированные датасеты
- BloombergGPT – обучен на финансовых данных, доступ только по лицензии
- PubMed – медицинские тексты, доступны для академического использования
- LexisNexis, Westlaw – юридические базы данных (платный доступ)
💡 Рекомендация: если бизнесу нужны качественные отраслевые данные – лучше купить лицензию, чем использовать "серый" контент.
4. Этические аспекты кастомизации LLM
4.1. Проблема согласия авторов
Одно из главных этических возражений против использования данных для LLM – отсутствие согласия авторов.
❌ Авторы создают контент, но не получают компенсации, если их работы используются для обучения модели.
❌ Контент может использоваться против воли создателя (например, журналисты против автоматической генерации новостей).
💡 Этическая альтернатива: создать открытые платформы с вознаграждением за использование контента.
4.2. Проблема предвзятости (bias)
Если датасеты содержат искаженную информацию (например, расовые, гендерные стереотипы), LLM будет воспроизводить эти предубеждения.
✅ Способы борьбы с bias:
- Использовать разнообразные источники данных
- Применять фильтрацию токсичного контента
- Настраивать пост-обучение с человеческой обратной связью (RLHF)
💡 Вывод: датасеты нужно проверять не только на законность, но и на этичность.
5. Рекомендации по безопасному использованию данных
✅ Что можно использовать?
✔ Датасеты с CC0, CC-BY, Apache, MIT лицензиями
✔ Открытые источники (например, Wikipedia, ArXiv, OpenSubtitles)
✔ Данные, собранные с согласия пользователей
❌ Чего избегать?
✖ Копирование контента без лицензии
✖ Использование коммерческих баз данных без разрешения
✖ Тренировка LLM на конфиденциальных данных без защиты
🔹 Как минимизировать юридические риски?
✔ Использовать юридически чистые датасеты
✔ Подписывать лицензионные соглашения с правообладателями
✔ Документировать источник и лицензию каждого используемого датасета
6. Выводы
🔹 Авторское право – использование защищенных данных без разрешения может быть незаконным.
🔹 Лицензирование – проверяйте условия лицензий перед обучением LLM.
🔹 Этика – важно учитывать согласие авторов и избегать bias в данных.
💡 Главный вывод: бизнесу выгоднее работать с лицензированными и открытыми источниками, чем рисковать нарушением закона. 🚀
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Использование LoRA и других методов адаптации без полного fine-tuning: сравнение LoRA, QLoRA, P-Tuning, Adapter Layers- https://dzen.ru/a/Z6sPdqyfbxrSAAyZ
Тонкости fine-tuning LLM: стратегии и лучшие практики- https://dzen.ru/a/Z6sMG0FvPVkTx6K4
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru