1. Введение
Интеграция кастомизированных LLM (Large Language Models) в бизнес-процессы позволяет автоматизировать задачи, улучшить качество обслуживания клиентов и повысить эффективность обработки информации. Однако ключевые вызовы, с которыми сталкиваются компании, – оптимизация скорости работы и снижение затрат.
В этой статье разберем стратегии ускорения работы LLM, методы уменьшения затрат на развертывание, техники сжатия моделей и лучшие практики инфраструктуры.
2. Оптимизация скорости работы LLM
Быстродействие LLM критично в реальных бизнес-приложениях, особенно для задач, требующих немедленного отклика (например, чат-боты, голосовые помощники, системы рекомендаций).
2.1. Выбор архитектуры и уменьшение вычислительной нагрузки
- Компактные модели – Использование LLM меньшего размера (например, Mistral 7B вместо Llama 70B).
- Distillation (дистилляция) – Перенос знаний из большой модели в меньшую (например, TinyBERT).
- Sparse Attention – Модели с разреженным вниманием ускоряют обработку длинных контекстов (например, BigBird).
🔹 Пример использования DistilBERT вместо GPT-3

2.2. Кеширование и оптимизация вычислений
Кеширование ускоряет работу модели за счет повторного использования ранее вычисленных результатов.
🔹 Техники кеширования
- KV-кеширование – Сохранение скрытых состояний модели (используется в GPT-4 Turbo).
- Faiss для быстрого поиска эмбеддингов – Ускоряет RAG (Retrieval-Augmented Generation).
- ONNX Runtime и TensorRT – Оптимизируют работу LLM на GPU.
🔹 Пример оптимизации с ONNX
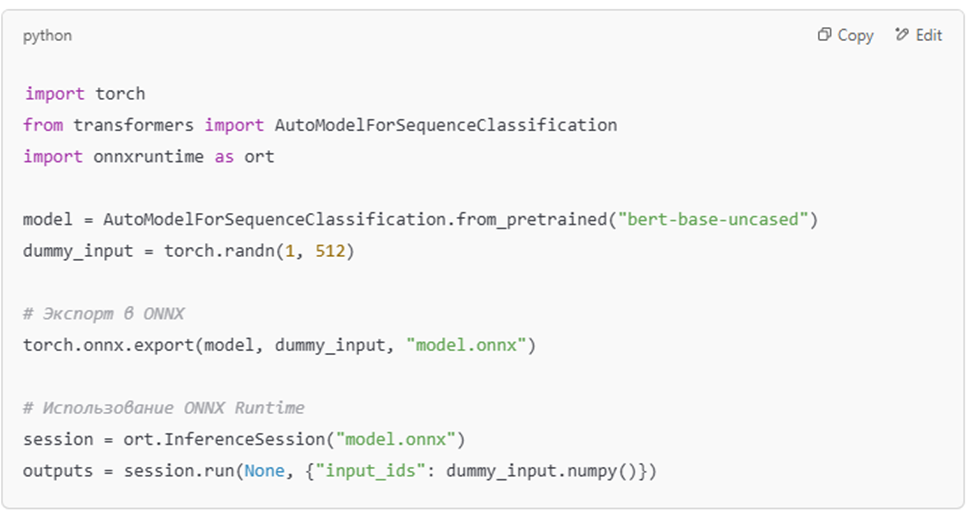
💡 Рекомендация: Используйте ONNX Runtime или TensorRT для ускорения работы LLM на GPU.
2.3. Модели с квантованием (Quantization)
Квантование уменьшает размер модели и ускоряет вычисления, переводя параметры модели в более низкую разрядность (8-bit, 4-bit).
🔹 Методы квантования
🔹 Пример квантования с BitsAndBytes
💡 Рекомендация: Используйте QLoRA и GPTQ для уменьшения размера модели и ускорения работы.
3. Оптимизация стоимости использования LLM
Запуск больших моделей требует значительных ресурсов, что может быть дорого для бизнеса.
3.1. Выбор между облачными и локальными серверами
🔹 Оптимизация облачных затрат
- Spot-инстансы (AWS EC2 Spot, GCP Preemptible) – снижение цен до 70%.
- Serverless inference (Amazon SageMaker, Google Vertex AI) – плата только за запросы.
💡 Рекомендация: Используйте гибридный подход – облако для масштабирования, локальные серверы для конфиденциальных данных.
3.2. Адаптивные методы обучения (LoRA, PEFT)
Вместо полного fine-tuning, используйте адаптивное обучение.
🔹 Сравнение затрат на обучение
💡 Рекомендация: Для экономии используйте LoRA или QLoRA вместо полного fine-tuning.
3.3. Использование серверов с оптимальной конфигурацией
🔹 Рекомендованные GPU
💡 Рекомендация: Используйте A100/H100 в облаке или RTX 4090 для локального развертывания.
4. Выводы и рекомендации
📌 Как ускорить LLM?
✅ Использовать DistilBERT, Sparse Attention, Distillation
✅ Применять ONNX, TensorRT, кеширование
✅ Использовать квантование (QLoRA, GPTQ)
📌 Как снизить затраты?
✅ Выбирать облачные решения (Spot-инстансы, Serverless)
✅ Применять LoRA, QLoRA вместо полного fine-tuning
✅ Использовать оптимизированные GPU (A100, H100, RTX 4090)
💡 Главный совет: комбинируйте ускорение вычислений и снижение затрат, чтобы получить максимальную эффективность при использовании кастомизированных LLM. 🚀
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Использование LoRA и других методов адаптации без полного fine-tuning: сравнение LoRA, QLoRA, P-Tuning, Adapter Layers- https://dzen.ru/a/Z6sPdqyfbxrSAAyZ
Тонкости fine-tuning LLM: стратегии и лучшие практики- https://dzen.ru/a/Z6sMG0FvPVkTx6K4
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru