В бакалавриате у нас был очень интересный и разнообразный курс по программированию. Если точнее это была серия курсов, каждый год мы осваивали какие-то новые алгоритмы и сдавали свои имплементации задач (работали на C++), причем каждому студенту случайным образом назначалась своя задача из большого перечня, связанного одной темой, и на длительный срок (несколько месяцев) учащийся был «заперт» наедине со своим заданием. Приходилось изучать литературу, учебный форум, общаться с кураторами посредством переписки и пытаться хоть как-нибудь продвинуться. На мой взгляд этот формат работы хорошо формирует навык искать решение даже в тех условиях, когда непонятно где, собственно говоря, искать. В ход шел весь доступный арсенал — где-то можно было усмотреть хорошую подсказку в переписке на форуме у других студентов, где-то можно было спросить совета у старшекурсников, но чаще всего если уж вообще никак не находилось решений самостоятельно, можно было обратиться напрямую к преподавателям и получить указания. В общем, оглядываясь назад могу сказать что мне очень было полезно, хотя я часто психовал когда в сотый раз задача не проходила тесты и приходилось медитировать на код и искать где же «косяк».
Не вспомню точно в котором семестре, но мне выпала задача написать свой движок для искусственного интеллекта игры Гомоку. Гомоку это знакомая многим игра «пять в ряд». На поле фиксированного размера 15x15 выставляются черные и белые фишки двумя игроками по очереди, и задача каждого игрока — выстроить пять фишек своего цвета в ряд по горизонтали, вертикали или диагонально. У задачи были формальные критерии (какой движок считался адекватным) и я точно помню что мое решение было из рук вон — сильно был загружен другими предметами и Гомоку писал спустя рукава. Обиднее всего было то, что под занавес семестра, когда задачу надо было уже защищать, у меня наконец-то появился к ней настоящий интерес. Я откопал научную статью на тему и уже намеревался как порядочный студент все переделать по человечески за одну ночь, но не вышло. Задачу я кое-как со скрипом сдал, но осадочек остался, и всё хотелось вернуться к теме в свободное время. В итоге добрался только сейчас (плюс-минус десять лет прошло) когда уже начисто забыл и как реализовывал логику и что задумывал. Поэтому просто решил написать с нуля и немного поковыряться в теме игровых движков с чистого листа (написать свои велосипеды). О таком моём велосипеде в статье и пойдет речь.
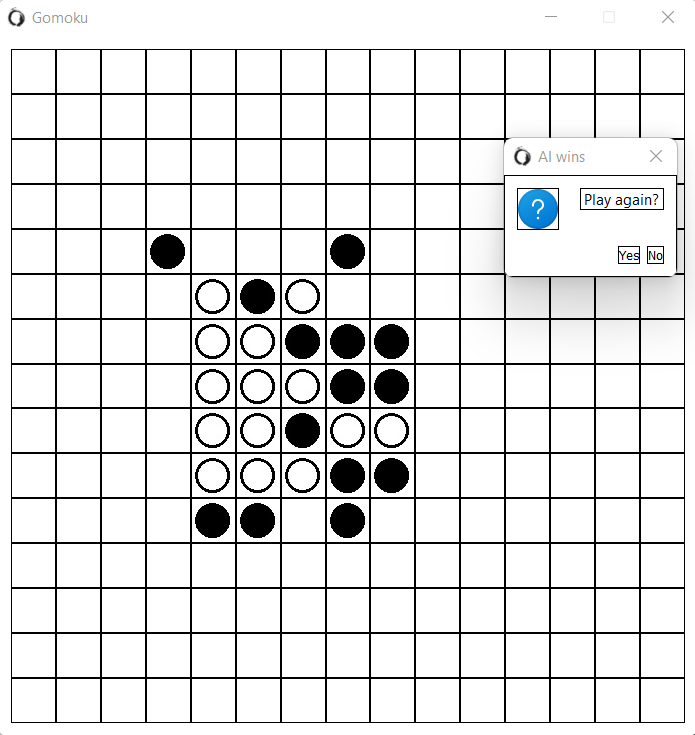
Хочется сразу оговориться что речь в статье пойдет о плохом решении, а есть хорошие. Как оказалось, черные всегда могут победить в классических правилах, поэтому с научной точки зрения интереса особо нет - бери себе готовые стратегии и побеждай. Мне же просто хотелось поковыряться с давно мною забытыми классическими знаниями и алгоритмами, о которых я немного и хочу рассказать. А начнем с пересказа принципов алгоритма minimax. Опираться в своем описании буду на вот эту очень толковую заметку.
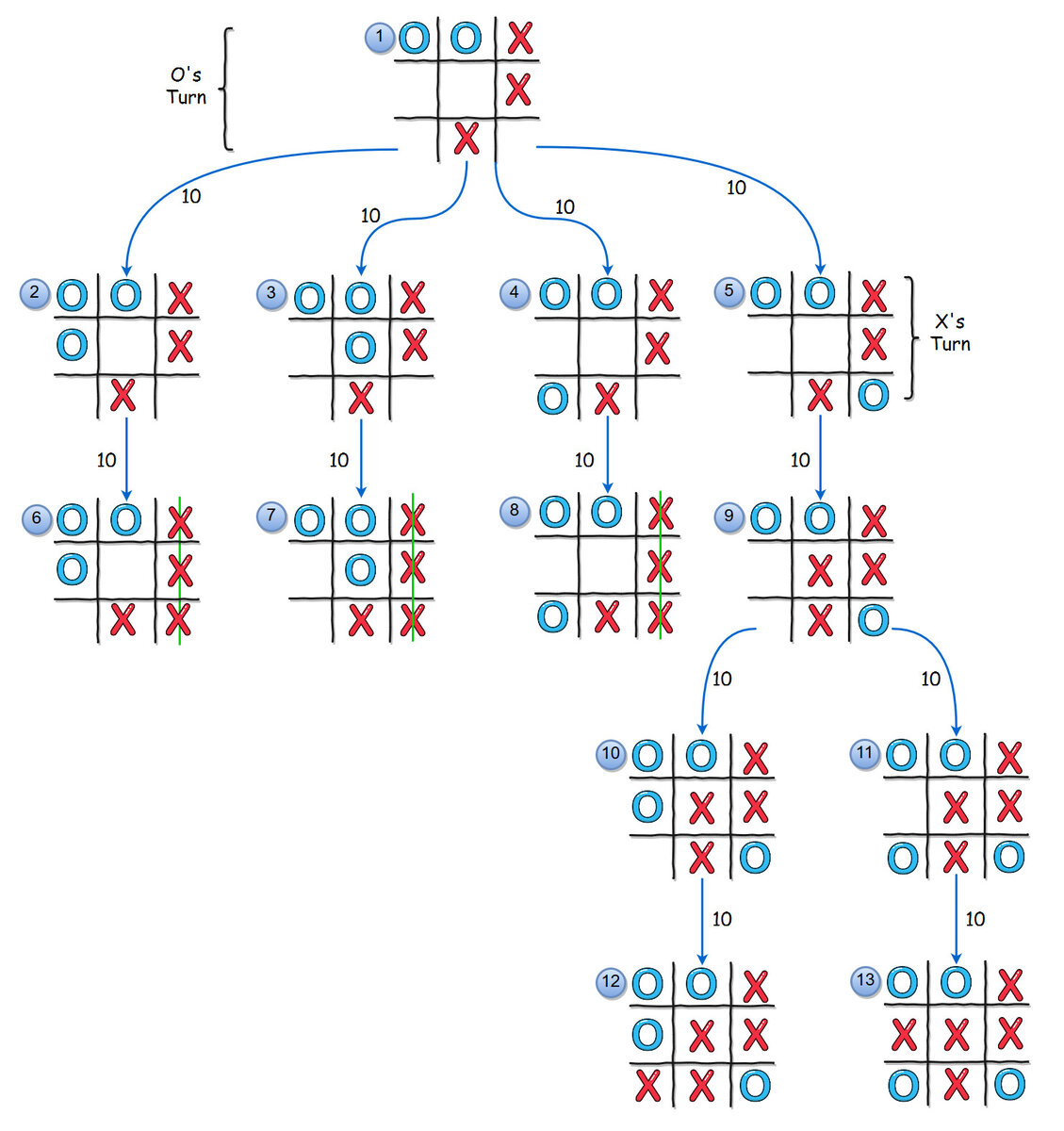
По существу minimax представляет игру как дерево состояний доски. Каждая вершина дерева это новое состояние игры, например новая фишка на поле меняет конфигурацию доски и порождает новое состояние. Поскольку игроки ходят по очереди пути в дереве всегда чередуют ходы игроков. Начинать рисовать дерево можно из любого состояния доски, а количество дочерних вершин у всякой вершины равно количеству возможных допустимых ходов оппонента, которые можно совершить из конфигурации, которую означает эта вершина. В этой заметке довольно неплохо изобразили кусочек дерева для игры в классические крестики-нолики(три в ряд):
Если бы у нас был идеальный компьютер с бесконечной памятью, способный обрабатывать очень большое(читай — неограниченное) количество операций в секунду, не составило бы труда написать искусственный интеллект для идеального игрока, который всегда будет играть по выигрышной стратегии, если в игре такая стратегия есть. Такая программа строила бы подобное дерево до тех пор, пока все варианты не были бы разобраны, и всегда вела бы себя оптимальным образом. Наличие выигрышной стратегии для черных означало бы что мы всегда можем найти последовательность ходов начиная с пустой доски, что при любых ходах белых победа будет за первым игроком — но просто взглянув на дерево игры это не понятно, необходимо эту информацию как-то приписать вершинам, то есть сделать так, чтобы каждая вершина обладала информацией о том, есть ли «под ней» выигрышный маршрут для данного типа вершины. Тут в ход и вступает простейший minimax, а выглядит он примерно так, как показано ниже. Смысл, я надеюсь, будет ясен из комментариев к коду, пример расписан для случая когда игрок ходит первым (за «черных»), а компьютер ему противостоит (ходит за «белых»):
Есть несколько нюансов, которые необходимо дополнительно прокомментировать в этом коде:
- Это рекурсивная процедура, а значит она потенциально может быть опасна если мы не понимаем какая будет глубина рекурсии. Несложно понять, что если мы говорим о гомоку то верхней оценкой числа дочерних вершин будет размер доски — 225 значений. Это число, конечно, со временем уменьшается, но в общем перебор растёт по экспоненте с ужасающей скоростью. А внутри каждого прохода еще зашиты какие-то вычисления, и не одно... Кажется что ни один реальный компьютер такого расчета на текущий момент долго не выдержит.
- В представленном листинге определенная сложность завуалирована и прикрыта красивыми надписями. К примеру, в коде присутствует загадочная функция evaluate которая оценивает состояние доски и возвращает число. Без дополнительных разъяснений совсем не ясно как получается это число и какая сложность у процедуры evaluate.
- Функции getChilrenConfiguration и isLeaf интуитивно кажутся понятными, но в реальности это может быть тоже довольно сложным расчетом, который мы просто скрыли за красивым названием. Про метод type такого, пожалуй, не скажешь — хотя никто не пояснял как представлена вершина в дереве(node).
- Как мы видим, некоторая условная положительная бесконечность (MAX_VALUE) будет означать победу черных, условная отрицательная бесконечность (MIN_VALUE) означает победу белых. В промежутке между этими числами есть ещё какие-то значения, которые по возможности должны отражать «выгоду» от той или иной позиции для того или иного игрока (например, чем величина больше, тем больше шансов на победу у «черных»). Зачем нам это нужно станет ясно чуть позже, когда мы начнем справляться со сложностями из пункта 1.
Хочется верить что главную идею удалось проиллюстрировать. Как же теперь быть с тем, что компьютер у нас совсем не идеальный, а вполне себе реальный? Один из доступных вариантов — искусственно ограничить глубину рекурсии у нашей процедуры. Тогда мы, конечно же, гарантированно выигрышную стратегию не сможем найти, но в «будущее» заглянем(потому что мы не только лишь все):
Здесь нет почти ничего нового кроме переменной depth, которая выступает счетчиком для глубины рекурсии и не позволяет нам слишком долго обрабатывать запрос. Мы теряем в точности, но выигрываем во времени. Можно ли как-то еще ускориться? Оказывается что да:
Этот код чуть похитрее, здесь появляются переменные min и max которые служат пороговыми значениями при переборе. Если мы видим что некоторая оценка выходит за границы допустимого интервала отсечений мы прекращаем перебор и возвращаем само отсечение. Если данный листинг не до конца понятен то это норма отсылаю вас к примеру в оригинальной заметке, он очень хорошо все иллюстрирует. Такие отсечения не всегда ускоряют работу, все зависит от порядка обхода дочерних вершин.
Хорошо, общая часть в целом сейчас должна быть уже ясна. А как же выглядит minimax в моём коде? Достаточно заглянуть в этот файл и отыскать там такие строчки:
Ну, что-то похожее на minimax тут проглядывается... Есть и рекурсия, и отсечения, и даже какой-то evaluate. Для чего же вся остальная машинерия?
- Бросается в глаза что помимо значения оценки доски я возвращаю еще и глубину. У меня в коде это сделано для того, чтобы среди одинаковых выигрышных последовательностей выбирать ту, которая находится менее глубоко — скорее всего это неверный подход и можно сделать лаконичнее, но мне так было проще и я махнул рукой.
- В minimax я помимо всего прочего передаю некоторую переменную last_moves и флаг only_closest который по умолчанию установлен в True. С флагом на самом деле все довольно очевидно — при переборе дочерних вершин я не хочу оценивать ходы, которые будут далеко на доске от уже проставленных фишек. Это эвристика, но она не лишена смысла. last_moves же хранит последовательность ходов, которые мы анализировали при спуске по этой ветке рекурсии. Я использую эту последовательность ходов для более скорой оценки доски.
И здесь возникает вопрос, как же нам оценивать доску? Здесь я просто пофантазировал и написал какую-то свою процедуру. Листинг её я приведу ниже, но для начала просто поясню словами:
Процедура «раскручивает» последовательность ходов, причем сами ходы у меня всегда временно сохраняются на доске при спуске по рекурсии, а потом очищаются обратно. Хранятся ходы в массиве self.board, причем значений в этом массиве может быть не более трех видов: 0, 1 и -1 (ход черных, ход белых, пустая клетка). Для каждого нового хода в последовательности last_moves мы ищем все цепочки того же цвета, которые проходят через этот ход, считаем их длину, оцениваем их «заблокированность» с обеих сторон и добавляем в величину оценки доски длину последовательности умноженную на мультипликатор, зависящий от флагов заблокированности. positive_directions это всего лишь пары векторов с положительными направлениями на доске (4 направления из 8 возможных). Вот такой получается код:
В общем-то выглядит как довольно простая штука, никакой сложной науки. В итоге у себя в проекте я завернул код в ipynb формат и в простенький GUI через PyQT5. По умолчанию в коде установлена глубина рекурсии 3, этого хватает чтобы программа работала достаточно шустро, но при этом с ней было интересно играть. Если увеличивать рекурсию то комфорт от игры теряется. Проблема, конечно же, в том что моя реализация совсем не оптимальная, да еще и на питоне, но я отвлекся на другие дела и увы... ¯\_(ツ)_/¯
Я думаю что однажды интерес снова проснется и я добьюсь лучшей производительности с текущим алгоритмом оценки доски или придумаю новый. Ещё я некоторое время заглядывался на обучение с подкреплением, но об этом позже, это уже совсем другая история.
Хочется верить что статья была интересна и познавательна!
Не стесняйтесь писать свои костыли реализации, это очень помогает лучше разобраться в теме. Желаю вам всегда отыскивать выигрышные стратегии!