Рассмотрим пример проблемы, возникающей в результате неаккуратной работы с индексами Pandas объектов. Пусть имеются две взаимосвязанные колонки ser1, ser2. Допустим, нам надо сэмплировать несколько строк из первой серии и упорядочить строки второй серии в том же порядке:
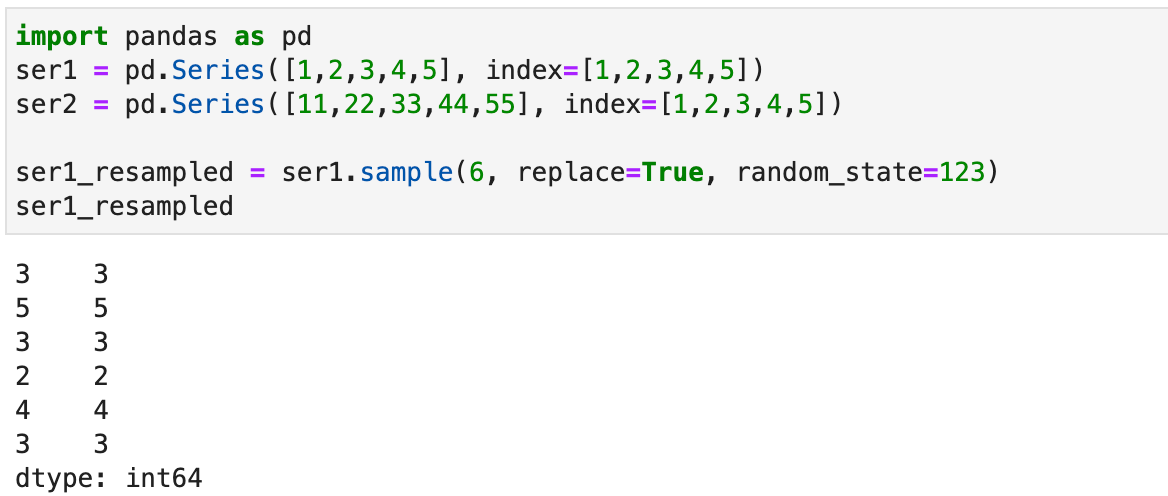
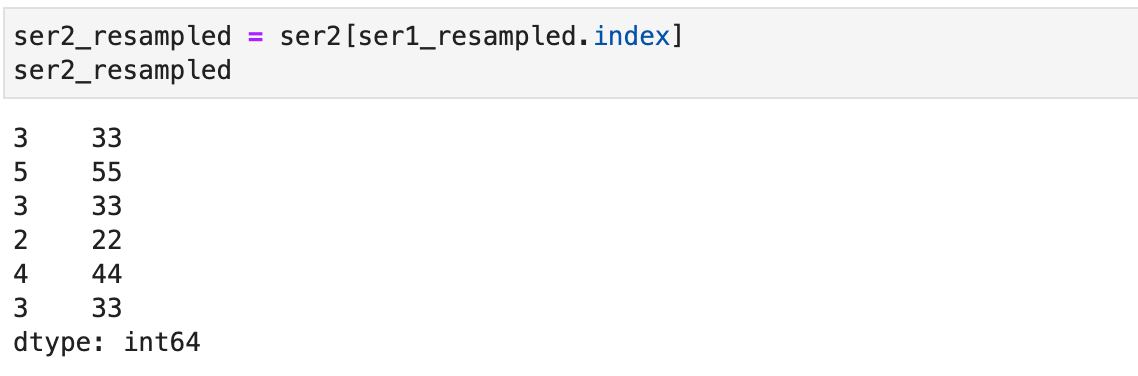
Как и ожидалось, появились повторяющиеся индексы. Обратите внимание на интересное поведение при обращении по ним:
То есть при обращении по повторяющемуся индексу вы получите кратное количество всех его вхождений.
Пусть теперь надо из ser1_resampled выбрать n строк в позициях с наибольшими значениями в ser2_resampled. На первый взгляд кажутся применимыми следующие два подхода:
- отсортировать ser2_resampled, затем выбрать индексы n первых строк и сделать выборку по ним;
- отсортировать ser2_resampled, проиндексировать ser1_resampled по индексам ser2_resampled и потом выбрать n первых элементов.
Однако из-за повторов в каждом из кейсов результат получится неожиданным:
То есть вместо ожидаемых 6 строк получили 12. А во втором случае получится так:
Оба варианта являются неправильными, так как у нас появились строки, отсутствовавшие в первоисточнике (например, стольких дублей троек не было). А корректно было сделать то же самое, только предварительно сбросив индексы:
Как видим, после этого оба подхода дают идентичный и ожидаемый результат.