#ai_inside #paper
Тут DeepMind выпустили сразу три статьи — и все про генеративные модели (GPT-3 like). Вот о чем понаписали в первой: (о второй и третьей — в следующих постах)
Статья #1. Обзор качества генеративных моделей в зависимости от их размера (кол-ва параметров) и Gopher
Мы привыкли считать, что чем больше нейросеть, тем лучше она работает (ну, при условии хорошего обучения). Самая большая версия GPT-3 имеет 175 миллиардов параметров и считается лучшей нейронкой для генерации текста. Кажется, чтобы сделать еще более крутую нейросеть для текстовых задач, нужно просто добавить еще параметров. Однако не все так однозначно.
Существуют разные виды задач, которые решаются NLP моделями вроде GPT-3: это и просто генерация текста, это question answering, классификация токсичного языка, факт-чекинг и т.д. И, оказывается, не для всех этих задач увеличение числа параметров сети делает качество сети лучше.
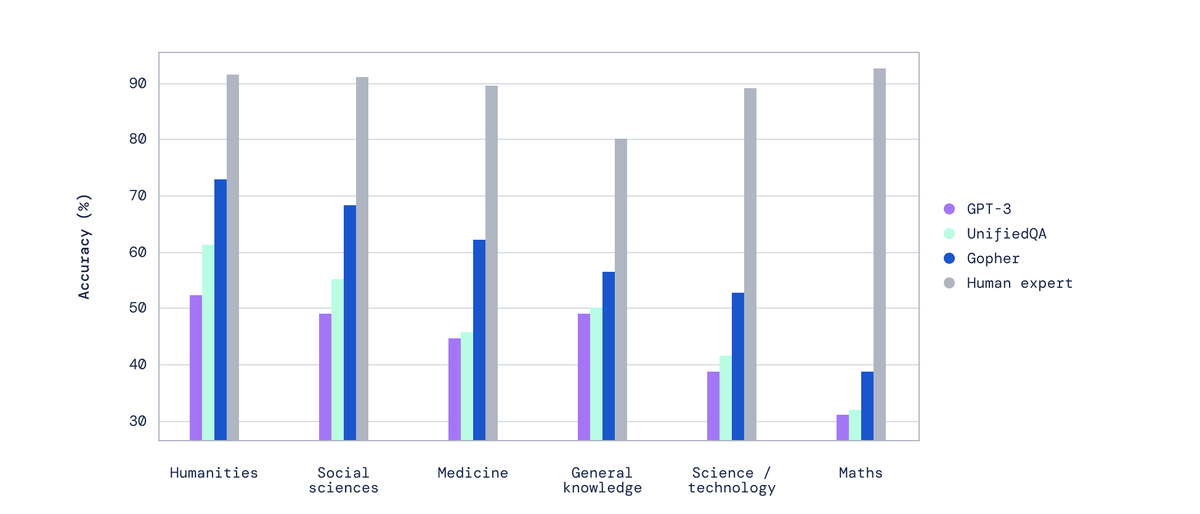
В DeepMind сравнили качество различных версий языковых моделей на различных задачах, связанных с пониманием текста. Среди моделей — нейросети с количеством параметров от 44 миллиона до 280 миллиардов. Выяснилось, что для каких-то задач действительно повышение количества параметров делает качество лучше: это задачи понимания смысла текста, факт-чекинга и определение токсичности текста. А вот для других задач — тех, в которых требуются логические рассуждения или здравый смысл — увеличение модели не помогает. Похоже, чтобы научить модель думать логически, тупо загрузить в модель больше данных и capacity не хватит: нужно что-то поумнее.
Нейросеть с 280 млрд параметров, кстати — новинка от DeepMind под названием Gopher. Теперь это самая большая языковая модель, больше, чем GPT-3. И Gopher — новая SOTA на ряде задач, в частности, на бенчмарке MMLU (это бенчмарк для сравнения крутости язвковых моделей; включает несколько задач, связанных с пониманием текстов и смыслов).
По тому, какие классные Gopher выдает ответы на вопросы в диалоге, похоже, что Gopher таки сместит GPT-3. На фото к посту — диалог человека с моделью, где разговор идет о биологии. Посмотрите, какие полные и верные ответы выдает модель!
Тем не менее, рисерчеры обращают внимание на то, что даже Gopher все еще далек от идеала: он все еще может выдавать ложные факты, токсичную речь и скатываться в режим "повторения". С логикой у Gopher также не лучше, чем у GPT-3 (собственно, как было сказано выше: с логикой увеличение размера сети не помогает)
Эти результаты о влиянии размера NLP моделей на их качество в различных задач, возможно, помогут исследователям не гнаться тупо за размерами моделей и попросту не жечь тонны часов GPU (и вредить экологии😡), а изобретать что-то более хитрое.
Блогпост DeepMind: https://www.deepmind.com/blog/language-modelling-at-scale-gopher-ethical-considerations-and-retrieval
Статья: https://storage.googleapis.com/deepmind-media/research/language-research/Training%20Gopher.pdf