В прошлой статье, посвящённой показателям разброса данных, среди прочих я приводил формулу среднеквадратического отклонения:
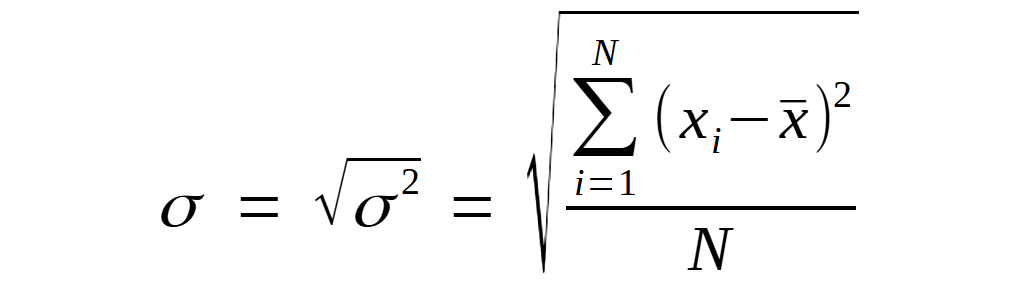
В ней оно равно квадратному корню из среднего квадрата отклонения величин от их среднего значения. С этой популярной формулой всё более-менее понятно: сначала мы рассчитываем отклонения от среднего для каждой точки, возводим их в квадрат (чтобы избавиться от отрицательных значений), определяем среднюю величину этих квадратов, а потом извлекаем из него корень.
Однако из памяти всплывает другая формула, более странная, в которой в знаменателе под суммой стоит не N, а N-1:
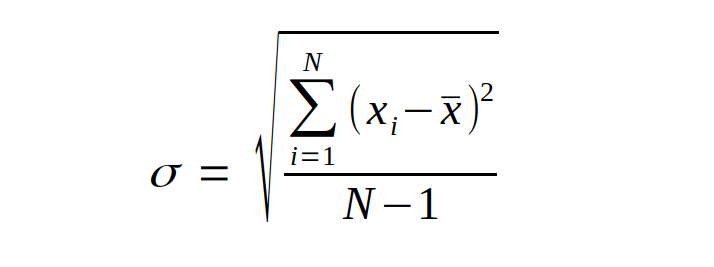
Более того, если мы попытаемся вычислить среднеквадратическое отклонение в Excel, то столкнёмся с двумя функциями:
= СТАНДОТКЛОН.В
и
= СТАНДОТКЛОН.Г
И даже ещё более того. Среднеквадратическое отклонение часто называют стандартным и даже применяют для этого разные буквы. Одно обозначают греческой буквой "сигма", а другое — латинской буквой s.
Так как для какой такое надобности появляется N-1, и какой вариант из двух формул является правильным?
Сам я не математик, поэтому попытаюсь пояснить на рабоче-крестьянском — кратко, но, как мне кажется, более понятно. Если объяснение покажется недостаточно "умным" или вы захотите ознакомиться с этой темой подробнее, погуглите "несмещённая оценка стандартного отклонения". А мы продолжаем.
Зайдём с философской стороны. В статье о целях сбора данных я упоминал о том, что одной из основных целей этого и вообще задач статистики являются принятие решений и прогнозирование. При этом и для одной, и для другой задачи мы, люди — существа ограниченные — в состоянии использовать в основном ограниченные же наборы данных.
Например, практически невозможно установить рост всех живущих на земле людей и разброс значений этого показателя. Практически невозможно (и нецелесообразно) выявлять политические предпочтения абсолютно всех избирателей. Нельзя измерить температуру воздуха в Воронеже 8 марта за все годы существования Воронежа включая будущие.
Задача статистики — сделать выводы на основе небольших выборок о свойствах генеральных совокупностей.
Итак, генеральная совокупность — это совокупность всех объектов, относительно которых предполагается сделать выводы. Выборка — это часть генеральной совокупности.
Генеральные совокупности имеют чёткие и однозначные свойства, которые "известны только Богу". Смертные же используют статистику, чтобы при помощи анализа выборок приблизиться к истинному пониманию этих "чётких и однозначных свойств".
Пример из жизни: вы собрали все до одной ягоды смородины с одного конкретного куста и хотите сделать заключение об их размере — средней величине и среднеквадратическом отклонении. В этом случае вам будет нужно измерить каждую из 2537 ягодок, которые и составляют генеральную совокупность плодов конкретного куста. Сделав это и применив формулу первую формулу из этой статьи (где в знаменателе N) вы получите среднеквадратическое отклонение генеральной совокупности и сможете почувствовать себя богом — данного конкретного куста смородины.
Однако на практике делать это нецелесообразно. Достаточно измерить размер небольшой выборки, например 20 или 30 ягод и получить относительно правильную оценку как средней величины, как и среднеквадратического отклонения.
Давайте так и сделаем: я создал файл в формате LibreOffice, котором привёл данные по размеру всех 2537 гипотетических ягод в миллиметрах. Файл можно скачать отсюда, а открыть — в Microsoft Excel.
Произведём расчёт среднеквадратического отклонения для первых 20 чисел сразу по двум формулам — для генеральной совокупности (заканчивается на .Г) и для выборки (заканчивается на .В). Их написание немного отличается для Microsoft Excel и LibreOffice Calc, а так как я давно перешёл на Linux, то все примеры делаю в LibreOffice:
Формула для генеральной совокупности — это первая формула в статье (в знаменателе N), для выборки — вторая (в знаменателе N-1). В связи с этим стандартное отклонение для выборки будет всегда больше, чем для генеральной совокупности.
Давайте посмотрим, что получилось.
Я, как "творец" этой последовательности из чисел, знаю, что среднеквадратическое отклонение генеральной совокупности равно 2,00, а средняя величина — 10,00 мм.
Во-первых, сразу видно что среднеквадратические отклонения как для генеральной совокупности, так и для выборки (1,72 и 1,76) отличаются от истинного (2,00). Если мы вычислим среднюю величину для той же выборки, то получим 9,55, что тоже, в общем, не идеально совпадает с 10,00. Это демонстрация недостатка понимания, который присущ "смертным". Чем больше значений мы добавим в выборку, тем более точным будет описание. Попробуйте убедиться в этом, использовав файл с примером или сгенерировав другую, достаточно большую последовательность случайных чисел.
Во-вторых, можно видеть, что значение стандартного отклонения выборки более близко к истинному, нежели оное для генеральной совокупности. И это не спроста. Именно стандартное отклонение выборки мы должны использовать в тех случаях, когда анализируем выборки и пытаемся на основе этого предсказать свойства генеральной совокупности. То есть, практически всегда.
Для иллюстрации двух вышеприведённых тезисов давайте разобьём совокупность на выборки по пять элементов. Мы должны увидеть две вещи:
- точность предсказания стандартного отклонения уменьшится;
- в большинстве случаев значения по формуле СТОТКЛ.В будут точнее, чем СТОТКЛ.Г.
Это и происходит, сравните с предыдущей картинкой:
Что в итоге и как всё-таки правильно?
- В подавляющем большинстве случаев на практике мы будем иметь дело со второй (N-1) формулой, которая описывает среднеквадратическое отклонение выборки.
- Среднеквадратическое отклонение генеральной совокупности применяется только тогда, когда мы владеем полной информацией о всех её элементах, поэтому использование данного показателя для прогноза и проверки гипотез некорректно.
- "Среднеквадратическое" и "стандартное" отклонения — это синонимы. Среднеквадратическое — это русское название, standard deviation пришло к нам из английского языка.
- Более правильно стандартное отклонение выборки называть "несмещённой оценкой стандартного отклонения", а генеральной совокупности — "смещённой".
- В старых книгах смещённая оценка (стандартное отклонение генеральной совокупности) обозначается греческой буквой "сигма", а несмещённая (стандартное отклонение выборки) — латинской буквой "s". Сейчас это различие в публикациях и материалах стирается, и я использую только "сигму".
- Обе оценки (и смещённая, и несмещённая) довольно близки и имеют один и тот же порядок. Чем больше выборка, тем меньше между ними разницы (сравните картинки со скриншотами LibreOffice).
На этом короткий рассказ о смородине и разных оценках стандартного отклонения закончен, если что-то показалось не очень понятным или некорректным — не стесняйтесь писать в комментариях.
Не забывайте подписаться канал "Иллюзия рациональности", который посвящён принятию обоснованных управленческих решений, его оглавление которого вы можете найти по данной ссылке.