Обучение с подкреплением отлично подходит для задач с четко определенной функцией вознаграждения, что подтверждается успешным опытом AlphaZero для Go, OpenAI Five для Dota и AlphaStar для StarCraft. Но на практике четко определить функцию вознаграждения не всегда возможно. Например, в простом кейсе уборки комнаты найденная под кроватью старая визитка или использованный билет на концерт могут представлять ценность и не должны быть выкинуты как мусор. Впрочем, даже если задать четкие критерии оценки анализируемого объекта, преобразовать их в вознаграждение не так просто: если вы даете агенту подкрепляющее его поведение вознаграждение каждый раз при сборе мусора, он может выбросить его назад, чтобы снова собрать и получить подкрепление.
Предупредить такое поведение AI-системы можно, формируя функцию вознаграждения на основе отзывов о поведении агента. Но этот подход требует много ресурсов: в частности, для обучения Deep RL-модели Cheetah от OpenAI Gym и MujoCo нужно около 700+ сравнений, проведенных человеком.
Поэтому исследователи калифорнийского университета Беркли David Lindner и Rohin Shah предложили алгоритм, который может без человеческого надзора или явно заданной функции, сформировать политику вознаграждения на основе неявной информации. Они назвали его RLSP (Reward Learning by Simulating the Past), т.к. подкрепляющее обучение формируется путем моделирования прошлого, на основе суждений, позволяющих агенту делать выводы о человеческих предпочтениях без явной обратной связи. Главная трудность масштабирования RLSP в том, как рассуждать о предыдущем опыте в случае множества данных. Авторы предлагают выбирать наиболее вероятные прошлые траектории развития событий вместо их полного перечисления, чередуя предсказание прошлых действий с предсказанием прошлых состояний, из которых эти действия были предприняты.
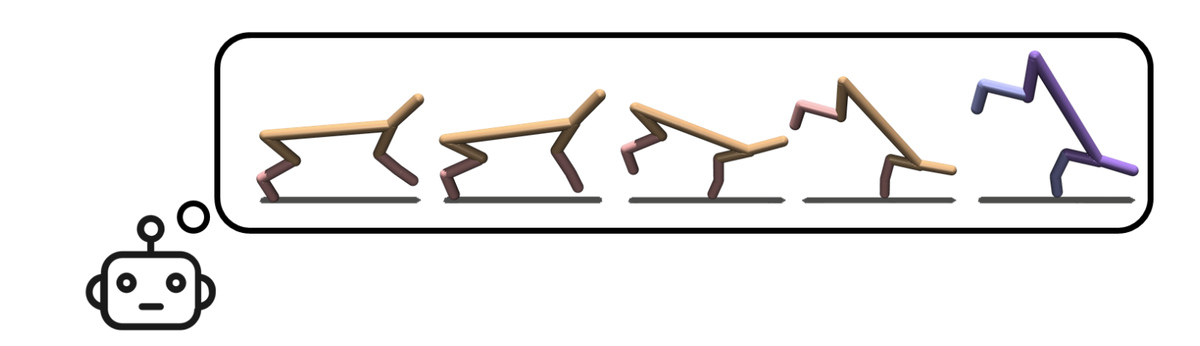
Алгоритм RLSP использует градиентный подъем для непрерывного обновления линейной функции вознаграждения для объяснения наблюдаемого состояния. Масштабирование этой идеи возможно через функциональное представление каждого состояния и моделирование линейной функции вознаграждения по этим характеристикам с последующей аппроксимацией градиента RLSP путем выборки более вероятных прошлых траектории. Градиент поощряет функцию вознаграждения, так что обратные траектории (что должно было быть сделано в прошлом) и прямые траектории (что агент сделал бы, используя текущее вознаграждение) согласовывались друг с другом. Как только траектории согласованы, градиент становится равным нулю, и становится известной функция вознаграждения, которая, вероятней всего, вызовет наблюдаемое состояние. Суть RLSP-алгоритма в выполнении градиентного подъема с использованием этого градиента. Алгоритм был проверен в симуляторе MujoCo – среде для тестирования RL-алгоритмов на задаче обучения смоделированных роботов двигаться по оптимальной траектории или наилучшим способом из возможных. Результаты показали, что сформированные RLSP политики подкрепления работают не хуже, тех, которые непосредственно обучены истинной функции вознаграждения.
https://bair.berkeley.edu/blog/2021/05/03/rlsp/