Рассмотрим, как быстро и красиво построить распределения значений для различных признаков таблицы данных. В качестве примера будем использовать датасет о цветках Ириса, который получим с помощью библиотеки Scikit-learn:
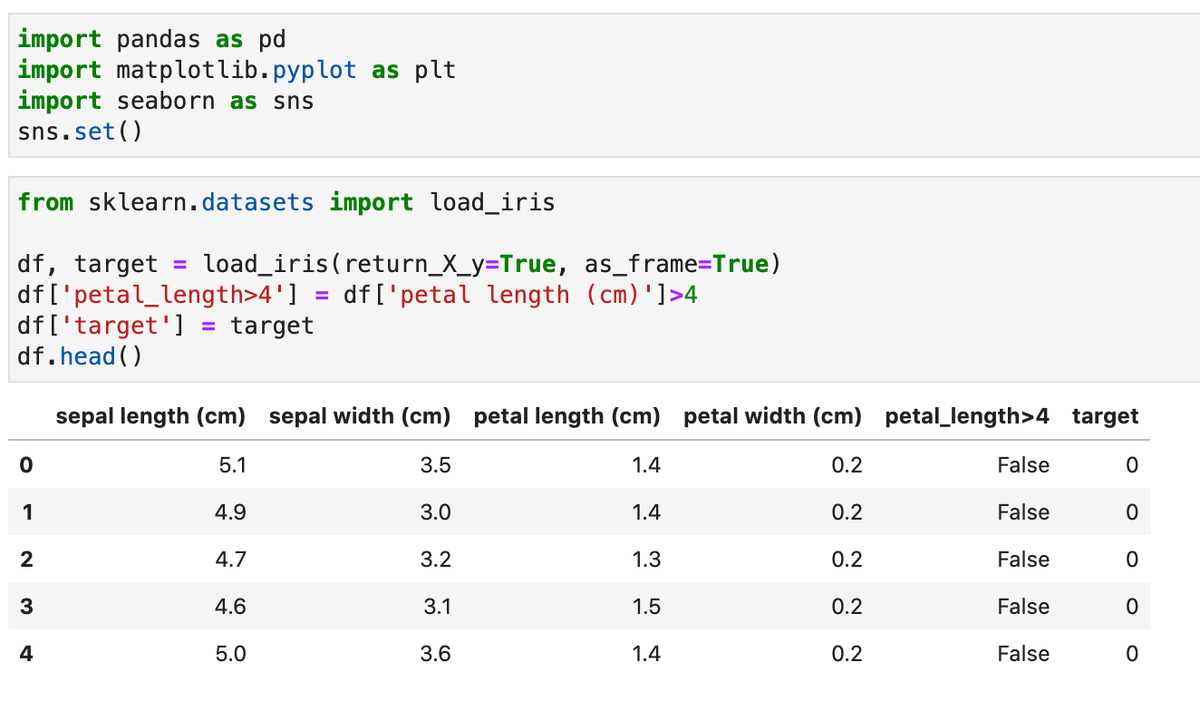
Как можно заметить, в демонстрационных целях мы добавили один индикаторный столбец - 'petal_length>4'. Визуализацию будем проводить с помощью библиотеки Seaborn, в которой для категориальных и числовых столбцов удобно использовать два разных метода countplot и histplot (читать подробнее). Поэтому сначала разделим наши признаки на группы по количеству уникальных значений (если их больше 10 считаем колонку числовой):

Разделив множество признаков, создадим полотно (подробнее здесь) с нужным количеством подграфиков и на каждом нарисуем подходящее распределение (с делением по значением target-а по параметру hue):