В следующем месяце, когда AMD выпустит ускорители Radeon 6000, противостояние между двумя производителям дискретных GPU развернется с новой силой, но уже сейчас очевидно, что NVIDIA сделала очень сильный первый ход. Конечно, поклонникам зеленой марки следовало охладить завышенные ожидания по поводу возможностей GeForce RTX 3080 — первой видеокарты нового семейства, представленной на суд публики. В реальных играх RTX 3080 оказался не настолько силен, как на презентациях чипмейкера, и тем не менее архитектура Ampere повлияла на производительность видеокарт NVIDIA сильнее, чем прорывной для своего времени Maxwell, а в бенчмарках при разрешении 4К или с трассировкой лучей приближается к эталонным достижениям Pascal. А главное, NVIDIA откорректировала ценовую модель RTX 20-й серии, которая не встретила горячего одобрения среди покупателей и, по сути, вынуждала делать апгрейд не ради производительности, не так уж сильно изменившейся по сравнению со старшими моделями GeForce 10 в пересчете на доллар стоимости, а исключительно ради новых функций рендеринга, связанных с аппаратной трассировкой лучей. И что по-настоящему обидно, игры с графическими эффектами на основе рейтрейсинга все еще можно пересчитать по пальцам.

Возможно, грядущие продукты AMD еще заставят нас увидеть Ampere в новом свете, но пока единственным поводом для недовольства новыми видеокартами является их ограниченная доступность и, как следствие, завышенные цены. Но если вдруг именно производительность GeForce RTX 3080 кажется недостаточной, а деньги — второстепенный вопрос, NVIDIA приберегла напоследок более убедительное предложение. Давайте выясним, на какого покупателя рассчитан беспрецедентно мощный (в плане и вычислительного потенциала, и энергопотребления) графический ускоритель, когда всю работу над ошибками прошлого поколения уже сделал, причем на твердую пятерку, RTX 3080.
_________________________________________________________________________________________
Технические характеристики GeForce RTX 3080
Мы посвятили отдельную статью подробному разбору графических процессоров Ampere, которые лежат в основе новых ускорителей NVIDIA, но для тех читателей, которые пропустили на данный момент самое значительное событие в IT-индустрии 2020 года и только сейчас познакомятся с 30-й серией GeForce, приведем краткое резюме основных характеристик графического процессора GA102 и двух старших моделей в линейке RTX 30.
Кристалл GA102 содержит рекордное для чипов потребительской направленности количество транзисторов (28 млрд) и по этому параметру является самым крупным ASIC, который производится в наши дни на коммерческой основе, после истинного флагмана архитектуры Ampere — GA100 (54 млрд). Однако GA100 зарезервирован ускорителями для дата-центров и совершенно не предназначен для игр. Прямой предшественник новинки, чип TU102 семейства Turing, который применяется в GeForce RTX 2080 Ti и TITAN RTX, содержит в полтора раза меньше транзисторов по сравнению с GA102. Тем не менее чипы Ampere отличаются меньшей площадью в пересчете на количество элементов по сравнению с Turing и повышенной энергоэффективностью благодаря миграции производства с 12-нанометрового конвейера TSMC на самсунговский техпроцесс 8 нм.
Структура полностью функционального кристалла GA102 представлена семью блоками GPC (Graphics Processing Cluster, крупнейшими масштабируемыми компонентами массива) вместо шести в составе TU102. Каждый из них по-прежнему содержит 12 потоковых мультипроцессоров (Streaming Multiprocessor), но одно из ключевых архитектурных отличий Ampere от Turing заключается в том, что массив 32-битных CUDA-ядер, обрабатывающих вещественные числа, внутри SM был удвоен. В результате формула главных исполнительных блоков GA102 включает 10 752 FP32-совместимых CUDA-ядра и 336 блоков наложения текстур.
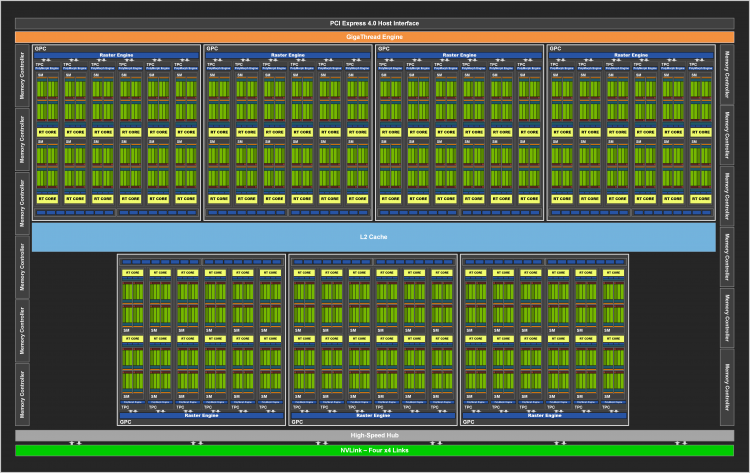
Однако GeForce RTX 3080 комплектуется существенно урезанной разновидностью GA102, в которой осталось только шесть действующих модулей GPC. Кроме того, два из них не полностью укомплектованы SM’ами. В итоге GeForce RTX 3980 располагает 8 704 шейдерными ALU для операций FP32 и 272 блоками наложения текстур. Но даже в таком виде GA102 располагает колоссальным потенциалом сырой вычислительной мощности по сравнению с топ-моделями 20-й серии. NVIDIA вернулась к практике, принятой в годы Kepler и Maxwell, когда ускорители с модельным номером на -80 или -80 Ti по рекомендованной розничной цене $649–699 были основаны на кремнии первого эшелона — в отличие от семейства Turing — и обеспечивали выгодное соотношение быстродействия в играх и цены.
Для тех, кому требуется максимальная производительность для рабочих задач или попросту хочется иметь самое лучшее железо, NVIDIA создала серию TITAN, но в этот раз появление такой видеокарты осталось под вопросом. Дело в том, что флагманский продукт основной линейки GeForce — RTX 3090 — по всем характеристикам близок к пределу возможностей чипа GA102. В кристалле деактивированы только 2 потоковых мультипроцессора, которые в общей сложности содержат 256 CUDA-ядер FP32, или 2 % от всего массива вещественночисленных ALU. Сделано это скорее с целью обеспечить резерв для возможных дефектов фотолитографии, нежели для сегментации модельного ряда с расчетом на будущие продукты. GeForce RTX 3090 и так превосходит TITAN RTX в 2,2 раза по расчетной пропускной способности операций FP32, а если сравнивать с GeForce RTX 2080 Ti, то уже в 2,5 раза.
А вот от следующей по старшинству модели 30-й серии новый флагман отделяет лишь 20 % теоретического быстродействия. Конечно, мы-то уже знаем, какие числа набрал RTX 3090 в игровых бенчмарках, но читатели, знакомые с обзором RTX 3080, тоже вряд ли рассчитывают увидеть на графиках еще 20 % FPS. Недаром NVIDIA избегает прямых сравнений между GeForce RTX 3080 и RTX 3090 в презентациях, посвященных 30-й серии. Есть только диаграмма с данными трех игр (Control, Minecraft с трассировкой лучей и Borderlands 3), в которых RTX 3090 хвастается на 50 % большей FPS по сравнению с TITAN RTX, но их тоже следует оценивать скептически, ведь ни в одном из перечисленных проектов нет встроенного бенчмарка, а условия тестирования могли сильно повлиять на результат.
В качестве нагрузки, адекватной возможностям GeForce RTX 3090, NVIDIA видит игры на экране с разрешением 8К. Учитывая, что за семь лет видеокарты так и не справились с 4К (после каждого рывка производительности выходят проекты, вновь опускающие частоту смены кадров ниже 60 FPS на максималках), нелегко поверить, что RTX 3090 сразу покорится режим 8К. В конце концов, количество пикселов на таком мониторе или телевизоре не вдвое, а вчетверо больше по сравнению с 4К, поэтому NVIDIA ориентируется на сравнительно легкие игры (такие как Apex Legends, Forza Horizon 4 и World of Tanks), которые являются посильной задачей для RTX 3090 в 8К при высоких настойках графики. Для более требовательных проектов, в том числе с трассировкой лучей, ввели особый режим работы DLSS, который подразумевает масштабирование кадра, отрендеренного в разрешении 2560 × 1440, до полного размера в 7580 × 4320 пикселов, а количество пикселов при таком соотношении между внутренним и выходным разрешением отличается 8,8 раза. Конечно, современные реализации DLSS версии 2.0 работают намного лучше ранних попыток и синтезируют настолько качественное изображение в 4К, что только при внимательном рассмотрении фрагментов кадра можно обнаружить ошибки нейросети, но еще более агрессивные алгоритмы, необходимые для 8К, безусловно, являются для DLSS новым вызовом. Когда у нас появится возможность проверить GeForce RTX 3090 в связке с настоящим 8К-экраном, мы обязательно выясним, соответствуют ли притязания NVIDIA действительности, но сегодня ограничимся стандартным набором тестов при разрешении от 1080p до 2160p
В любом случае RTX 3090 предназначен не только и не столько для игр, сколько для рабочих приложений. В таких задачах, как 3D-моделирование, кодирование видео и, разумеется, машинное обучение, вполне можно рассчитывать на близкий к проектным величинамрост быстродействия между TITAN RTX и GeForce RTX 3090 (особенно в свете архитектурных новшеств Ampere) или даже между RTX 3080 и RTX 3090. Но основным преимуществом RTX 3090 перед RTX 3080 являются 24 Гбайт оперативной памяти. Кроме того, для того, чтобы получить такой объем и обеспечить быстрый доступ к данным почти нетронутому кристаллу GA102, в нем активировали все контроллеры GDDR6X, а совокупная ПСП оценивается в 936 Гбайт/с. Более скоростным интерфейсом VRAM среди игровых и просьюмерских ускорителей может похвастаться только Radeon VII (1 Тбайт/с), оборудованный памятью HBM2.
Наконец, GeForce RTX 3090 оказался единственной видеокартой 30-го семейства, которая поддерживает интерфейс NVLink для прямой коммуникации между двумя GPU. Общая пропускная способность канала осталась практически такой же, как в потребительских ускорителях архитектуры Turing (112,5 Гбайт/ с против 100 Гбайт/с в обе стороны), но это уже другая версия интерфейса, который теперь состоит из четырех линий скоростью 28,13 Гбайт/с вместо двух прежних на 50 Гбайт/с и требует использовать мостики нового образца. Функцию NVLink в RTX 3090 тоже оставили не для игр, а для приложений GP-GPU, которые в состоянии ей воспользоваться, но размер кластера в любом случае ограничен двумя графическими процессорами. Поддержка технологии SLI никуда не делась, но со следующего года NVIDIA не будет выпускать профили для новых игр. Работу с несколькими GPU отдали на откуп разработчикам, которым придется реализовывать функцию mGPU самостоятельно в рамках эксплицитного режима Direct3D 12.