Градиентный бустинг (Градиент-бустинг, Gradient Tree Boosting, Gradient Boosting Machine - GBM) – это метод Машинного обучения (ML) для задач Регрессии (Regression) и Классификации (Classification), который создает прогнозирующую Модель (Model) в форме Ансамбля (Ensemble) слабых алгоритмов прогнозирования, обычно Деревьев решений (Decision Tree).
Несмотря на то, что GBM широко используется, многие практики по-прежнему рассматривают его как Черный ящик (Black Box) и просто запускают модели с использованием предварительно созданных библиотек. Цель этой статьи – упростить предположительно сложный алгоритм и помочь читателю интуитивно понять его.
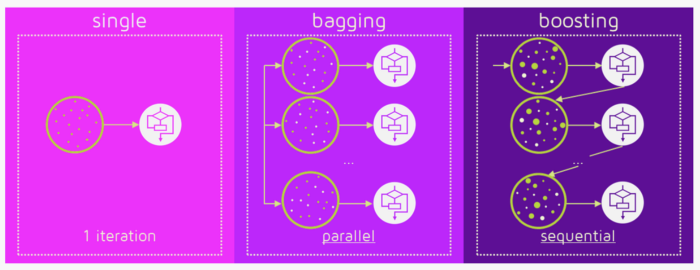
Ансамбль, бэггинг и бустинг
Когда мы пытаемся предсказать Целевую переменную (Target Variable) с помощью любого метода машинного обучения, основными причинами различий между фактическими и прогнозируемыми значениями являются Шум (Noise), Дисперсия (Variance) и Смещение (Bias). Ансамбль помогает уменьшить влияние этих факторов (кроме шума, который является неснижаемой ошибкой).
Ансамбль – это просто набор Алгоритмов (Algorithm), которые собираются вместе с помощью, например, среднего значения всех прогнозов, чтобы дать окончательный. Причина, по которой мы используем ансамбли, заключается в том, что множество разных методов, пытающихся предсказать одну и ту же целевую переменную, будут выполнять свою работу лучше, чем один. Методы ансамбля подразделяются на Бэггинг (Bagging) и Бустинг (Boosting).
Бэггинг – это простой метод объединения, в котором мы создаем множество независимых моделей и группируем их, используя определенные методы усреднения моделей (например, средневзвешенное или нормальное среднее).
Обычно мы берем случайную Выборку (Sample) для каждой модели, чтобы все они мало отличались друг от друга. Каждая модель будет использовать разные наблюдения. Поскольку для генерации окончательного результата с помощью этого метода требуется много независимых алгоритмов, он снижает погрешность за счет уменьшения дисперсии. Примером бэггинг-ансамбля является Случайный лес (Random Forest).
Бустинг – это ансамблевый метод, в котором алгоритмы применяются последовательно. Этот метод использует логику, в которой последующие модели учатся на ошибках предыдущих. Следовательно, Наблюдения (Observation) имеют неодинаковую вероятность появления в последующих моделях, а наблюдения с наибольшей ошибкой появляются чаще. (Таким образом, наблюдения выбираются не на основе процесса начальной загрузки, а на основе ошибки). Из используемых методов перечислим деревья решений, регрессоры, классификаторы и т.д. Поскольку новые алгоритмы учатся на ошибках, совершенных предшественниками, требуется меньше времени / итераций, чтобы приблизиться к фактическим прогнозам. Но мы должны тщательно выбирать критерии остановки, иначе это может привести к Переобучению (Overfitting).
Цель любого алгоритма Контролируемого обучения (Supervised Learning) – определить Функцию потерь (Loss.Function) и минимизировать ее. Давайте посмотрим, как работает GBM.
Логика GBM проста. Я полагаю, что читаюший эту статью знаком с простой Линейной регрессией (Linear Regression):
Основное ее предположение состоит в том, что сумма Остатков (Residual) – разницей между фактическим и спрогнозированным значениями, равна 0, то есть они распределены случайным образом вокруг нуля:
Интуиция алгоритма повышения градиента заключается в том, чтобы многократно ориентироваться на остатки, не укладывающиеся в принцип "сумма остатков равна нулю" и укреплять модель с помощью слабых прогнозов. Как только мы достигаем стадии, когда остатки не имеют какого-либо паттерна, который можно было бы смоделировать, мы прекращаем моделирование остатков (иначе это может привести к переобучению). Алгоритмически мы минимизируем нашу функцию потерь.
В итоге,
- Сначала мы моделируем с помощью простых методов и анализируем результат на предмет ошибок. Эти ошибки означают точки данных, которые трудно вписать в существующую модель.
- Затем, в более поздних моделях, мы особенно сосредотачиваемся на тех данных, которые трудно "уложить".
- В конце мы группируем все методы, присваивая каждому из них вес.
GBM: Scikit-learn
Давайте посмотрим, как кросс-валидация реализована в SkLearn. Для начала импортируем необходимые библиотеки:
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from matplotlib import pyplot
Сгенерируем набор данных из 1000 наблюдений, 10 Признаков (Feature) и инициируем модель. Параметр n_redundant позволяет сгенерировать пять малозначимых переменных, которые сильно коррелируют теми, что обладают высокой Важностью признаков (Feature Importance). Мы будем совершенствовать модель с помощью k-блочной кросс-валидации (k-Fold Cross Validation) и соответствующего класса RepeatedStratifiedKFold:
X, y = make_classification(n_samples = 1000, n_features = 10, n_informative = 5, n_redundant = 5, random_state = 1)
model = GradientBoostingClassifier()
cv = RepeatedStratifiedKFold(n_splits = 10, n_repeats = 3, random_state = 1)
n_scores = cross_val_score(model, X, y, scoring = 'accuracy', cv = cv, n_jobs = -1, error_score = 'raise')
print('Точность измерений: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Обучим модель на имеющихся данных:
model = GradientBoostingClassifier()
model.fit(X, y)
Определим класс для нового наблюдения 'row': числа в списке – это просто значения десяти признаков.
row = [[2.56999479, -0.13019997, 3.16075093, -4.35936352, -1.61271951, -1.39352057, -2.48924933, -1.93094078, 3.26130366, 2.05692145]]
yhat = model.predict(row)
print('Предсказание: %d' % yhat[0])
Модель соотносит row с классом "1":
Предсказание: 1
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Авторы оригинальных статей: ML Review, Jason Brownlee
Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курсы на Udemy.