Чем больше мы изучаем нейронные сети и чем совершеннее становятся алгоритмы обучения, тем больше появляется вопросов. Какая нейросеть лучше подойдет для достижения поставленной цели? Насколько глубоким должно быть обучение? Что лучше использовать LSTM или слои трансформатора? А может их комбинацию?
Рассматривая проблему через призму машинного обучения, вопросов становится еще больше. Ведь за последние годы были разработаны алгоритм AutoML (автоподбор подходящей под задачи нейросети) и RL (обучение с подкреплением), метод NAS (для поиска нейронных архитектур) и множество других технологий. Если же говорить про все доступные способы машинного обучения, то мы окажемся в сумрачном лесу. Многообразие и относительная универсальность методов приводят к тому, что внедряется на самый точный и не самый эффективный алгоритм.
Мы получаем палку о двух концах. С одной стороны грамотное использование всех доступных методов и алгоритмов даёт потрясающий результат. С другой - они требуют сложных вычислений, глубокие знания работы каждого алгоритма и огромные объемы данных.
Чтобы исправить это и сделать поиск решений для машинного обучения более простым и доступным для датасаентистов разного уровня, Google платформу с открытым исходным кодом - Model Search. LabelMe изучил новинку и сейчас мы расскажем всё, что нужно о ней знать.
Как устроен Model Search
Model Search - платформа на Python c открытым исходным кодом, построенная на базе Tensorflow. Её цель - расширить доступ к решениям AutoML и помочь специалистам Machine Learning автоматически разрабатывать лучшие модели обучения под решения конкретных задач.

Как это работает? Model Search не сосредотачивается на конкретной области. Платформа ищет подходящую архитектуру, отталкиваясь от имеющегося набора данных и конечной задачи. Это позволяет минимизировать время и усилия, затраченные на кодирование и вычислительные ресурсы.
Model Search состоит из
- нескольких обучающих программ;
- алгоритма поиска;
- алгоритма трансферного обучения;
- базы данных для хранения различных оцениваемых моделей.
Система выполняет как обучающие, так и оценочные эксперименты для различных моделей машинного обучения (разные архитектуры и методы обучения) адаптивным и асинхронным образом. При этом каждый метод обучения не только проводит эксперименты автоматически и обособленно, но и делятся полученными результатами.
В начале каждого цикла алгоритм поиска просматривает все завершенные испытания и использует поиск по лучу (эвристический алгоритм поиска, который исследует график пути расширения наиболее многообещающего узла в ограниченном наборе) , чтобы решить, что делать дальше. Так платформа определяет лучшую архитектуру и вызывает мутацию, которая позволяет улучшить ее. Это чем-то напоминает процесс фильтрации, который повторяется, отсеивая самый слабые варианты.
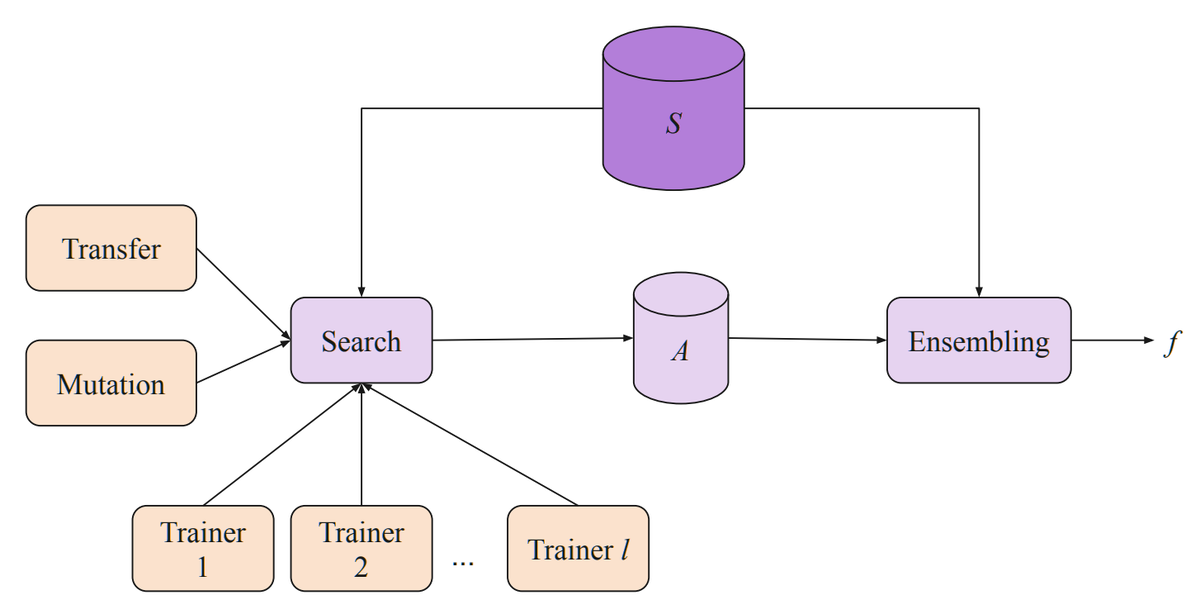
На схеме Model Search видно, что каждый тренер работает независимо для обучения и оценки данной модели. Результаты передаются алгоритму поиска, который он сохраняет. Затем алгоритм поиска вызывает мутацию одной из лучших архитектур и затем отправляет новую модель обратно тренеру для следующей итерации. S - это набор примеров обучения и проверки, а A - все кандидаты, используемые во время обучения и поиска.
Система строит модель нейронной сети из набора предопределенных блоков, каждый из которых представляет известную микроархитектуру: LSTM, ResNet, Transformer и так далее. Используя блоки ранее существовавших архитектурных компонентов, Model Search получает доступ к самым точным и качественным знаниям из исследований NAS в разных областях. Эффективность платформы увеличивает и то, что она исследует структуры, а не их более исходные и подробные компоненты.
Почему на базе Tensorflow
Благодаря тому, что Model Search построена на Tensorflow , блоки могут реализовать любую функцию, которая принимает тензор в качестве входных данных.
Например, представьте, что кто-то хочет представить новое пространство поиска, построенное с помощью набора микроархитектур. Платформа возьмет вновь определенные блоки и включит их в процесс поиска, чтобы алгоритмы могли построить наилучшую возможную нейронную сеть из предоставленных компонентов.

Предоставленные блоки могут быть даже полностью определенны нейронными сетями, которые, как уже известно, работают с интересующей проблемой. В этом случае поиск модели можно настроить так, чтобы он просто действовал как мощная машина для объединения.
Алгоритмы поиска одновременно адаптивные, инкрементными и "жадными" , что позволяет им сходиться быстрее, чем алгоритмы RL. С другой стороны они отчасти имитируют принцип работы RL - "explore & exploit" . Алгоритм осуществляет поиск оптимального кандидата на стадии исследования и повышает точность, объединения хороших кандидатов, которые были обнаружены на стадии использования.
Основной алгоритм поиска адаптивно модифицирует один из k лучших экспериментов (где k может быть указан пользователем) после внесения случайных изменений в архитектуру или методику обучения.

Для дальнейшего повышения эффективности и точности между различными внутренними экспериментами используется Transfer Learning. Поиск моделей делает это двумя способами: обобщения знаний или разделением веса.
Первый вариант позволяет повысить точность кандидатов, добавляя термин потерь, который соответствует предсказаниям высокопроизводительных моделей в дополнение к основной истине.
Второй - загружает некоторые параметры (после применения мутации) в сеть от ранее обученных кандидатов путем копирования подходящих весов из ранее обученных моделей и случайной инициализации оставшихся.
В совокупности они обеспечивают более быстрое и точное обучение по поиску подходящей архитектуры.
Установка и требования
Эта структура пока недоступна в PyPI, поэтому ее можно клонировать с помощью git.
! git clone https://github.com/google/model_search.git
% cd / content / model_search /
Требования для Model Search можно установить с помощью файла requirements.txt. Команда показана ниже:
!pip install -r requirements.txt
Скомпилируйте все прото-файлы с помощью компилятора protoc , код доступен ниже:
%%bash
protoc --python_out=./ model_search/proto/phoenix_spec.proto
protoc --python_out=./ model_search/proto/hparam.proto
protoc --python_out=./ model_search/proto/distillation_spec.proto
protoc --python_out=./ model_search/proto/ensembling_spec.proto
protoc --python_out=./ model_search/proto/transfer_learning_spec.proto
Если вы сталкиваетесь с ошибкой не анализируемых файлов при импорте модели, то загрузите флаги. Нужный фрагмент кода:
import sys
from absl import app
# Addresses `UnrecognizedFlagError: Unknown command line flag 'f'`
sys.argv = sys.argv[:1]
# `app.run` calls `sys.exit`
try:
app.run(lambda argv: None)
except:
Pass
Демо - поиск модели для данных CSV
В этом демо рассмотрим, как использовать структуру Model Search для данных CSV, где функции - числа. Для решения проблемы классификации выполните следующие действия:
1. Импортируем все необходимые модули и пакеты.
import model_search
from model_search import constants
from model_search import single_trainer
from model_search.data import csv_data
2. У Model Search нет автоматической очистки данных и разработки функций. Задаем вручную.
3. Создаем экземпляр тренера и передаем данные csv в csv_data.Provider, где
- label_index содержит номер столбца, в котором метки находятся во фрейме данных
- logit_dimension представляет количество классов в данных
- record_default представляет собой массив (размер, равный количеству функций) для вменения данных. То есть во всех четырех столбцах, если присутствует какое-либо нулевое значение, оно должно быть заменено на 0
- filename определяет данные
- spec представляет собой пространство поиска, вы можете создать собственное или использовать значение по умолчанию, как указано ниже.
trainer = single_trainer.SingleTrainer (
data = csv_data.Provider (
label_index = 0,
logits_dimension = 2,
record_defaults = [0, 0, 0, 0],
filename = "model_search / data / testdata / csv_random_data.csv"),
spec = " model_search / configs / dnn_config.pbtxt ")
4. Советуем попробовать разные модели на объекте трейнера с помощью try_models:
- number_models : количество моделей, которые нужно опробовать;
- Train_steps: означает, что каждую модель нужно обучить за 1000 шагов;
- eval_steps : означает, что каждые 100 шагов модель должна самостоятельно диагностироваться и оцениваться;
- root_dir: путь к каталогу для сохранения результатов;
- batch_size : представляет размер пакета для взятых данных;
- experiment_name : представляет название эксперимента (дополнительная информация);
- experiment_owner : представляет владельца эксперимента (дополнительная информация).
Запустите приведенный ниже код, чтобы начать обучение, поиск и оценку области поиска. В приведенном ниже примере проверяется 200 различных моделей по 1000 шагов каждая и оценивается модель на каждых 100 шагах. Запуск может занять некоторое время.
trainer.try_models(
number_models=200,
train_steps=1000,
eval_steps=100,
root_dir="/tmp/run_example",
batch_size=32,
experiment_name="example",
experiment_owner="model_search_user")
5. Вы можете ознакомиться со всеми выполненными испытаниями в этом каталоге:
!ls /tmp/run_example/example
Для получения информации о каждой модели (точность, оценка и т. д.):
!ls /tmp/run_example/tuner-1/
Для каждой модели каталог tuner-1 содержит архитектуру, различные контрольные точки, данные оценки и так далее. Пример чтения архитектуры модели с идентификатором 1 показан ниже:
!cat /tmp/run_example/tuner-1/1/graph.pbtxt
Результаты экспериментов
Model Search улучшает производственные модели с минимальным количеством итераций. В недавней статье сотрудники Google продемонстрировали возможности Model Search в речевой области, открыв модель для определения ключевых слов и идентификации языка.
Менее чем за 200 итераций полученная модель немного улучшилась по сравнению с современными внутренними производственными моделями, разработанными экспертами по точности с использованием на ~ 130K меньше обучаемых параметров (184K по сравнению с 315K параметров).
Цель другого эксперимента - поиск модели, подходящей для классификации изображений на тщательно изученном наборе данных изображений от CIFAR-10. Используя набор известных блоков свертки, блоки повторной сети, ячейки NAS-A, полностью связанные слои, исследователи достигли точности в 91,38 дюймов за 209 испытаний. Для наглядности, предыдущие лучшие исполнители достигли такой же пороговой точности в 5807 испытаниях для алгоритма NASNet (RL) и 1160 для PNAS (RL + Progressive).
Заключение
Вы сами видите эти впечатляющие результаты. Учитывая то, что код Model Search находится в открытом доступе, попробовать его каждый, кто хоть как-то связан с машинным обучением. Он способен значительно ускорить процесс обучения и оптимизировать издержки, необходимые для тестов эффективности отдельных алгоритмов. Берешь качественный датасет, ставишь задачу и Model Search ищет самый подходящий способ обучения. Разве это не мечта любого датасаентиста?



















