
3 ноября компания AMD раскрыла ключевые детали своей грядущей архитектуры GPU RDNA 3 и видеокарт серии Radeon RX 7900. Это был публичный анонс, на который пригласили посмотреть весь мир. Вскоре после анонса AMD пригласила прессу и аналитиков за закрытые двери, чтобы немного углубиться в то, что заставляет RDNA 3 тикать - или тикать? Неважно.
Сейчас нам разрешено говорить о дополнительных деталях RDNA 3 и других брифингах AMD, которые почти наверняка не имеют никакого отношения к предстоящему в среду запуску RTX 4080 от Nvidia. (Это сарказм, на случай, если это было непонятно. Подобные вещи постоянно происходят с AMD и Nvidia, или AMD и Intel, или даже Intel и Nvidia теперь, когда Team Blue присоединилась к гонке GPU).
Архитектура RDNA 3 от AMD кардинально меняет несколько ключевых элементов дизайна графических процессоров, благодаря использованию чиплетов. И это самое подходящее место для начала. У нас также есть отдельные статьи, посвященные отношениям AMD с игровыми компаниями и ISV, программному обеспечению и платформам, а также видеокартам серии Radeon RX 7900.
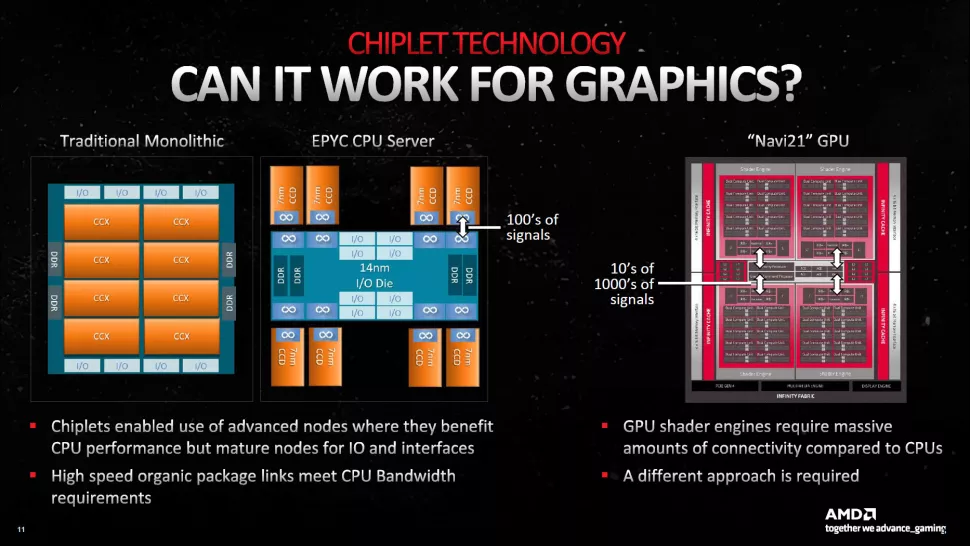
Navi 31 состоит из двух основных частей - графической вычислительной матрицы (GCD) и матрицы кэш-памяти (MCD). Есть сходство с тем, что AMD сделала со своими процессорами Zen 2/3/4, но все было адаптировано под нужды мира графики.
В процессорах Zen 2 и более поздних версиях AMD использует матрицу ввода-вывода (IOD), которая подключается к системной памяти и обеспечивает все необходимые функции для таких вещей, как интерфейс PCIe Express, порты USB, а с недавнего времени (Zen 4) - графические и видео функции. Затем IOD подключается к одному или нескольким вычислительным ядрам (CCD - альтернативно "Core Complex Dies", в зависимости от дня недели) через Infinity Fabric от AMD, а CCD содержат ядра CPU, кэш и другие элементы.
Ключевым моментом в конструкции является то, что типичные алгоритмы общих вычислений - то, что работает на ядрах процессора - в основном помещаются в различных кэшах L1/L2/L3. Современные процессоры вплоть до Zen 4 имеют только два 64-битных канала памяти для системной оперативной памяти (хотя серверные процессоры EPYC Genoa могут иметь до двенадцати каналов DDR5).
ПЗС имеют небольшие размеры, а IOD может варьироваться от около 125 мм^2 (Ryzen 3000) до 416 мм^2 (поколение EPYC xxx2). Совсем недавно процессоры серии Zen 4 Ryzen 7000 имели IOD, изготовленный с использованием TSMC N6, размером всего 122 мм^2 с одним или двумя ПЗС размером 70 мм^2, изготовленными на TSMC N5, а в поколении EPYC xxx4 используются те же ПЗС, но с относительно массивным IOD размером 396 мм^2 (по-прежнему изготовленным на TSMC N6).
У графических процессоров совсем другие требования. Большой кэш может помочь, но GPU также очень любят иметь большую пропускную способность памяти для питания всех ядер GPU. Например, даже "зверский" EPYC 9654 с 12-канальной конфигурацией DDR5 "всего" обеспечивает пропускную способность до 460,8 Гб/с. Самые быстрые видеокарты, такие как RTX 4090, могут легко удвоить этот показатель.
Другими словами, AMD нужно было сделать что-то другое для эффективной работы чипсетов GPU. В итоге решение оказалось почти обратным чиплетам CPU: контроллеры памяти и кэш размещаются на нескольких небольших матрицах, а основная вычислительная функциональность находится в центральном чиплете GCD.
В GCD размещаются все вычислительные блоки (CU), а также другие основные функции, такие как видеокодек, интерфейсы дисплея и соединение PCIe. Navi 31 GCD имеет до 96 CU, где происходит типичная обработка графики. Но у него также есть Infinity Fabric вдоль верхнего и нижнего краев (связанная через своего рода шину с остальной частью чипа), которая затем подключается к MCD.
MCD, как следует из названия (Memory Cache Dies), в основном содержат большие блоки кэша L3 (Infinity Cache), а также физический интерфейс памяти GDDR6. Они также должны содержать каналы Infinity Fabric для подключения к GCD, которые вы можете видеть на снимке матрицы вдоль центрального края MCD.
GCD будет использовать узел N5 компании TSMC и разместит 45,7 миллиарда транзисторов на площади 300 мм^2. Между тем, MCD построены на узле N6 компании TSMC, каждый из которых содержит 2,05 миллиарда транзисторов на кристалле площадью всего 37 мм^2. Кэш-память и внешние интерфейсы - это те элементы современных процессоров, которые хуже всего масштабируются, и мы видим, что в целом GCD имеют в среднем 152,3 миллиона транзисторов на мм^2, а MCD - только 55,4 миллиона транзисторов на мм^2.
Одна из потенциальных проблем при использовании чиплета в графических процессорах заключается в том, сколько энергии требуется всем звеньям Infinity Fabric - внешние чипы почти всегда потребляют больше энергии. В качестве примера можно привести процессоры Zen с органической подложкой, которая относительно дешева в производстве, но потребляет 1,5 pJ/b (пикоджоулей на бит). Масштабирование этого интерфейса до 384-битного потребовало бы значительных затрат энергии, поэтому AMD работала над усовершенствованием интерфейса с помощью Navi 31.
Результатом стало то, что AMD называет высокопроизводительным fanout interconnect. Изображение выше не совсем понятно, но более крупный интерфейс слева - это интерфейс на органической подложке, используемый в процессорах Zen. Справа - высокопроизводительный fanout-мост, используемый в Navi 31, "приблизительно в масштабе".
Вы можете четко видеть 25 проводов, используемых для CPU, в то время как 50 проводов, используемых в эквиваленте GPU, упакованы на гораздо меньшей площади, так что вы даже не можете увидеть отдельные провода. Для той же цели используется примерно 1/8 высоты и ширины, что означает примерно 1/64 общей площади. Это, в свою очередь, значительно снижает требования к энергопотреблению, и AMD утверждает, что все каналы Infinity Fanout вместе взятые обеспечивают эффективную пропускную способность 3,5 ТБ/с, составляя при этом менее 5% от общего энергопотребления GPU.
Здесь есть небольшое интересное отступление: вся логика Infinity Fabric как на GCD, так и на MCD занимает приличное количество места на матрице. Если посмотреть на снимок кристалла, то шесть интерфейсов Infinity Fabric на GCD занимают около 9% площади кристалла, а на MCD эти интерфейсы составляют около 15% от общего размера кристалла.
Если стереть интерфейс Infinity Fabric и собрать весь чип как монолитную деталь на узле N5 компании TSMC, его площадь, вероятно, составит всего 400-425 мм^2. Очевидно, стоимость TSMC N5 настолько выше, чем N6, что стоило пойти по пути чиплета, что говорит о растущей стоимости меньших производственных узлов.
В связи с этим мы знаем, что некоторые аспекты дизайна чипа лучше масштабируются при уменьшении техпроцесса. Внешние интерфейсы - например, физический интерфейс GDDR6 - почти перестали масштабироваться. Кэш-память также имеет тенденцию к плохому масштабированию. Интересно будет посмотреть, будут ли графические процессоры AMD следующего поколения (Navi 4x / RDNA 4) использовать те же MCD, что и RDNA 3, а GCD, предположительно, будут перенесены на будущий узел TSMC N3.
С аспектом чиплета мы разобрались, теперь перейдем к изменениям архитектуры различных частей GPU. В целом их можно разделить на четыре области: общие изменения в дизайне чипа, усовершенствования шейдеров GPU (потоковых процессоров), обновления для повышения производительности трассировки лучей и усовершенствования аппаратных средств работы с матрицей.
Глядя на необработанные спецификации, может показаться, что AMD не так уж сильно увеличила тактовые частоты, но раньше у нас были только показатели Game Clock. Теперь мы можем сказать, что тактовые частоты повышены, и в общем случае мы ожидаем, что графические процессоры AMD RDNA 3 будут превосходить даже официальные тактовые частоты - другими словами, это консервативные тактовые частоты.
AMD утверждает, что RDNA 3 был спроектирован для достижения скорости 3 ГГц. Официальные частоты форсирования эталонных 7900 XTX / XT значительно ниже этой отметки, но мы также считаем, что эталонные дизайны AMD больше ориентированы на максимальную эффективность. Карты AIB сторонних производителей вполне могут значительно повысить предельную мощность, напряжение и тактовую частоту. Увидим ли мы 3 ГГц вне заводских разгонов? Возможно, так что подождем и посмотрим.
По словам AMD, графические процессоры RDNA 3 могут работать на той же частоте, что и графические процессоры RDNA 2, потребляя в два раза меньше энергии, или же они могут работать на частоте в 1,3 раза выше при том же энергопотреблении. Конечно, в конечном счете, AMD стремится сбалансировать частоту и мощность для обеспечения наилучшего общего впечатления. Тем не менее, учитывая, что мы видим более высокие ограничения по мощности на 7900 XTX, мы должны ожидать, что это будет сопровождаться приличным увеличением тактовой частоты и производительности.
Еще одно замечание AMD заключается в том, что она улучшила использование кремния примерно на 20%. Другими словами, на графических процессорах RDNA 2 были функциональные блоки, в которых части чипа часто простаивали, даже когда карта находилась под полной нагрузкой. К сожалению, у нас нет хорошего способа измерить это напрямую, поэтому мы поверим AMD на слово, но в конечном итоге это должно привести к повышению производительности.
За пределами чиплета многие из самых больших изменений происходят в вычислительных блоках (CU) и процессорах рабочих групп (WGP). Они включают обновления размеров кэш-памяти L0/L1/L2, больше регистров SIMD32 для FP32 и матричных рабочих нагрузок, а также более широкие и быстрые интерфейсы между некоторыми элементами.
Майк Мантор из AMD представил вышеприведенные и следующие слайды, которые очень плотные! Он говорил без остановки большую часть часа, пытаясь охватить все, что было сделано в архитектуре RDNA 3, и этого времени оказалось недостаточно. Приведенный выше слайд охватывает общую картину, но давайте пройдемся по некоторым деталям.
RDNA 3 поставляется с улучшенной парой вычислительных блоков - двойными CU, которые стали основным строительным блоком для чипов RDNA. При беглом взгляде может показаться, что он не сильно отличается от RDNA 2, но затем обратите внимание, что в первом блоке для планировщика и векторных GPR (регистров общего назначения) написано "Float / INT / Matrix SIMD32", а за ним следует второй блок, в котором написано "Float / Matrix SIMD32". Этот второй блок является новым для RDNA 3, и в основном он означает удвоение пропускной способности с плавающей запятой.
Вы можете смотреть на это одним из двух способов: Либо каждый CU теперь имеет 128 потоковых процессоров (SPs, или шейдеров GPU), и вы получаете 12 288 шейдерных ALU (Arithmetic Logic Units), либо вы можете рассматривать это как 64 "полноценных" SPs, которые просто имеют вдвое большую пропускную способность FP32 по сравнению с CU предыдущего поколения RDNA 2.
Это довольно забавно, потому что в некоторых местах говорят, что Navi 31 имеет 6 144 шейдерных процессора, а в других - 12 288 шейдерных процессоров, поэтому я специально спросил Майка Мантора из AMD - главного архитектора GPU и главного разработчика дизайна RDNA 3 - о том, 6 144 или 12 288. Он достал калькулятор, вбил несколько цифр и сказал: "Да, должно быть 12 288". И все же, в некотором смысле, это не так.
На собственных слайдах AMD в другой презентации (выше) говорится о 6 144 SP и 96 CU для 7900 XTX и 84 CU с 5 376 SP для 7900 XT, поэтому AMD использует меньшее число. Однако необработанные вычисления FP32 (и матричные вычисления) увеличились вдвое. Лично мне кажется более логичным называть это 128 SP на CU, а не 64, и общий дизайн похож на архитектуры Ampere и Ada Lovelace от Nvidia. У тех сейчас 128 ядер FP32 CUDA на потоковый мультипроцессор (SM), но также 64 блока INT32.
Наряду с дополнительными 32-битными вычислениями с плавающей запятой, AMD также удвоила пропускную способность матрицы (AI), так как матричные ускорители AI, похоже, по крайней мере, частично разделяют некоторые ресурсы выполнения. Новым для блоков AI является поддержка BF16 (brain-float 16-bit), а также инструкции INT4 WMMA Dot4 (Wave Matrix Multiply Accumulate), и, как и в случае с пропускной способностью FP32, общее увеличение скорости матричных операций составляет 2,7x.
Это 2,7-кратное увеличение, по-видимому, связано с общим увеличением производительности на 17,4% по сравнению с тактовой частотой, плюс на 20% больше CU и вдвое больше SIM32-блоков на CU. (Но не цитируйте меня, так как AMD не указала конкретно все преимущества).
Кэши и интерфейсы между ними и остальной системой получили обновления. Например, кэш L0 теперь составляет 32 КБ (вдвое больше, чем в RDNA 2), кэш L1 - 256 КБ (снова вдвое больше, чем в RDNA 2), а кэш L2 увеличился до 6 МБ (в 1,5 раза больше, чем в RDNA 2).
Связь между основными процессорами и кэшем L1 теперь в 1,5 раза шире, с пропускной способностью 6144 байт за такт. Аналогично, связь между кэш-памятью L1 и L2 также в 1,5 раза шире (3072 байта за такт).
Кэш-память L3, также называемая бесконечным кэшем, уменьшилась по сравнению с Navi 21. Теперь он составляет 96 МБ против 128 МБ. Однако связь между L3 и L2 теперь в 2,25 раза шире (2304 байта за такт), поэтому общая пропускная способность намного выше. Фактически, AMD приводит цифру 5,3 ТБ/с - 2304 Б/такт при частоте 2,3 ГГц. У RX 6950 XT связь с Infinity Cache была всего 1024 B/clk (максимум), а RDNA 3 обеспечивает пиковую пропускную способность интерфейса в 2,7 раза выше.
Обратите внимание, что эти цифры относятся только к полностью сконфигурированному решению Navi 31 в 7900 XTX. Модель 7900 XT имеет пять MCD, интерфейс GDDR6 320 бит и 1920 B/clk связей с 80 МБ кэш-памяти Infinity Cache. Скорее всего, мы увидим более низкоуровневые части RDNA 3, которые еще больше сократят ширину интерфейса и производительность, естественно.
Наконец, теперь имеется до шести 64-битных интерфейсов GDDR6 для 384-битного соединения с памятью GDDR6. VRAM также работает со скоростью 20 Гбит/с (против 18 Гбит/с у более поздних карт 6x50 и 16 Гбит/с у оригинальных чипов RDNA 2), что обеспечивает общую пропускную способность 960 ГБ/с.
Интересно, насколько сократился разрыв между GDDR6 и GDDR6X в этом поколении, по крайней мере, в поставляемых конфигурациях. 960 ГБ/с AMD на RX 7900 XTX всего на 5% меньше, чем 1008 ГБ/с RTX 4090, в то время как RX 6900 XT и RTX 3090 имели пропускную способность 512 ГБ/с по сравнению с 936 ГБ/с Nvidia в 2020 году.
Трассировка лучей на архитектуре RDNA 2 всегда казалась чем-то второстепенным - чем-то, что было добавлено для соответствия списку необходимых функций для DirectX 12 Ultimate. В графических процессорах AMD RDNA 2 отсутствует специальное аппаратное обеспечение для обхода BVH, предпочитая выполнять часть этой работы с помощью других общих блоков, и это, по крайней мере, частично виновато в их слабой производительности.
Ускорители лучей RDNA 2 могли выполнять до четырех пересечений лучей/коробки за такт или одно пересечение лучей/треугольника. Для сравнения, Arc Alchemist от Intel может выполнять до 12 пересечений лучей/боксов на RTU за такт, а Nvidia не указывает конкретное число, но имеет до двух пересечений лучей/треугольников на RT-ядро на Ampere и до четырех пересечений лучей/треугольников за такт на Ada Lovelace.
Неясно, действительно ли RDNA 3 улучшает эти показатели напрямую, или AMD сосредоточилась на других улучшениях, чтобы уменьшить количество выполняемых пересечений лучей/угольников. Возможно, и то, и другое. Известно, что в RDNA 3 будет улучшен обход BVH (Bounding Volume Hierarchy), что повысит производительность трассировки лучей.
RDNA 3 также имеет в 1,5 раза большие VGPR, что означает в 1,5 раза больше лучей в полете. Имеются и другие оптимизации стека для уменьшения количества инструкций, необходимых для обхода BVH, а специализированные алгоритмы сортировки ящиков (ближайший первый, наибольший первый, ближайшая средняя точка) могут быть использованы для повышения эффективности.
В целом, благодаря новым функциям, более высокой частоте и увеличенному количеству ускорителей лучей, AMD утверждает, что RDNA 3 должен обеспечить прирост производительности трассировки лучей в 1,8 раза по сравнению с RDNA 2. Это должно сократить разрыв между AMD и Nvidia Ampere. Тем не менее, Nvidia, похоже, также удвоила свои аппаратные средства трассировки лучей для Ada Lovelace, поэтому мы не будем рассчитывать на то, что AMD обеспечит эквивалентную производительность GPU серии RTX 40.
Наконец, в RDNA 3 были настроены другие элементы архитектуры, связанные с командным процессором, геометрией и конвейерами пикселей. Также появился новый движок Dual Media Engine с поддержкой кодирования/декодирования AV1, декодирования видео с поддержкой искусственного интеллекта и новый движок Radiance Display Engine.
Обновления командного процессора (CP) должны повысить производительность для определенных рабочих нагрузок, а также уменьшить узкие места в CPU на стороне драйверов и API. Производительность аппаратной сортировки также на 50% выше в геометрической части, а пиковое количество растеризованных пикселей за такт увеличилось на 50%.
Последнее, по-видимому, является результатом увеличения числа ROP (Render Outputs) со 128 на Navi 21 до 192 на Navi 31. Это имеет смысл, поскольку каналы памяти также увеличены на 50%, и AMD хотела бы масштабировать другие элементы в соответствии с этим.
Dual Media Engine должен вывести AMD на паритет с Nvidia и Intel по части видео, хотя мы должны провести тестирование, чтобы увидеть, как соотносятся качество и производительность. Из наших тестов кодирования видео Arc A380 мы знаем, что Intel в целом обеспечила лучшую производительность и качество, Nvidia не сильно отставала, а AMD была относительно далеко на третьем месте по качеству. К сожалению, нам пока не удалось протестировать поддержку AV1 от Nvidia, но мы с нетерпением ждем возможности проверить обе новые реализации AV1 от AMD и Nvidia.
AMD также получает как минимум несколько очков за включение поддержки DisplayPort 2.1. Intel также поддерживает DP2 в своих графических процессорах Arc, но его максимальная скорость составляет 40 Гбит/с (UHBR 10), в то время как AMD может работать со скоростью 54 Гбит/с (UHBR 13,5). Дисплейные выходы AMD могут работать с частотой до 4K при 229 Гц без сжатия для 8-битной глубины цвета или 187 Гц при 10-битном цвете. Сжатие Display Stream Compression может более чем удвоить этот показатель, позволяя передавать 4K и 480 Гц или 8K и 165 Гц - не то чтобы мы были близки к появлению дисплеев, которые действительно поддерживают такие скорости.
Реалистично, мы должны задаться вопросом, насколько важным будет DP2.1 UHBR 13.5 с видеокартами RDNA 3. Во-первых, вам понадобится новый монитор с поддержкой DP2.1, а во-вторых, возникает вопрос, насколько лучше выглядит что-то вроде 4K 180 Гц с DSC и без него - ведь DP1.4a все еще может поддерживать это разрешение с DSC, в то время как UHBR 13.5 может делать это без DSC.