Предыдущая часть:
Алгоритм сортировки слиянием (merge sort) очень похож на quicksort, а также на другие алгоритмы семейства Divide and Conquer (Разделяй и властвуй).
Суть Divide and Conquer в том, чтобы разбивать большую задачу на более мелкие, пока не получим элементарные задачи. Решив элементарные задачи, мы решаем и задачи верхнего уровня.
В случае с сортировкой массив делится на 2 части, затем каждая часть делится ещё на 2, и т.д. Так мы очень быстро приходим к размеру части в 1 элемент, даже если начинали с очень большого. Такие элементы легко отсортировать попарно, а затем уже отсортированные снова отсортировать попарно, и т.д.
Если merge sort очень похож на quicksort, то зачем понадобились разные алгоритмы с разными названиями?
Внутренняя и внешняя сортировки
Внутренняя сортировка происходит целиком в памяти компьютера. Естественно, все сортируемые данные должны помещаться в память одновременно.
Если же памяти не хватает, то используется внешняя сортировка. Она работает с носителями данных, размер которых заведомо больше, чем размер памяти.
Собственно, quicksort это внутренняя сортировка, а merge sort – внешняя. Это фактически один и тот же алгоритм, подогнанный под разные требования.
Дополнительным требованием к внешней сортировке может быть последовательный доступ. В отличие от оперативной памяти, где мы можем без проблем (за исключением локального кеширования) прочитать ячейку по любому адресу, устройство с последовательным доступом это что-то вроде магнитной ленты. Чтобы добраться от начала ленты до середины, нужно промотать её. Нет способа сразу попасть в середину. Чем дальше от текущей позиции находятся данные, тем дольше надо мотать. Поэтому самый эффективный способ работы с лентой – когда мы обращаемся к данным, расположенным последовательно друг за другом.
Способ работает не только с лентой. Например, жёсткий диск для чтения секторов должен позиционировать магнитную головку, и хотя это относительно быстрая операция, чтение последовательных секторов происходит гораздо быстрее, так как головка стоит на месте.
Merge sort использует именно последовательный доступ.
Но надо учесть, что помимо основного файла алгоритм использует два временных. Поэтому истинный последовательный доступ возможен лишь в том случае, когда каждый файл находится на отдельном физическом носителе.
Реализация алгоритма
Описывая этот алгоритм, я не буду обращаться к файловой системе. Вместо этого я буду использовать массивы в памяти, но будем считать, что каждый массив это абстракция файла на диске. Для доступа к данным будет использована позиция в массиве, называемая pos. Я ограничиваю операции с позицией только последовательным однонаправленным доступом – то есть, могу только увеличивать pos на 1, либо обнулять.
Основная идея
Начнём с середины алгоритма, потому что это главное. Представим, что есть две отсортированных по возрастанию последовательности чисел, из которых надо составить одну отсортированную по возрастанию последовательность. Назовём эти последовательности A и B.
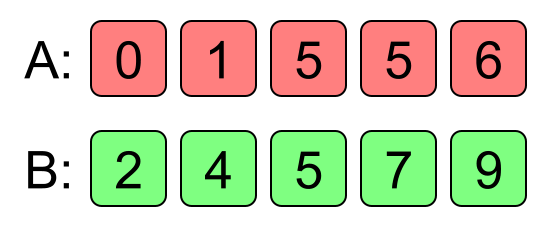
Мы возьмём первое число из A (a1) и первое число из B (b1), и сравним их. Если a1 меньше b1, то оно пойдёт первым в отсортированный результат. Почему мы можем быть в этом уверены, не проверяя все остальные числа в последовательностях? Потому что последовательности отсортированы по возрастанию. Значит, если a1 меньше b1, то все остальные числа в обоих последовательностях не могут быть меньше.
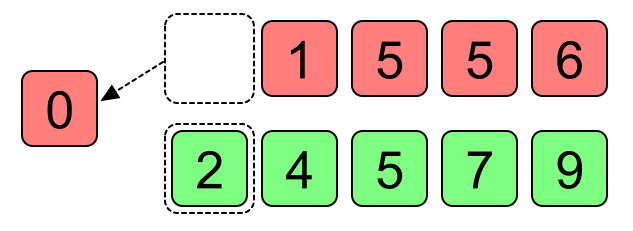
Итак, мы записали число a1 в результирующий файл.
Так как число a1 ушло, на его место прочитаем второе число из последовательности A – a2.
Теперь опять сравним a2 и b1. Если a2 снова меньше, то вторым числом в результат запишем a2, а затем прочитаем a3.
Если же меньше оказалось число b1, то оно пойдёт в результат, и мы прочитаем b2.
Как видите, каждый раз происходит сравнение чисел с верхушек обоих последовательностей. И если какое-то из них меньше, то других чисел меньше него нет. Оно уходит и замещается следующим числом из своей последовательности. В это время вторая последовательность никуда не движется и просто ждёт своей очереди.
Если получилось так, что мы прочитали все числа из одной последовательности, а в другой они ещё остались, то мы просто запишем остаток этой последовательности в результат.
Теперь распишу алгоритм полностью.
Шаг деления
Исходный файл читается по одному элементу (последовательно, само собой) и каждый элемент пишется по очереди то в один временный файл, то в другой (также последовательно).
В результате мы имеем файл, разделённый на 2 части. В одной части находятся все нечётные элементы, а в другой все чётные.
Шаг слияния
Все три файла перематываются в начало, то есть позиция чтения/записи перемещается на 0.
Мы начнём получать из временных файлов последовательности определённой длины. Зная длину последовательности, мы можем читать числа из файла, и знать, когда последовательность кончилась и началась новая.
Получив первые две последовательности А и B из двух файлов, мы можем составить из них одну отсортированную последовательность. Но ведь для этого последовательности должны быть отсортированы, а мы ещё ничего не сортировали?
А они уже отсортированы, потому что текущая длина последовательности равна 1. Один элемент всегда отсортирован.
Значит, читая по 1 элементу из каждого файла, мы можем составить отсортированные последовательности длиной 2 и записать их в исходный файл.
Шаг деления (повтор)
Повторяем деление, но теперь читаем из исходного файла по 2 числа и записываем во временные файлы по 2 числа. Уже сейчас можно понять, что происходит.
Шаг слияния (повтор)
Теперь временные файлы содержат отсортированные последовательности длиной 2. Мы читаем их и составляем отсортированные последовательности длиной 4, снова записывая их в исходный файл.
Увеличивая размер последовательности в 2 раза и повторяя предыдущие шаги, мы будем получать файл, состоящий из отсортированных последовательностей длиной 8, 16, 32 элементов, пока наконец длина последовательности не сравняется с длиной всего файла. Это будет значить, что он полностью отсортирован.
Код алгоритма я приведу в следующем выпуске, так как там придётся делать некоторые пояснения.
Читайте дальше: