Предыдущие части:
Алгоритм quicksort – один из наиболее распространённых "промышленных" алгоритмов, он используется в библиотеках многих языков программирования. И это заслуженно: он наиболее универсальный и достаточно быстрый. Но и у него есть слабые места.
Как работает quicksort
В массиве, который нужно отсортировать, выбирается какой-нибудь элемент (любой). Он называется опорным (pivot). Затем мы проходим по массиву, и все элементы, которые меньше опорного, размещаем слева от него, а все, которые больше – справа.
После одного прохода мы получаем массив, который отсортирован относительно опорного элемента. Все элементы левее опорного элемента меньше его, а все справа – больше.
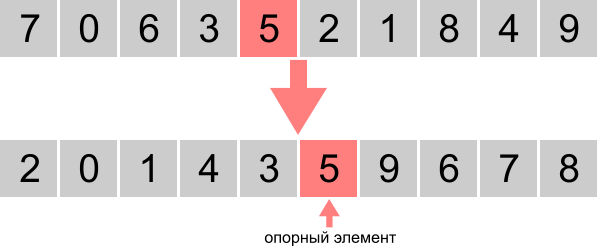
Чтобы завершить алгоритм, нужно представить, что части массива слева и справа от опорного элемента – это просто отдельные, ещё не отсортированные массивы, и поэтому их можно точно так же отсортировать, применив тот же самый алгоритм: выбрать опорный элемент и разделить массив ещё раз на 2 части. Затем повторить то же самое для каждой части и т.д.
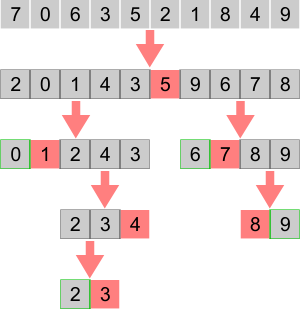
Сортировка каждой части заканчивается, когда мы получаем фрагмент массива длиной 2 элемента. Один из них – опорный, а второй находится либо слева, либо справа от него. Этот фрагмент полностью отсортирован. Также возможен фрагмент длиной в 1 элемент. Он, очевидно, тоже финальный. Общий отсортированный массив складывается из таких фрагментов:
Для начала напишем первую ступень алгоритма: выбор опорного элемента и размещение остальных элементов в левый или правый фрагмент.
Опорный элемент действительно можно выбрать любой, то есть например взять его из первой, последней, или вообще случайной позиции в массиве. Позиция этого элемента всё равно будет изменяться. Убирая, например, бо́льшие элементы из левой части и помещая их в правую часть, мы сокращаем левую часть и увеличиваем правую. Значит, сам опорный элемент должен сместиться влево, чтобы освободить место в правой части:
Так же и при перемещении меньшего элемента из правой части в левую размер частей меняется, а опорный элемент смещается вправо.
Чтобы избежать сложностей с правой и левой частью, в качестве опорного обычно берут последний элемент. То есть правая часть сразу получается пустая, и в неё затем попадают только те элементы из левой части, которые больше опорного элемента.
Итак, напишем первый этап на Питоне (если не помещается, см. ссылку):
Теперь всё, что осталось – повторить этот этап для всех полученных частей массива. Если опорный элемент имеет смещение pivot, то левая часть это элементы от 0 до pivot - 1, а правая часть это элементы от pivot + 1 до N - 1.
Повторяя алгоритм с каждой частью, мы получаем новые части, с которыми надо будет сделать то же самое. И тут мы понимаем, что необходима рекурсия. Этот первый этап нужно оформить как функцию, а затем заставить эту функцию вызывать саму себя с новыми параметрами (ссылка):
Всё, алгоритм работает! Осталось выяснить его вычислительную сложность.
Посмотрим для начала на самый плохой вариант: Опорный элемент выбран в последней позиции, а все остальные элементы – меньше его. Перебрав их все, мы так и не переместим ничего в правую часть. Значит, после первой итерации от массива длиной N останется опорный элемент и левая часть длиной N-1, над которой нужно опять повторить операцию. Мы берём опять крайний элемент, но он опять самый большой, так что мы получаем левую часть длиной N-2... где-то мы это уже видели, а именно в прошлых алгоритмах сортировки. Это последовательность
1 + 2 + 3 + ... + N
которая даёт нам оценку O(N²).
То есть наша, якобы quick, сортировка оказалась ничем не лучше какого-нибудь пузырька? Да, но это именно худший случай, когда массив уже отсортирован, и мы выбрали именно последний элемент в качестве опорного.
Что получается, если выбирать опорный элемент более удачно? Массив делится на 2 части. Затем каждая часть ещё на 2, и т.д.
И обратите внимание, что теперь мы сделали не N-1 уходов в следующий уровень рекурсии, а всего лишь 2. Это происходит потому, что на кажом следующем уровне мы сокращаем количество перебираемых элементов не на 1, как раньше, а примерно вдвое. Сложность данного алгоритма для среднеудачного случая официально определена как O(N log(N)), и я пока не могу дать её детальный расчёт. Но её можно понимать так: когда N растёт в квадрате, количество операций растёт лишь линейно от N. Что, конечно, очень хорошо.
Чтобы избежать худших вариантов и повысить распознавание лучших, алгоритм модифицировали разными способами. Это касается и более хитрого выбора опорной точки, и выбора альтернативных алгоритмов при определённых условиях. Всё это усложнения, которые вы сможете изучить уже самостоятельно. Главное – чётко понимать основной алгоритм.
Читайте дальше: