В этой статье я бы хотела собрать в одном месте инструменты для предварительной обработки данных. Ведь практически всегда прежде чем данные анализировать, их сначала надо привести в порядок. Например, в полученных данных исключить лишние пробелы или разбить текст по столбцам.
1. Удаление повторяющихся строк. Когда вы соединяете данные из разных баз может получиться так, что одна и таже строка повторяется в разных источниках. Для того, чтобы ее удалить, необходимо установить курсор в любую из ячеек диапазона ваших данных, на ленте перейти на вкладку Данные -> Работа с данными и нажать "Удалить дубликаты". Откроется диалоговое окно:
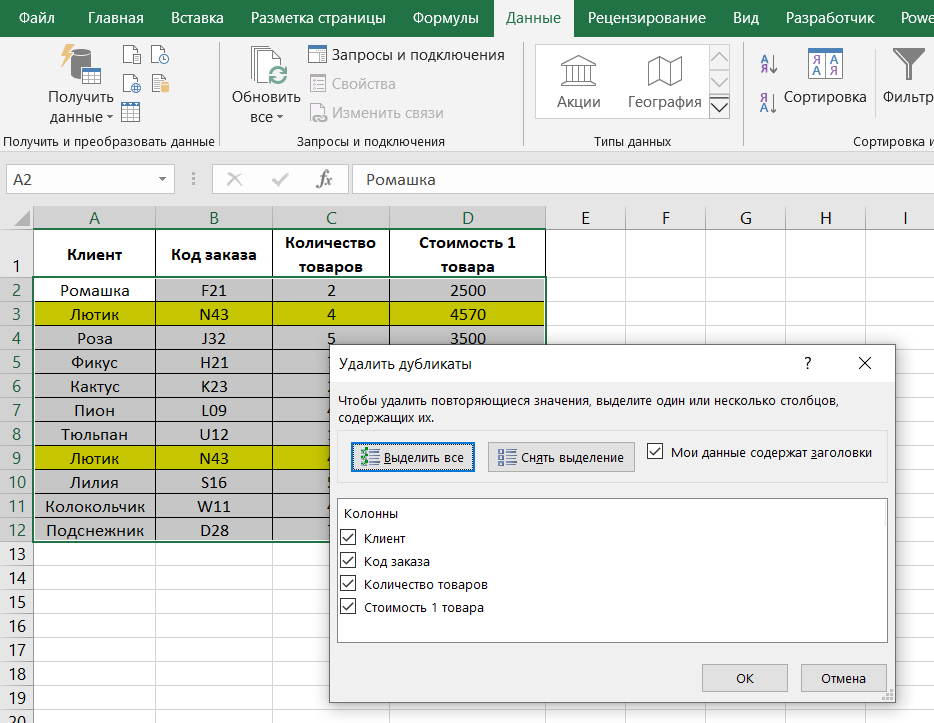
В открывшемся окне представлены столбцы, которые должны быть учтены при анализе на наличие дубликатов. Если вы отметите все столбцы, то дубликатом будут считаться строки, полностью совпадающие по всем значениям.
Если вы выделите, например, только первый столбец "Клиент", то при поиске дубликатов будет вестись поиск совпадения только по первому столбцу. При этом в случае наличия дубликата - первая строка в таблице останется, а все остальные будут удалены.
Как перевести текст из верхнего регистра в нижний или оставить только заглавную букву, а остальной текст сделать прописным - читайте в этой статье.
2. Разбивка текста по столбцам. Может случиться ситуация, когда в одном столбце окажутся значения, которые должны быть разбиты на разные ячейки. Для того, чтобы их разбить по столбцам, в excel есть удобный инструмент. Предположим, у нас есть список в столбце А:
Чтобы разбить его по столбцам, выделите весь список, убедитесь, что справа хватает места для его разбивки, перейдите на ленте во вкладку Данные -> Работа с данными -> Текст по столбцам. Откроется диалоговое окно "Мастер распределения текста по столбцам", в котором на первом шаге необходимо выбрать формат данных (в нашем случае с разделителями):
На втором шаге необходимо выбрать символ-разделитель (пробел). В нижнем окошке появится образец разделения данных:
На третьем шаге остается выбрать формат данных столбца (который потом можно будет поменять) и место, куда необходимо поместить разделенные данные:
В итоге мы получим вот такой результат:
3. Удаление лишних пробелов. Если в исходных данных есть лишние пробелы, их можно удалить с помощью формул. При этом бывает 2 вида лишних пробелов:
1. обычные пробелы, которых больше чем должно быть;
2. неразрывные пробелы, обозначенные в HTML-коде тегом   (такие пробелы обычно появляются при импортировании данных с веб-страниц).
Предположим, в списке ФИО клиентов есть лишние пробелы, при этом мы можем даже не знать какие:
С помощью формулы =СЖПРОБЕЛЫ(ПОДСТАВИТЬ(A2;СИМВОЛ(160);" ")) мы можем удалить оба вида пробелов. Разберем формулу подробнее:
- СИМВОЛ(160) - обозначает неразрывные пробел;
- ПОДСТАВИТЬ () - вместо неразрывного пробела подставляет обычный пробел;
- СЖПРОБЕЛЫ () - удаляет все лишние пробелы и оставляет по одному между словами.
Итогом работы формулы будет:
Подписывайтесь, чтобы первыми получать самые интересные публикации! Ещё больше полезных советов и лайфхаков Excel – в моем Telegram-канале!
Для удобства - статья навигатор по каналу: Путеводитель по каналу