Всем привет. С вами блог «Data and Intelligence» - Блог обо всем, что связанно с Искусственным интеллектом и обработкой данных. Нейронные сети, алгоритмы, обработка и представление данных… Все это в этом блоге. Добро пожаловать.
Сегодня мы рассмотрим пример, распознавание методом ближайших соседей, а также формальную постановку задачи обучения распознавателя – минимизацию эмпирического риска.
Видеоверсия статьи:
Распознаватель, который мы рассмотрим практически не нужно и обучать. Допустим у нас имеется обучающий набор из N объектов, с известными признаками х и ответами у.

В качестве ответов распознавателя для произвольного объекта х берется ответ у его ближайшего соседа по х из обучающего набора. Обоснуем такой ответ тем, что у нас нет больше никакой информации, и предположением, что ответы изменяются медленно.
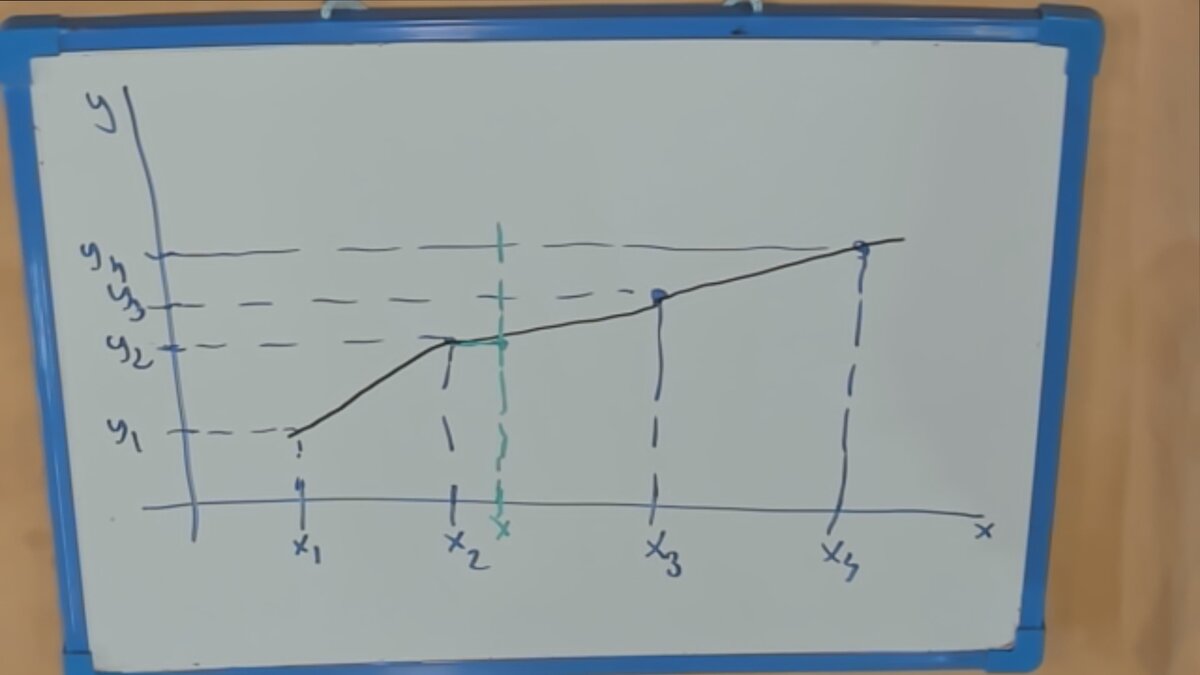
А что, если соседи равноудалены? Тогда выбираем или среднее или наиболее частое решение. Теперь мы можем расширить метод ближайшего соседа до метода к ближайших соседей при к больше 1.
В то время как распознавание методом ближайшего соседа при к = 1 не делает ошибок на обучающей выборке, но может ошибаться на неизвестных ему векторах признаков, распознавание при к больше 1 ближайших соседей может ошибаться в точках обучающей выборки, но меньше ошибается на неизвестных ему векторах.
Данный метод тривиален, и сводится к запоминанию обучающего набора. При этом трудоемкость этого метода растет пропорционально произведению объема обучающего набора и размерности пространства признаков.
Здесь можно предположить, что при росте обучающего набора, ошибка распознавания будет уменьшаться, однако и объем вычислений и необходимой памяти будет расти.
Также здесь присутствует эффект проклятия размерности – когда размерность пространства признаков большая, если допустимые вектора признаков не сосредоточенны около поверхности малой размерности, то шансов плотно заполнить интересующую нас область пространства обучающим набором нет.
Существуют различные способы формализовать задачу обучения. Максимизация правдоподобия, байесовский, максимизации апостериорной вероятности… мы пока что будем пользоваться минимизацией эмпирического риска в качестве формализации.
Итак. Имеется пространство векторов признаков Х, точками которого кодируются распознаваемые объекты. Имеется пространство ответов У, точками которого кодируются результаты распознавания.
Имеется пространство F распознавателей, пространство P распределений и функция штрафа Е, называемая также функцией ошибки, потерь, риска. Это, как правило, неотрицательная функция, равная 0 при совпадении прогнозируемого и истинного ответов.
В случае евклидова пространства, например, может применяться квадратичный штраф, а в случае дискретного пространства – штраф 0 или 1. Мы далее будем рассматривать штраф, не зависящий от пространства признаков.
Обучающий набор Т состоит из пар вектор признака – ответ. Они считаются независимыми случайными величинами, с не известным распределением p.
Обратим внимание на то, что не требуется однозначное определение правильного ответа у по значению признака х. Определено, но не известно, распределение вероятностей правильного ответа, имеющее плотность, зависящую от плотности распределения обучающего набора и плотности распределения векторов признаков.
Это все, что у нас имеется. Теперь, по всему этому набору нам хотелось бы построить распознаватель F, минимизирующий математическое ожидание штрафа Е для пространства векторов и ответов (х и у).
Такое желание выглядит странным, потому что нам ничего не известно про распределение p пространства признаков – ответов. Но на самом деле, обучающие данные Т являются случайными с распределением p, тем же самым, что и позволяет приблизить методом Монте-Карло ожидание штрафа суммой.
Эта величина называется средним штрафом обучения или средней ошибкой обучения, эмпирическим риском. Теперь попробуем подменить минимизацию интеграла минимизацией эмпирического риска.
Эта задача уже вполне решимая. Но распознаватель, полученный в итоге, зависит от обучающего набора Т, а распознаватель f не должен зависить от обучающего набора. Ожидание штрафа мы можем оценить по набору тестовых данных Т¢, по которым обучение не проводилось. Результат может быть плохим, особенно если пространство распознавателей большое, а количество обучающих векторов малое…
Сложно? Давайте рассмотрим пример алгоритма, обучаемого методом минимизации эмпирического риска… но в следующий раз.
На сегодня все, если вам интересна эта тема – ставьте лайк, напишите в комментарии свое мнение, это блог «Data and Intelligence» - всем пока.