Всем привет, продолжим тему регэкспов, и обсудим квантификаторы. Квантификатор — это символ, который указывает, сколько раз должен совпасть символ перед ним (или целое подвыражение).
Самый распространенный квантификатор — это звездочка *. Она означает "нуль или более раз". Сейчас обсудим ее и другие квантификаторы.
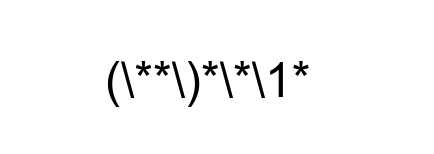
Подвыражения указываются в захватывающих скобках \( \) или незахватывающих \%\( \); при этом содержимое захватывающих доступно по номеру открывающей скобки как \1 и т.д. до \9, а незахватывающие чуть побыстрее работают (хотя в масштабах строки это незаметно).
Например, /\(42\)* совпадет с 42, 4242, 424242 и т.д. Впрочем, совпадет это выражение вообще всегда, там же нет ничего обязательного.
Очевидно, что квантификатор, который допускает нуль вхождений, совпадает всегда. Это может вызвать удивление: попробуйте предсказать результат замены :s/6*/42/ в строке "The number is 666".
Спойлер: от Числа Зверя вам так просто не избавиться!
Еще жутче будет результат, если добавить модификатор /g... Попробуйте для смеха на небольшом тексте выполнить команду :%s/6*/42/g
И даже неважно, есть у вас в тексте шестерки или их нет.
Можно написать /66*, имея в виду 6, 66, 666 и т.д.. Но есть специальный квантификатор для "Один или более" — это \+ (а не +, как в Перле и много где еще, или в Виме при ключе \v). Например,
/6\+ совпадет с 6, 66, 666 и т.д., но одна шестерка обязана быть.
Ноль-один — это \? или \= — на выбор. Он тоже совпадает всегда. Например,
/\w*\.\?\w\+ совпадает с именами файлов вида *.* или .* А выражение \(\w\+\.\)\?\w\+ — с файлами *.*
Кстати, в Виме /18+ совпадает с 18+ и более ни с чем. Плюс — это просто плюс. В режиме \v или в Перле иначе: 18+ совпадет с 18, 188, 1888 и т.п.
Более точные квантификаторы — это \{...\} - причем слеш перед второй скобкой можно не ставить! Между скобками либо число — тогда нужно ровно это количество; либо два числа через запятую — тогда от и до; либо одно число до или после запятой — это не менее и, соответственно, не более. Пустые скобки допускаются, это аналог *. Например:
6\{3} — это 666. 6\{3,4} — это 666 или 6666. 6\{3,} — это 6666*, а 6\{,3} — это "не более трех" (и совпадает всегда). А 6\{} — это то же, что и 6*.
Все квантификаторы жадные — забирают так много, как могут. Так, выражение \w*\(6*\)\1 в строке devil666666: символ \w* заберет все, а скобки уловят пустую строку, которая их устроит.
Сделать то, что подразумевалось, можно так: [a-z]\(6*\)\1, выведя цифры из рассмотрения. Или более сложными способами, если цифры там могут быть. Могут помочь и ленивые квантификаторы, о которых далее.
Ленивые квантификаторы, которые берут так мало, как это возможно, тоже существуют: надо поставить минус после скобки {.
Например, \{-} — это ленивая *, "нуль или больше", но так мало, как это возможно. А \{-1,} — это ленивый \+. Пример:
/42.*\./ совпадет с текстом от числа 42 до последней точки на строке; а /42\{-}\./ — с текстом между 42 и ближайшей точкой.
Или вот пример, который мы выше смотрели: \w\{-}\(6*\)\1 — как можно меньше алфавитно-цифровых символов, потом шестерок побольше (6*), но так, чтобы группа повторилась (\1): 666-666
Вот, например, IP-адрес. Его довольно трудно описать точно, но нам и не надо точно, нам надо его найти в тексте. Например:
\(\d\+\.\?\)\{4} совпадет с 126.0.0.1, и другими правильными адресами, но еще и с 666.666.666.666, с 123456789 (точки же не обязательны)...
Можно написать \(\d\{1,3}\.\)\{3}\d\{1,3} и теперь нужны 4 числа, разделенные точками, однако они могут быть слишком большими: 666.666.666.666 опять совпадет. Ну и ладно, я считаю)) Как указывать классы символов, поговорим в другой раз.
Пример полезности ленивых квантификаторов
Понадобилось мне однажды при редактировании чужой статьи в ТеХе убрать пробелы после открывающего и перед закрывающим знаком доллара в формулах. Меня раздражает такое: $ x+1 $.
Далее используются классы символов и захваты: если вы с этими понятиями не знакомы, можете далее пока не читать.
Формулы разные, известно одно: внутри формулы знаков доллара нет. Очевидно, что %s/\$\s\+\(.*\)\s\+\$/\1/g — детская ошибка, поскольку жадная звездочка заберет все между первым и последним знаками доллара на строке. Ничего жуткого не будет, но если формул больше одной — задание не будет выполнено.
Вариант %s/\$\s\+\([^$]*\)\s\+\$/\1/g лучше, потому что теперь жадная звездочка берет только не-доллары (это класс [^$])... но она заберет и пробел перед закрывающим долларом, ибо это не доллар.
Добавить в класс символов в [] пробел нельзя — пробелы могут быть в формуле. Возможны разные решения, конечно, но ленивая звездочка \{-}, на мой вкус, идеальна:
:%s/\$\s*\(.\{-}\)\s*\$/$\1$/g
Здесь захватывается все (.\{-}), что между долларом \$ (возможно c пробелами после него \s*) и первого же встретившегося доллара \$ (возможно с пробелами \s* перед ним). Первый же доллар даст ленивой звездочке \{-} возможность прекратить захват.
Важно! Найти совпадение важнее жадности и лени! Жадный берет как можно больше, но так, чтобы совпадение состоялось; ленивый как можно меньше, но ровно столько, чтобы совпадение состоялось.
Так, выражение \(6*\)6 в строке 666 совпадет со всей строкой (скобки захватят 66), а выражение \(6\{-}\)6 совпадет с первой шестеркой (скобки захватят пустую строку).
Аналогичная схема часто встречается при поиске ограничителей длиннее одного символа. Классическая задачка из учебника по регулярным выражениям — поиск тегов html.
О ней в другой раз расскажу.
Удачи, коллеги.