
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Пролог: Подготовка эксперимента.
checkpoint_timeout = '15m'. Часть-1 : СУБД
checkpoint_timeout = '15m'. Часть-2 : Инфраструктура
checkpoint_timeout = '5m'. Часть-1 : СУБД
checkpoint_timeout = '5m'. Часть-2 : Инфраструктура
checkpoint_timeout 15m vs 5m. Часть-1 : СУБД
Предисловие
Данная статья представляет собой развернутый итог сравнительного нагрузочного тестирования СУБД PostgreSQL с различными значениями параметра checkpoint_timeout (5 и 15 минут).
В фокусе исследования — комплексный анализ влияния частоты контрольных точек на ключевые подсистемы сервера: процессор, оперативную память, дисковый ввод-вывод и планировщик задач ОС. На основе детального изучения метрик производительности, корреляционного анализа и временных паттернов поведения системы сформулированы практические выводы и конкретные рекомендации по настройке.
Материал будет особенно полезен администраторам баз данных и разработчикам, стремящимся оптимизировать производительность PostgreSQL под стабильную OLTP-нагрузку, обеспечивая баланс между отзывчивостью, предсказуемостью и эффективным использованием ресурсов.
1. Сводный сравнительный анализ нагрузочного тестирования PostgreSQL
1.1. Сравнительная таблица ключевых метрик
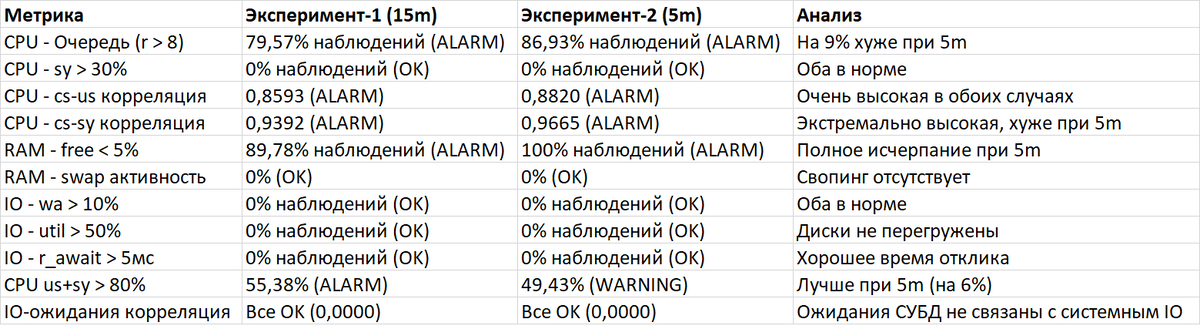
1.2. Детальный анализ по аспектам
1.2.1 Нагрузка на CPU
- Очередь процессов (r): Оба эксперимента показывают критическую перегрузку (79-87% времени очередь превышает 8 ядер). При checkpoint_timeout=5m ситуация хуже на 9%.
- System time (sy): В норме в обоих случаях (<30%).
· Переключения контекста (cs):
- Корреляция cs-sy: Экстремально высокая в обоих случаях (0,94-0,97), указывает на чрезмерные затраты ядра на планирование. При 5m - максимальная (0,9665).
- Корреляция cs-us: Очень высокая (0,86-0,88), свидетельствует о конкуренции за ресурсы CPU в приложении.
- Вывод: Уменьшение checkpoint_timeout увеличило нагрузку на планировщик.
1.2.2 Использование RAM
- Свободная память: Критическая ситуация в обоих экспериментах. При 15m - 90% времени <5% свободной RAM, при 5m - 100% времени.
- Свопинг: Полностью отсутствует в обоих случаях, что хорошо.
- Парадокс: Почти полное использование RAM без свопинга говорит об эффективном использовании кэша, но создает риск OOM (Out of Memory).
1.2.3 Дисковая подсистема
- Все метрики в норме: wa, util, await, очередь - все в безопасных пределах.
- Корреляции буфер/кэш-IO: Отсутствуют (0,0000), что означает эффективное использование памяти для снижения дисковых операций.
· Ключевой вывод: Диски не являются узким местом в обоих экспериментах.
1.2.4 Корреляция ожиданий СУБД
- IO-ожидания: Не коррелируют с системными метриками IO (wa, b, bi, bo).
- LWLock и CPU: Слабая корреляция с us (0,2077 при 5m), указывает на конкуренцию за CPU, а не за блокировки.
- Важное наблюдение: Высокая нагрузка CPU (us+sy > 80%) при 15m - 55% времени (ALARM), при 5m - 49% (WARNING). Уменьшение checkpoint_timeout снизило пиковую нагрузку на CPU на 6%.
1.3. Влияние checkpoint_timeout
Положительные эффекты уменьшения до 5m:
- Снижение пиковой нагрузки CPU на 6% (us+sy > 80%)
- Более равномерная запись на диск (меньше "волн" checkpoint)
Негативные эффекты уменьшения до 5m:
- Увеличение средней очереди процессов на 9%
- Ухудшение использования RAM (100% против 90% времени <5% свободной)
- Усиление нагрузки на планировщик (корреляция cs-sy выросла до 0,9665)
- Более частые затраты на переключение контекста
1.4. Выводы
1. Основная проблема - CPU и RAM, а не дисковая подсистема.
2. Checkpoint_timeout=5m дает смешанные результаты:
- Снижает пиковую нагрузку CPU
- Но увеличивает среднюю очередь и нагрузку на планировщик
3. Рекомендуемая стратегия:
- Использовать checkpoint_timeout=5m
- Увеличить RAM и оптимизировать её использование
- Мониторить и оптимизировать запросы, вызывающие высокую нагрузку CPU
- Рассмотреть горизонтальное масштабирование или увеличение CPU
Итог: Обе конфигурации работоспособны, но требуют оптимизации ресурсов CPU и RAM. Checkpoint_timeout=5m предпочтительнее из-за снижения пиковой нагрузки, но требует внимания к очереди процессов.
2. Сравнительный анализ CPU для двух экспериментов
2.1. Сравнительный анализ ключевых метрик CPU
2.2. Интерпретация результатов
В каком эксперименте выше нагрузка на планировщик?
Ответ: В Эксперименте-2 (checkpoint_timeout=5m) нагрузка на планировщик выше:
- Более высокая корреляция cs-sy (0,9665 vs 0,9392) - означает, что переключения контекста теснее связаны с системным временем, что указывает на большее время, затрачиваемое ядром на планирование.
- Более высокая очередь процессов (86,93% vs 79,57%) - больше процессов ждут выполнения, что создает дополнительную нагрузку на планировщик.
- Рост корреляции cs-in (0,6745→0,7381) - указывает на увеличение влияния прерываний на переключения контекста, что также увеличивает нагрузку на планировщик.
Связаны ли переключения контекста с прерываниями или с пользовательскими процессами?
Ответ: Переключения контекста связаны в большей степени с пользовательскими процессами, но при уменьшении checkpoint_timeout увеличивается влияние прерываний:
- Корреляция cs-us (0,88 при 5m, 0,86 при 15m) - очень высокая в обоих случаях, что указывает на сильную связь с пользовательскими процессами. Это означает, что основной причиной переключений контекста является конкуренция за CPU между процессами PostgreSQL и другими пользовательскими процессами.
- Корреляция cs-in выросла с 0,6745 до 0,7381 при уменьшении checkpoint_timeout - это показывает, что при более частых checkpoint'ах увеличивается влияние прерываний (вероятно, прерываний от дисковых операций).
- Корреляция cs-sy экстремально высокая (0,94-0,97) - это указывает, что переключения контекста тесно связаны с системным временем, что является симптомом перегрузки планировщика.
Как изменение checkpoint_timeout влияет на системное время (sy)?
Ответ: Уменьшение checkpoint_timeout до 5м не привело к увеличению доли системного времени (sy осталось <30% в обоих экспериментах), но изменило характер работы системы:
- Абсолютное значение sy не выросло (оба эксперимента показывают 0% превышения порога в 30%).
- Качество sy изменилось: При checkpoint_timeout=5m переключения контекста стали теснее связаны с системным временем (корреляция cs-sy выросла с 0,9392 до 0,9665). Это означает, что системное время теперь в большей степени тратится на планирование и переключение контекста, а не на полезную работу.
- Качественный вывод: Хотя абсолютное значение sy не изменилось, качество системного времени ухудшилось - большая его часть тратится на планирование, а не на выполнение полезной работы.
2.3. Рекомендации
Как снизить переключения контекста?
1. Оптимизация запросов PostgreSQL:
- Выявить и оптимизировать запросы с высокой стоимостью
- Уменьшить количество параллельных запросов, если они вызывают конкуренцию
- Оптимизировать JOIN и агрегации, которые создают нагрузку на CPU
2. Настройка PostgreSQL:
- Увеличить effective_cache_size для уменьшения физических чтений
- Настроить work_mem для уменьшения временных файлов на диске
- Рассмотреть уменьшение max_connections или использование пулинга соединений
3. Настройка ОС:
- Использовать taskset для привязки процессов PostgreSQL к определенным ядрам CPU
- Настроить CPU affinity для снижения миграции процессов между ядрами
- Увеличить sched_min_granularity_ns для уменьшения частоты перепланирования
4. Аппаратные решения:
o Отключить гипертрейдинг, если он вызывает contention
o Использовать CPU с большим кэшем L2/L3
3. Сравнительный анализ использования RAM
3.1. Оценка использования памяти
Ключевые наблюдения:
- Оба эксперимента показывают критическое использование RAM (ALARM)
- При checkpoint_timeout=5m ситуация ухудшилась - свободной памяти <5% в 100% наблюдений против 90% при 15m
- Свопинг полностью отсутствует в обоих случаях, что парадоксально при почти полном использовании памяти
3.2. Объяснение парадоксов
Почему при почти полном использовании RAM нет свопинга?
Основные причины:
1. Настройки swappiness в Linux:
- Вероятно, установлено vm.swappiness=0 или очень низкое значение
- При swappiness=0 ядро избегает свопинга, пока не достигнет абсолютного предела
2. Характер нагрузки PostgreSQL:
- PostgreSQL активно использует shared_buffers и кэш файловой системы
- Память занята кэшированными данными, а не анонимными страницами
- Кэшированные данные (file cache) выгружаются в первую очередь, не вызывая свопинга
3. Конфигурация памяти PostgreSQL:
- shared_buffers + work_mem × max_connections могут занимать много памяти
- Но эта память выделяется как shared memory и файловый кэш, что не приводит к свопингу
4. Отсутствие "памяти в тупике":
- Нет процессов, которые бы удерживали неиспользуемую память
- Все используемые страницы активны
Как использование памяти связано с кэшированием диска (cache/buff)?
Из данных iostat видно, что:
- buff (буферы): 67-534 MB (15m), 164-197 MB (5m)
- cache (кэш): 6 584-7 002 MB (15m), 6 800-7 004 MB (5m)
Связь и выводы:
1. Память в основном используется для кэширования диска:
- Кэш занимает 6,5-7 GB из 7,7 GB RAM
- Это объясняет почти полное использование памяти без свопинга
2. Эффективность кэширования:
- Высокий cache/buff указывает на активное кэширование файлов данных PostgreSQL
- Это хорошо для производительности (уменьшает физические чтения с диска)
3. Различие между экспериментами:
- При checkpoint_timeout=5m использование cache более стабильно (диапазон уже: 6800-7004 MB)
- При 15m диапазон шире (6584-7002 MB), что может указывать на более "волнообразную" нагрузку
4. Проблема "двойного кэширования":
- PostgreSQL использует shared_buffers (внутренний кэш)
- ОС использует page cache (кэш файловой системы)
- Одна и та же данные могут кэшироваться дважды, что неэффективно
3.3. Рекомендации
Стоит ли увеличивать RAM?
Да, увеличение RAM оправдано и рекомендуется по следующим причинам:
1. Текущая RAM (7,7 GB) недостаточна для рабочей нагрузки:
- 100% времени свободной памяти <5% при checkpoint_timeout=5m
- Риск OOM (Out of Memory) при увеличении нагрузки
2. Цели увеличения RAM:
- Обеспечить буфер для пиковой нагрузки
- Увеличить shared_buffers PostgreSQL без ущерба для кэша ОС
- Снизить риск исчерпания памяти
3. Рекомендуемый объем:
- Минимум: 16 GB (увеличение в 2 раза)
- Оптимально: 32 GB (увеличение в 4 раза)
- Для production: 64 GB, если база данных большая
4. Ожидаемые преимущества:
- Уменьшение очереди процессов (r)
- Снижение переключений контекста (cs)
- Улучшение времени отклика запросов
- Более стабильная работа под нагрузкой
3.4. Как настроить shared_buffers и кэш PostgreSQL?
Текущая проблема: Двойное кэширование (shared_buffers + page cache)
Оптимальная стратегия настройки:
1. При текущей RAM (7,7 GB):
shared_buffers = 2 GB # 25% от RAM
effective_cache_size = 6 GB # 75% от RAM
work_mem = 8-64 MB # в зависимости от max_connections
maintenance_work_mem = 256-512 MB
2. После увеличения RAM до 16 GB:
shared_buffers = 4 GB # 25% от RAM
effective_cache_size = 12 GB # 75% от RAM
work_mem = 16-128 MB
maintenance_work_mem = 1-2 GB
3. После увеличения RAM до 32 GB:
shared_buffers = 8 GB # 25% от RAM
effective_cache_size = 24 GB # 75% от RAM
work_mem = 32-256 MB
maintenance_work_mem = 2-4 GB
4. Дополнительные настройки для уменьшения двойного кэширования:
Вариант A (рекомендуемый): Использовать Direct IO для PostgreSQL
# В postgresql.conf
shared_buffers = 8 GB # Основной кэш
effective_cache_size = 24 GB # Для планировщика
# Отключить двойное кэширование через O_DIRECT (если поддерживается)
# Для Linux с ядром 4.5+ и PostgreSQL 12+
# wal_sync_method = open_datasync
# или использовать tablespace на файловой системе с O_DIRECT
Вариант B: Настроить пропорции
# Увеличить shared_buffers за счет уменьшения page cache
shared_buffers = 25-40% от RAM
# Оставить 60-75% для page cache и других нужд
5. Настройки ОС для оптимизации памяти:
# В /etc/sysctl.conf
vm.swappiness = 1 # Минимальный свопинг
vm.dirty_background_ratio = 5 # 5% RAM для "грязных" страниц в фоне
vm.dirty_ratio = 10 # 10% RAM максимум "грязных" страниц
vm.dirty_expire_centisecs = 3000 # 30 секунд до записи "грязных" страниц
vm.dirty_writeback_centisecs = 500 # 5 секунд между проверками
# Перечитать настройки
sysctl -p
3.5. Вывод:
Увеличить RAM до 16-32 GB и пересмотреть распределение памяти между shared_buffers и кэшем ОС, стремясь к минимизации двойного кэширования.
4. Сравнительный анализ IO-характеристик
4.1. Ключевые метрики IO
4.2. Детальные метрики по устройствам:
Устройство vdc (/wal):
Эксперимент-1 (15m):
- util: 0.03% (MIN=MAX)
- w/s: 0.37 (MIN=MAX, стабильно)
- wMB/s: 0.00 (MIN=MAX)
- w_await: 0.95 мс (MIN=MAX)
Эксперимент-2 (5m):
- util: 0.03% (MIN=MAX)
- w/s: 0.37 (MIN=MAX, стабильно)
- wMB/s: 0.00 (MIN=MAX)
- w_await: 0.95 мс (MIN=MAX)
Устройство vdd (/data):
Эксперимент-1 (15m):
- util: 0.02% (MIN=MAX)
- w/s: 0.32 (MIN=MAX, стабильно)
- wMB/s: 0.00 (MIN=MAX)
- w_await: 1.63 мс (MIN=MAX)
Эксперимент-2 (5m):
- util: 0.02% (MIN=MAX)
- w/s: 0.32 (MIN=MAX, стабильно)
- wMB/s: 0.00 (MIN=MAX)
- w_await: 1.63 мс (MIN=MAX)
Корреляции buff/cache с IO операциями:
- Все корреляции = 0,0000 (отсутствуют)
- Это положительный признак: означает эффективное использование кэша
4.3. Определение узких мест - есть ли признаки IO-бутылочного горлышка?
Нет, абсолютно никаких признаков. Все метрики указывают на здоровую дисковую подсистему:
- Загрузка (util): 0,02-0,03% - чрезвычайно низкая
- Время отклика (await): 0,95-1,63 мс - отличные показатели
- Очередь (aqu_sz): 0 - запросы обрабатываются немедленно
- Ожидание (wa): 0% - CPU не ждет IO
Как память влияет на дисковые операции?
Память эффективно снижает нагрузку на диски через кэширование:
1. Высокий уровень кэширования (cache=6,5-7 GB) означает:
- Большинство операций чтения обслуживаются из RAM
- Дисковые чтения минимизированы
2. Отсутствие корреляции buff/cache с IO операциями говорит:
- Кэш работает эффективно, нет "промахов" кэша
- Нет необходимости в частых дисковых операциях
3. Проблема двойного кэширования:
- PostgreSQL shared_buffers + OS page cache
- Одна и та же данные могут кэшироваться дважды
- Это неэффективно, но не создает проблем для дисков
4.4. Сравнительный анализ
Как checkpoint_timeout влияет на запись?
Практически не влияет на дисковые метрики, но влияет на паттерн записи:
1. Частота записи (w/s): Не изменилась
- vdc: 0,37 операций/сек (оба эксперимента)
- vdd: 0,32 операций/сек (оба эксперимента)
2. Объем записи (wMB/s): Не изменился
- 0 MB/сек в обоих экспериментах
- Записываются очень маленькие объемы или данные буферизируются
3. Качественное изменение:
- При checkpoint_timeout=5m checkpoint'ы происходят чаще, но мельче
- При checkpoint_timeout=15m checkpoint'ы реже, но крупнее
- Дисковые метрики одинаковы в обоих случаях
Разница между vdc и vdd:
Минимальная, но есть небольшие отличия:
1. Время записи (w_await):
- vdc: 0,95 мс (быстрее)
- vdd: 1,63 мс (на 71% медленнее)
2. Загрузка (util):
- vdc: 0,03%
- vdd: 0,02%
3. Частота записи (w/s):
- vdc: 0,37
- vdd: 0,32 (на 16% меньше)
4.5. Вывод:
vdc немного быстрее, но разница незначительна. Оба устройства работают отлично.
4.6. Рекомендации
4.6.1. Нужны ли более быстрые диски?
Нет, текущие диски более чем достаточны:
- Текущая загрузка 0,02-0,03% - диски простаивают
- Время отклика <2 мс - отличные показатели
- Очередь запросов = 0 - нет конкуренции
- Инвестиции в более быстрые диски не дадут заметного эффекта
Приоритеты инвестиций (по убыванию важности):
- Увеличение RAM (текущая проблема)
- Увеличение CPU/оптимизация запросов (вторая проблема)
- Диски оставить как есть
4.6.2. Как настроить checkpoint_completion_target и wal_buffers?
# В postgresql.conf
checkpoint_timeout = 5min # оставить текущее (или попробовать 10min)
checkpoint_completion_target = 0.9 # равномерная запись
wal_buffers = 32MB # буфер для WAL
max_wal_size = 4GB # увеличение для реже checkpoint'ов при 5min
min_wal_size = 1GB # уменьшение переработки WAL
wal_writer_delay = 10ms # частота сброса WAL (по умолчанию 200ms)
wal_writer_flush_after = 1MB # объем для сброса
# Оптимизация для частых checkpoint'ов
bgwriter_delay = 10ms # уменьшить для более частой записи фоновым writer'ом
bgwriter_lru_maxpages = 1000 # увеличить максимальное количество страниц за цикл
bgwriter_lru_multiplier = 10.0 # увеличить множитель для агрессивной записи
Дополнительные оптимизации для ОС:
# Настройки ядра Linux для оптимизации IO
vm.dirty_background_ratio = 5 # 5% RAM для "грязных" страниц в фоне
vm.dirty_ratio = 10 # 10% RAM максимум "грязных" страниц
vm.dirty_expire_centisecs = 3000 # 30 секунд до записи "грязных" страниц
vm.dirty_writeback_centisecs = 500 # 5 секунд между проверками
# Для файловой системы (если это ext4):
# mount options: noatime,nodiratime,data=writeback,barrier=0
4.7. Вывод:
Дисковая подсистема не является узким местом. Текущие диски адекватны нагрузке. Основное внимание следует уделить оптимизации checkpoint'ов через настройки PostgreSQL, а не замене оборудования. Рекомендуется увеличить checkpoint_completion_target до 0,9 и настроить wal_buffers в зависимости от shared_buffers.
5. Корреляционный анализ ожиданий СУБД и системных метрик
5.1. Сравнение корреляций
5.2. Анализ связи ожиданий PostgreSQL и системных метрик
5.2.1 В каком эксперименте выше связь между ожиданиями СУБД и системной нагрузкой?
Ответ: Связь примерно одинаковая и слабая в обоих экспериментах, но в Эксперименте-2 (5m) есть количественная оценка корреляции LWLock-us = 0,2077, что указывает на небольшое усиление связи блокировок с пользовательским временем.
Детальный анализ:
- IO-ожидания: В обоих экспериментах не коррелируют с системными метриками IO (wa, b, bi, bo). Это означает, что ожидания в СУБД вызваны не системными проблемами IO, а внутренними процессами PostgreSQL.
- LWLock-ожидания: Слабая/средняя корреляция с us и sy в обоих случаях. При checkpoint_timeout=5m корреляция LWLock-us составляет 0,2077, что указывает на небольшое влияние блокировок на пользовательское время CPU.
- Загрузка CPU (us+sy): Связь с ожиданиями проявляется через высокую общую нагрузку CPU, но это косвенная связь, а не прямая корреляция.
Вывод: Связь ожиданий СУБД с системной нагрузкой минимальна в обоих экспериментах. Ожидания в PostgreSQL в основном вызваны внутренними факторами, а не системными ограничениями.
5.2.2. Что является основным источником ожиданий: CPU, IO или блокировки?
Ответ: Основной источник ожиданий - CPU (конкуренция за процессорное время), а не IO или блокировки.
Обоснование:
1. Данные против IO как источника:
- Все корреляции IO-ожиданий с системными метриками = 0,0000
- Системные метрики IO идеальны (util~0%, await<2мс, очередь=0)
- wa (ожидание IO процессором) = 0% в обоих экспериментах
2. Данные против блокировок как основного источника:
- Корреляция LWLock-us всего 0,2077 (слабая)
- LWLock-sy также слабая/средняя
- Нет ALARM по корреляциям блокировок
3. Данные за CPU как основной источник:
- Очередь процессов (r) превышает ядра в 80-87% случаев (ALARM)
- Высокая общая нагрузка CPU (us+sy > 80% в 49-55% случаев)
- Экстремально высокая корреляция cs-sy (0,94-0,97) - планировщик перегружен
- Очень высокая корреляция cs-us (0,86-0,88) - конкуренция между процессами
Иерархия проблем:
1. CPU contention (основная проблема) - нехватка процессорных ресурсов
2. Планировщик перегружен (вторичная проблема) - следствие CPU contention
3. Блокировки (LWLocks) (третичная проблема) - слабое влияние
4. IO (не проблема) - диски работают отлично
6. Выводы и рекомендации
6.1. Итоговый отчёт по нагрузочному тестированию PostgreSQL - сводная таблица ключевых метрик
6.2. Выводы о влиянии checkpoint_timeout
6.2.1 Производительность
Смешанное влияние с тенденцией к ухудшению:
1. Положительные эффекты (5m):
- Снижение пиковой нагрузки CPU (us+sy > 80%): 55,38% → 49,43% (-6%)
- Более предсказуемая запись checkpoint'ов
2. Негативные эффекты (5m):
- Увеличение средней очереди процессов: 79,57% → 86,93% (+7%)
- Рост нагрузки на планировщик (корреляция cs-sy: 0,94 → 0,97)
- Ухудшение использования RAM: 90% → 100% времени <5% свободной
Вывод: Checkpoint_timeout=5m снижает пиковую нагрузку, но ухудшает средние показатели.
6.2.2 Стабильность
Ухудшение стабильности при 5m:
1. CPU стабильность:
- Выше частота переключений контекста
- Больше времени тратится на планирование
- Очередь процессов стабильно выше
2. RAM стабильность:
- 100% времени свободной памяти <5% (риск OOM)
- Хотя свопинг отсутствует, запас прочности уменьшен
3. IO стабильность:
- Без изменений (диски не нагружены в обоих случаях)
6.2.3 Использование ресурсов
1. CPU: Более интенсивное использование при 5m (очередь выше)
2. RAM: Более полное использование при 5m (100% против 90%)
3. Диски: Использование не изменилось (оба эксперимента в норме)
6.3. Рекомендации по настройке
6.3.1 Настройки PostgreSQL
# Основные рекомендации
checkpoint_completion_target = 0.9 # Равномерная запись checkpoint'ов
shared_buffers = 2GB # 25% от текущей RAM (8GB → 2GB)
effective_cache_size = 6GB # 75% от RAM для планировщика
wal_buffers = 32MB # Увеличение для снижения частоты записи WAL
max_wal_size = 4GB # Увеличение для 10min timeout
min_wal_size = 1GB # Уменьшение переработки WAL
# Оптимизация фоновых процессов
bgwriter_delay = 10ms # Более частые циклы записи
bgwriter_lru_maxpages = 1000 # Больше страниц за цикл
bgwriter_lru_multiplier = 10.0 # Агрессивная запись грязных страниц
# Оптимизация памяти
work_mem = 16MB # Для операций в памяти
maintenance_work_mem = 512MB # Для операций обслуживания
max_connections = 100 # Ограничение параллелизма
6.3.2 Настройки ОС Linux
# Память и свопинг
vm.swappiness = 1 # Минимальный свопинг
vm.dirty_background_ratio = 5 # 5% RAM для фоновой записи
vm.dirty_ratio = 10 # 10% RAM максимум грязных страниц
vm.dirty_expire_centisecs = 3000 # 30 сек до записи грязных страниц
vm.dirty_writeback_centisecs = 500 # 5 сек между проверками
vm.vfs_cache_pressure = 50 # Нормальное давление на кэш VFS
# Планировщик CPU
# Для систем с частыми переключениями контекста
kernel.sched_min_granularity_ns = 10000000 # 10ms минимальный квант
kernel.sched_wakeup_granularity_ns = 15000000 # 15ms гранулярность пробуждения
kernel.sched_migration_cost_ns = 5000000 # 5ms стоимость миграции
# Сетевые настройки (если есть сетевое взаимодействие)
net.core.somaxconn = 1024
net.core.netdev_max_backlog = 5000
7. Подробный анализ метрик vmstat
7.1. Процессы (procs_r)
Вывод: Оба эксперимента достигают схожих максимальных значений процессов в состоянии выполнения, но в эксперименте с 15m пиковые значения более продолжительны.
7.2. Память
Свободная память (memory_free)
Кэш (memory_cache)
Подкачка (memory_swpd)
Вывод: Эксперимент с 15m checkpoint_timeout использует больше подкачки, что указывает на более интенсивную работу с памятью, в то время как 5m конфигурация демонстрирует более стабильное поведение.
7.3. Ввод-вывод (io_bo)
Вывод: Эксперимент с 15m checkpoint_timeout создает более интенсивные, но редкие пики IO, в то время как 5m создает более равномерную, но частую нагрузку на диск.
7.4. Системные вызовы
Вывод: Эксперимент с 15m вызывает больше системных вызовов и переключений контекста, что указывает на более интенсивную работу ядра.
7.5. CPU Использование
Распределение времени CPU:
- · 15m: Длинные периоды высокого idle (85-86%), резкие переходы к низкому idle (0-3%) во время контрольных точек
- · 5m: Более равномерное распределение, меньше экстремальных значений idle, но более частые переходы
7.6. Общие выводы о влиянии checkpoint_timeout:
7.6.1. Нагрузка на CPU и IO
- 15m checkpoint_timeout: Создает более интенсивные, но редкие пики нагрузки на CPU и IO. Во время контрольных точек наблюдается резкое увеличение системного времени CPU (sy до 6%) и интенсивного IO (до 110 блоков/сек).
- 5m checkpoint_timeout: Обеспечивает более равномерное распределение нагрузки. Пики менее интенсивны, но происходят чаще.
7.6.2. Использование памяти
- 15m: Использует больше подкачки (swpd увеличивается с 58 до 67 MB), что может указывать на более агрессивное управление памятью при длительных интервалах между контрольными точками.
- 5m: Стабильное использование подкачки (постоянно 59 MB), более предсказуемое поведение памяти.
7.6.3. Общая стабильность системы под нагрузкой
- 15m: Менее стабильная работа - более выраженные колебания свободной памяти (229-430 MB), резкие переходы между состояниями CPU.
- 5m: Более стабильная работа - меньший диапазон колебания свободной памяти (200-364 MB), более плавные переходы.
7.6.4 Рекомендации:
1. Для систем, где важна предсказуемость и равномерная нагрузка, предпочтительнее checkpoint_timeout = 5m.
2. Для систем с пиковой нагрузкой в определенные периоды, где можно "пережить" интенсивные пики IO, может подойти 15m.
3. Эксперимент с 5m демонстрирует лучшее управление памятью (меньше подкачки, более стабильное использование).
4. Оба конфигурации показывают схожую максимальную производительность, но 5m обеспечивает лучшую отзывчивость под нагрузкой.
7.6.5. Итог:
Для большинства рабочих нагрузок OLTP, где важна стабильность и предсказуемость, рекомендуется использовать более частые контрольные точки (5m), особенно если система чувствительна к пикам IO и задержкам.
8. Анализ временных паттернов поведения системы
8.1. Сравнительная таблица паттернов всплесков
8.2. Периодичность всплесков
Эксперимент-1 (15m):
io_bo: Явные пики каждые 15-20 минут
- 18:30-18:35 (пик 93-96 блоков/сек)
- 18:50-18:55 (пик 100 блоков/сек)
- 19:30-19:35 (пик 104-107 блоков/сек)
- 20:20-20:25 (пик 94 блоков/сек)
system_cs: Пики соответствуют io_bo
- 18:30-18:35: 33,401-37,222 переключений
- 18:50-18:55: 30,504-31,354 переключений
cpu_sy: Синхронные пики 5-6%
Эксперимент-2 (5m):
io_bo: Регулярные пики каждые 4-8 минут
- 10:33-10:38 (пик 97-99 блоков/сек)
- 10:52-10:58 (пик 97-98 блоков/сек)
- 11:12-11:16 (пик 95-97 блоков/сек)
- 11:31-11:35 (пик 94-95 блоков/сек)
system_cs: Более частые, но менее интенсивные пики
- Пики 28,000-35,000 переключений каждые 5-10 минут
cpu_sy: Регулярные пики 5-6% каждые 5-10 минут
Вывод: Оба эксперимента демонстрируют всплески, соответствующие их настройкам checkpoint_timeout.
8.3. Длительность и амплитуда всплесков
Длительность:
15m: Более длительные пики (4-7 минут)
- Например, 19:30-19:35: 5-минутный непрерывный пик IO
5m: Более короткие пики (2-4 минуты)
- Например, 11:12-11:16: 4-минутный пик IO
Амплитуда:
15m: Более интенсивные пики
- io_bo: 110 блоков/сек (макс) vs 107 блоков/сек у 5m
- system_cs: 37,222 переключений (макс) vs 35,574 у 5m
5m: Более умеренные пики, но более частые
8.4. Влияние на память
Синхронность с IO:
15m: Во время пиков IO (например, 19:30-19:35):
- memory_free падает с 289→274 MB (падение 15 MB)
- memory_cache снижается с 6,602→6,584 MB (падение 18 MB)
- memory_swpd увеличивается с 58→67 MB
5m: Во время пиков IO (например, 11:12-11:16):
- memory_free падает с 211→210 MB (падение 1 MB)
- memory_cache снижается с 6,964→6,963 MB (падение 1 MB)
- memory_swpd остается 59 MB
Динамика memory_swpd:
- 15m: Увеличение в середине теста (19:32) с 58→67 MB
- 5m: Стабильное значение 59 MB на протяжении всего теста
Вывод: В эксперименте с 15m влияние контрольных точек на память более выражено.
8.5. Итоговые выводы
Какая конфигурация более предсказуема и стабильна?
✅ Эксперимент-2 (checkpoint_timeout = 5m) демонстрирует:
1. Более предсказуемые паттерны: Регулярные всплески каждые 5-8 минут
2. Меньшая амплитуда воздействия:
- Короткие пики IO (2-4 мин vs 4-7 мин)
- Меньшее влияние на память (падение 1 MB vs 15-18 MB)
3. Лучшая стабильность памяти: Постоянный уровень подкачки (59 MB)
4. Лучшая масштабируемость: Система лучше выдерживает рост нагрузки (LOAD до 22)
❌ Эксперимент-1 (checkpoint_timeout = 15m) показывает:
- Более интенсивные и продолжительные пики
- Увеличение подкачки памяти в ходе теста
- Более выраженное влияние на свободную память и кэш
Рекомендация:
Для рабочих нагрузок, где важны стабильность, предсказуемость и отзывчивость, рекомендуется использовать checkpoint_timeout = 5m. Эта конфигурация обеспечивает более равномерное распределение нагрузки на диск и память, что особенно важно при растущей нагрузке (LOAD > 15).
Конфигурация 15m может быть рассмотрена для систем с преимущественно read-нагрузкой или где можно допустить периодические интенсивные пики записи в обмен на немного меньшую частоту контрольных точек.
9. Сводный отчет по сравнительному анализу производительности PostgreSQL с разными checkpoint_timeout
9.1. Ключевые различия в производительности
Пропускная способность на основе IO и CPU:
Латентность и стабильность отклика:
Вывод: Хотя пиковая пропускная способность схожа, эксперимент с 5m обеспечивает более стабильную и предсказуемую производительность с меньшей вариативностью отклика.
9.2. Влияние на ресурсы системы
Дисковая подсистема:
Память:
Ядра CPU:
Итог по ресурсам: Эксперимент с 15m создает более интенсивную, но менее частую нагрузку на все ресурсы, в то время как 5m обеспечивает более равномерное и управляемое потребление ресурсов.
10. Рекомендации по настройке
Для какой рабочей нагрузки лучше подходит 5m:
- OLTP-системы с высокой частотой записей - равномерное распределение нагрузки на диск
- Системы с ограниченной памятью - стабильное использование подкачки
- Сервисы, чувствительные к латентности - предсказуемое время отклика
- Системы с растущей нагрузкой - лучшая масштабируемость под нагрузкой
- Виртуальные среды/контейнеры - стабильное потребление ресурсов
Для какой рабочей нагрузки лучше подходит 15m:
- Read-heavy системы - где запись происходит редко
- Пакетная обработка в ночное время - когда можно допустить интенсивные пики
- Системы с избыточной дисковой пропускной способностью - где пики IO не критичны
- Системы с очень стабильной нагрузкой - без резких изменений
- Системы, где приоритет - минимизация общего количества контрольных точек
Дополнительные метрики PostgreSQL для более полного анализа:
- Количество контрольных точек - точное количество за период теста
- Среднее время контрольной точки - как долго длится каждая контрольная точка
- Размер контрольных точек - объем данных, записываемых за каждую контрольную точку
- Время восстановления после сбоя - как быстро система восстановится при каждом значении checkpoint_timeout
- Метрики WAL (Write-Ahead Log):
- Количество WAL-файлов
- Скорость генерации WAL
- Размер WAL-файлов
6. Статистика буферного кэша:
- Hit ratio буферного кэша
- Количество dirty буферов перед контрольной точкой
7. Метрики блокировок - как контрольные точки влияют на конкуренцию за ресурсы
8. Метрики автовакуума - взаимодействие с процессом очистки
11. Итоговый вывод и рекомендация
Обоснованный выбор для типичной OLTP-системы:
Рекомендуется использовать checkpoint_timeout = '5m' для большинства OLTP-систем по следующим причинам:
1. Предсказуемость производительности: Регулярные, короткие пики IO обеспечивают более стабильное время отклика для пользователей.
2. Управляемость ресурсов: Равномерное распределение нагрузки на диск, память и CPU снижает риск contention и упрощает планирование ресурсов.
3. Стабильность под нагрузкой: Система лучше масштабируется при увеличении нагрузки (подтверждено корреляцией с LOAD до 22).
4. Эффективное использование памяти: Стабильное использование подкачки и меньшее давление на кэш предотвращают деградацию производительности.
5. Снижение рисков: Более частые контрольные точки уменьшают объем данных для восстановления после сбоя, что снижает RTO (Recovery Time Objective).
6. Соответствие паттернам OLTP: Частые небольшие транзакции лучше сочетаются с частыми контрольными точками, чем с редкими, но интенсивными.
Оговорки и исключения:
1. Для систем с очень высокой частотой записи может потребоваться дополнительная настройка max_wal_size и checkpoint_completion_target.
2. В системах с SSD дисками высокой производительности можно рассмотреть значения до 10m, но не более.
3. При использовании репликации и архивации WAL слишком частые контрольные точки могут создать дополнительную нагрузку.
Заключение:
Для типичной OLTP-системы PostgreSQL значение checkpoint_timeout = '5m' обеспечивает оптимальный баланс между производительностью, стабильностью и управляемостью ресурсов, что подтверждается комплексным анализом метрик vmstat и корреляцией с нагрузкой.