
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Предыдущие эксперименты
Предисловие:
В мире PostgreSQL существуют устоявшиеся рекомендации по настройке checkpoint_timeout, часто принимаемые на веру. Но насколько они универсальны и справедливы для сценариев с высокой конкуренцией? Данная статья представляет собой полноценное исследование, где не просто тестируется, а проверяются гипотезы. Используя Демобазу 2.0 как эталон сложной схемы, инструмент pg_expecto для сбора точных метрик и нейросеть DeepSeek для выявления неочевидных корреляций.
Цель — перейти от догм к данным, получив доказательную базу для настройки под конкретную нагрузку.
❓Наиболее частые рекомендации по настройке checkpoint_timeout сходятся на значении 15-30 минут для production-систем, что значительно выше стандартных 5 минут (7).
📝 Основные рекомендации и логика
Основная идея — увеличить интервал между контрольными точками, чтобы:
Однако это компромисс:
- Плюс: Повышение общей пропускной способности и стабильности работы.
❓Согласно EnterpriseDB, польза от увеличения параметра подчиняется закону убывающей отдачи. Например, рост с 5 до 10 минут даст заметный прирост, а с 20 до 40 — уже гораздо менее значительный.
💎 Краткий чек-лист для эксперимента
- Базовый уровень: checkpoint_timeout = ❗15min, max_wal_size — достаточно большой (например, 8GB для начала), checkpoint_completion_target = 0.9.
- Что варьировать: В ходе тестов увеличение checkpoint_timeout (1мин, 5мин, 10мин, 15мин, 20мин, 30мин).
🔬 Начальная гипотеза (General Hypothesis)
❓При увеличении checkpoint_timeout с 5 минут (по умолчанию) до 15-30 минут производительность СУБД PostgreSQL под смешанной OLTP-нагрузкой повысится, что выразится в увеличении операционной скорости и снижении ожиданий СУБД. Однако после достижения "точки перегиба" (ориентировочно 30-60 минут) дальнейший рост интервала не даст значимого прироста производительности .
📉 Ожидаемое влияние на ключевые метрики
Вот как, согласно гипотезе, изменение параметра повлияет на конкретные наблюдаемые показатели:
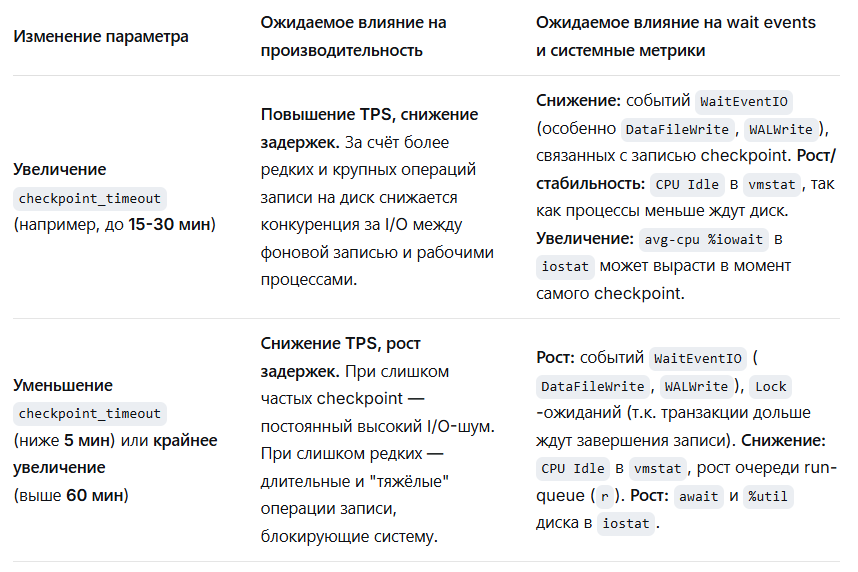
🎯 Ключевые метрики и ожидаемые значения для подтверждения гипотезы
Для проверки гипотезы сфокусируйтесь на этих метриках и их пороговых значениях:
1. Ожидания PostgreSQL (wait_event):
- Гипотеза подтверждается, если при оптимальном checkpoint_timeout:
- Доля времени, затрачиваемого на ожидания ввода-вывода IO (особенно DataFileWrite, WALWrite), снижается по отношению к общему времени выполнения.
2. Системные метрики (vmstat, iostat):
- vmstat: Снижение числа процессов в состоянии блокировки b (ожидающих I/O) и стабильная/низкая длина очереди процессов r.
- iostat для диска с WAL и данными:
- %util: Должен оставаться ниже 80-85% при оптимальной настройке. Выше — явный признак перегруженности I/O.
- await: Среднее время обслуживания запроса к диску должно быть стабильно низким (например, < 10-20 мс для SSD). Резкие пики в момент checkpoint допустимы, но не постоянные высокие значения.
3. Ключевой компромисс — max_wal_size:
- Важно: Увеличение checkpoint_timeout требует пропорционального увеличения max_wal_size. Если этот параметр установлен недостаточно большим, контрольные точки будут срабатывать не по времени, а по объёму WAL, сводя настройку на нет.
ℹ️Эта гипотеза даёт чёткую основу для вашего эксперимента с pg_expecto и DeepSeek, что позволит не только подтвердить или опровергнуть общее влияние, но и вычислить точные пороговые значения для вашей конкретной конфигурации.
Детальный план экспериментального исследования: влияние checkpoint_timeout на производительность PostgreSQL
1. Цель и гипотеза
- Цель: Определить оптимальное значение параметра checkpoint_timeout для конфигурации 8 CPU / 8 GB RAM под смешанной OLTP-нагрузкой (SELECT/INSERT/UPDATE/DELETE) с варьируемой интенсивностью (5-22 конкурентных соединения на тип запроса), обеспечивающее максимальную операционную скорость и минимальные ожидания СУБД.
- ❓Основная гипотеза: Существует нелинейная зависимость между checkpoint_timeout и производительностью. При увеличении значения от минимального (5 мин) производительность будет расти, достигнет «плато» (оптимальный диапазон), после чего либо стабилизируется, либо начнёт снижаться из-за чрезмерно долгих и интенсивных операций записи во время контрольной точки. ❓Гипотеза для проверки: оптимальный диапазон лежит между 10 и 45 минутами.❓
2. Контролируемые и зависимые переменные
Независимые (Контролируемые)
👉checkpoint_timeout: Серия значений: 1m,5m, 10m, 15m, 20m, 30m.
Зависимые (Измеряемые)
Операционная скорость СУБД
Ожидания в СУБД (wait_event): IO (DataFileWrite, WALWrite, BufferIO), Lock (transactionid, tuple)
Системные метрики (vmstat/iostat): vmstat: утилизация CPU (us,sy,id), очереди (r,b). iostat: утилизация диска (%util), время отклика (await), пропускная способность (MB/s).
Константы
Аппаратные ресурсы: CPU = 8 vCPU, RAM = 8 GB. shared_buffers = 2 GB, work_mem = 32 MB, maintenance_work_mem = 512 MB.
СУБД и данные: PostgreSQL 17, Демобаза 2.0. max_wal_size = 32GB (фиксировано, с большим запасом). checkpoint_completion_target = 0.9.
3. Последовательность экспериментов
Эксперимент разбит на три этапа для минимизации «шума» и установления причинно-следственных связей.
Этап 1: Предварительная настройка и калибровка (1 час)
- Предварительный 60-минутный тест при минимальной нагрузке (5 соединений) без сбора подробных метрик. Цель: «прогреть» буферный кэш, убедиться в стабильности работы и оценить базовый уровень генерации WAL, чтобы удостовериться, что max_wal_size достаточен.
Этап 2: Основной эксперимент – матрица тестов (7 прогонов)
- Структура: Для каждого из 7 значений checkpoint_timeout тест с экспоненциальным ростом нагрузки с 5 до 22 соединений.
- Процедура одного прогона:
- Целевое значение checkpoint_timeout. Выполнить CHECKPOINT;(before_start.sql).
- Нагрузочный тест .
Этап 3: Контрольный эксперимент – поиск «точки слома»
- После анализа данных основного этапа выбор 1-2 наиболее перспективных значения checkpoint_timeout (например, 30м и 45м).
- Стресс-тест на выносливость длительностью 4 часа с максимальной нагрузкой (22 соединения).
- Цель: Обнаружить долгосрочные эффекты — деградацию производительности из-за накопления «грязных» страниц, аномальный рост WAL или исчерпание max_wal_size.
4. Методология сбора и анализа данных
- Единая точка агрегации: Все метрики (pg_expecto, iostat, итоги pgbench) должны иметь временную метку. Это позволит с помощью DeepSeek анализировать временные ряды и находить корреляции (напр., рост await диска -> всплеск DataFileWrite -> падение TPS).
- Ключевые запросы для анализа:
- Соотношение «цена/качество»: SPEED vs checkpoint_timeout. Построить график для каждого уровня нагрузки.
- Влияние на IO: Корреляция между checkpoint_timeout и %util диска, а также долей времени IO в wait_event.
- Определение «плато»: Найти точку, где прирост SPEED от увеличения интервала становится меньше 2-5%.
- Роль DeepSeek: Использовать ИИ для:
- Выявления скрытых паттернов во временных рядах.
- Кластеризации прогонов по профилю ожиданий.
- ❓Построения многомерной регрессионной модели, предсказывающей SPEED на основе checkpoint_timeout, нагрузки и метрик vmstat.
5. Критерии успеха и интерпретация результатов
- Оптимум найден, если:
- Для 2-3 уровней нагрузки кривые производительности имеют явный максимум в близком диапазоне значений checkpoint_timeout.
- В этом диапазоне профиль wait_event показывает минимальную долю IO и Lock ожиданий.
- Системные метрики (%util, await) стабильны, без пиков, превышающих пороги (напр., await > 50мс).
- Гипотеза опровергнута, если:
- Производительность монотонно растет или падает во всем диапазоне значений.
- Узким местом являются не IO, а CPU (vmstat показывает us+sy > 90%) или Lock-конфликты.
- Что делать, если max_wal_size исчерпывается: Зафиксировать этот факт как важный результат. Он указывает, что для данного workload и интервала требуется не только увеличить checkpoint_timeout, но и пропорционально увеличить max_wal_size, либо причина в слишком высокой интенсивности записи.
Этот план обеспечивает системный подход, результаты которого будут статистически значимыми и пригодными как для верификации гипотезы, так и для публикации.
⚙️ Технические возможности DeepSeek для анализа данных
- Эффективная обработка больших контекстов: Модель DeepSeek V3.2 использует механизм DeepSeek Sparse Attention (DSA), который позволяет ей выборочно обрабатывать информацию в длинных текстах, а не анализировать каждый токен целиком. Это значительно снижает вычислительные затраты и позволяет эффективно работать с большими объёмами структурированных данных (логами, метриками).
- Большое окно контекста: Модель поддерживает контекстное окно размером до 128 тысяч токенов. Это позволяет загружать в один запрос результаты множества тестов для комплексного анализа.
- Режим рассуждений (Reasoning Mode): DeepSeek имеет специальный режим (deepseek-reasoner), в котором модель показывает цепочку своих рассуждений перед тем, как дать окончательный ответ. Для вашей задачи это критически важно, так как позволяет не просто получить вывод, но и понять логику анализа.
📊 Практическое применение для эксперимента
Для успешной работы данные перед загрузкой в нейросеть должны быть структурированы и агрегированы.
Как подготовить данные
Вместо сырых логов (которые слишком объемны) подготовьте для DeepSeek сводные таблицы по каждому тесту. Пример структуры агрегированных данных:
- Параметры теста: checkpoint_timeout, кол-во соединений
- Метрики производительности: SPEED (средний), WAITINGS , wait_event_type
- Профиль ожиданий СУБД: % времени в IO (DataFileWrite), % времени в Lock, % времени в CPU
- Системные метрики: %iowait , await диска (мс), %util диска
ℹ️Пример запроса к DeepSeek
С правильно подготовленными данными ваш запрос может выглядеть так:
«Проанализируй сводные результаты нагрузочного тестирования PostgreSQL. Основной изменяемый параметр — checkpoint_timeout. Определи, при каком значении достигается оптимальный баланс между высокой операционной скоростью и низкими ожиданиями СУБД. Обрати особое внимание на корреляцию между checkpoint_timeout, временем, проведённым процессами в ожидании IO (wait_event), и метриками нагрузки на диск из iostat. Сформулируй выводы и практические рекомендации по настройке.»
🚀 Рекомендации по использованию
Чтобы получить лучший результат:
- Суммируйте и сопоставьте результаты тестов (например, в единой CSV-таблице).
- Чётко сформулируйте задачу для ИИ: укажите, что нужно сравнить, найти и на что обратить внимание.
- Используйте режим глубоких рассуждений (deepseek-reasoner) для получения наиболее детализированного анализа.
[ Если у вас есть примеры агрегированных данных, я могу помочь составить для них оптимальный промпт (текст запроса) для DeepSeek.]
Методология исследования
Тестовая среда, инструменты и конфигурация СУБД:
- СУБД: PostgreSQL 17
- Условия тестирования: параллельная нагрузка от 7 до 22 сессий по каждому тестовому сценарию.