
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
☑️Пролог: Подготовка эксперимента.
☑️checkpoint_timeout = '15m'. Часть-1 : СУБД
☑️checkpoint_timeout = '15m'. Часть-2 : Инфраструктура
☑️checkpoint_timeout = '5m'. Часть-1 : СУБД.
☑️checkpoint_timeout = '5m'. Часть-2 : Инфраструктура.
☑️checkpoint_timeout 15m vs 5m. Часть-2 : инфраструктура
☑️Предисловие
Изначальная гипотеза предполагала существование «золотой середины» для параметра checkpoint_timeout, где производительность PostgreSQL достигает максимума. Ожидалось, что увеличение интервала с 5 до 15 минут даст значительный прирост производительности СУБД. Однако эксперименты дали неожиданный и однозначный результат, перевернувший представления о балансе между пиковой и стабильной производительностью в OLTP-среде.
☑️Эксперимент-1 : Базовое значение 15минут
ALTER SYSTEM SET checkpoint_timeout = '15m' ;
SELECT pg_reload_conf();
☑️Эксперимент-2 : Снижение до 5минут
ALTER SYSTEM SET checkpoint_timeout = '5m' ;
SELECT pg_reload_conf();
☑️1. Сравнительный анализ производительности PostgreSQL при разных checkpoint_timeout
☑️1.1. Операционная скорость СУБД
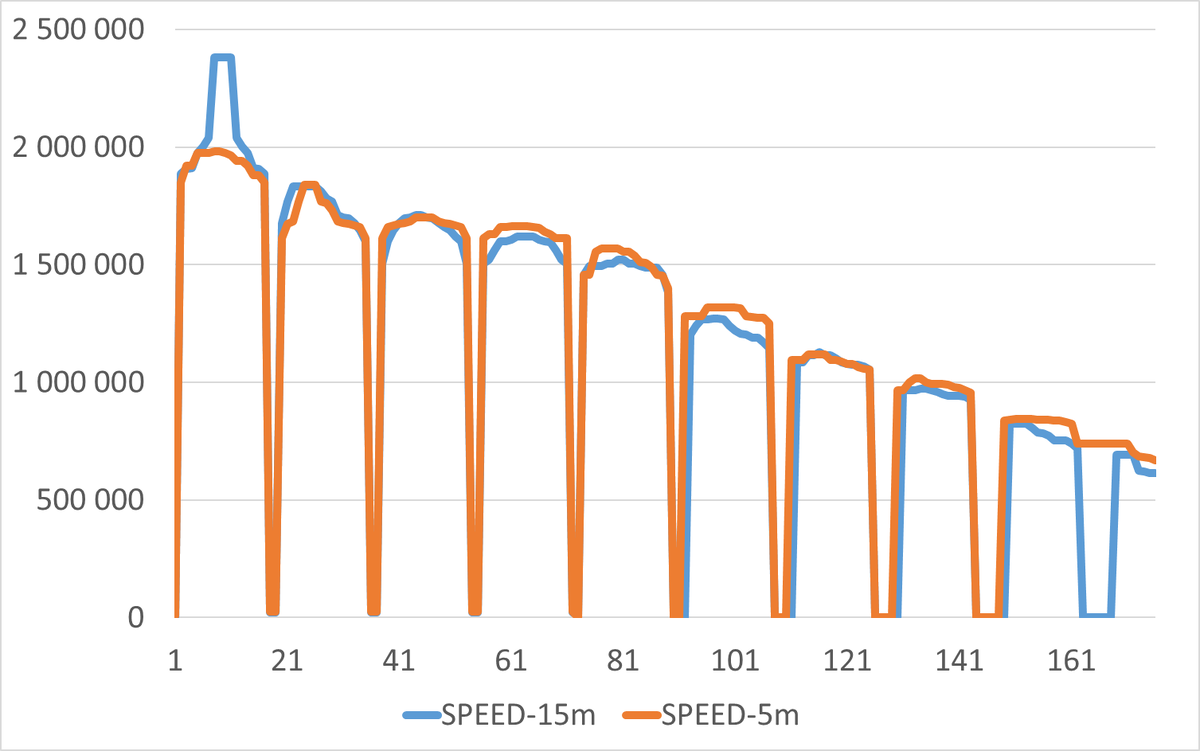
ℹ️Важная деталь по графикамℹ️
Периодические провалы операционной скорости это не влияние checkpoint , это длительное выполнение конкурентных update в сценарии-6, в то время как остальные сценарии завершили работу.
Эксперимент-1 (15 минут):
· Максимальная SPEED: 2 379 393.00
· Минимальная SPEED: 140.00 (крайне низкое значение)
· Средняя скорость (приблизительно): ~1 200 000-1 500 000
Эксперимент-2 (5 минут):
· Максимальная SPEED: 1 980 527.00 (на 16.8% ниже)
· Минимальная SPEED: 642.00 (выше в 4.6 раза)
· Средняя скорость (приблизительно): ~1 000 000-1 300 000
Вывод: Эксперимент с 15-минутным checkpoint_timeout показывает более высокую пиковую производительность, но имеет крайне низкие провалы (сценарий-6).
☑️1.2. Ожидания СУБД
Эксперимент-1 (15 минут):
· Максимальные ожидания: 10 128.00
· Минимальные ожидания: 3 654.00
· Диапазон колебаний: 6 474.00
Эксперимент-2 (5 минут):
· Максимальные ожидания: 9 087.00 (на 10.3% ниже)
· Минимальные ожидания: 2 189.00 (на 40.1% ниже)
· Диапазон колебаний: 6 898.00 (больше изменчивость)
Вывод: 5-минутный checkpoint показывает меньшие значения ожиданий, особенно в нижней границе.
☑️1.3. Ожидания СУБД типа IO
☑️1.4. Динамика изменения во времени
Эксперимент-1 (15 минут):
· ОПЕРАЦИОННАЯ СКОРОСТЬ: Имеет более выраженные пики и провалы
· ОЖИДАНИЯ: Плавный рост с 4,000 до 10,000+ к концу теста
· Наблюдается явная деградация производительности со временем
Эксперимент-2 (5 минут):
· ОПЕРАЦИОННАЯ СКОРОСТЬ: Более стабильна, без экстремальных провалов
· ОЖИДАНИЯ: Более резкие колебания, но в целом ниже
☑️1.5. Линии регрессии и R²
ОПЕРАЦИОННАЯ СКОРОСТЬ:
· 15m: R² = 0.47, наклон = -34.51 (умеренная детерминация, снижение скорости)
· 5m: R² = 0.36, наклон = -31.06 (слабая детерминация, менее крутое снижение)
ОЖИДАНИЯ:
· 15m: R² = 0.84, наклон = +42.43 (сильная детерминация, значительный рост)
· 5m: R² = 0.72, наклон = +40.31 (хорошая детерминация, рост ожиданий)
Корреляция ОПЕРАЦИОННАЯ СКОРОСТЬ-ОЖИДАНИЯ:
· 15m: -0.63 (сильная отрицательная корреляция)
· 5m: -0.50 (умеренная отрицательная корреляция)
1.6. Выводы
1. Для пиковой производительности: checkpoint_timeout = '15m'
o Выше максимальная скорость операций (2.38M vs 1.98M)
o Но сопровождается экстремальными провалами (до 140 единиц)
2. Для стабильности и предсказуемости: checkpoint_timeout = '5m'
o Более предсказуемая производительность (R² = 0.72 vs 0.84 для ожиданий)
o Значительно выше минимальная скорость (642 vs 140)
o Меньше общее количество ожиданий
o Более стабильная работа без экстремальных провалов
3. Компромиссный вариант: checkpoint_timeout = '5m'
o Хотя пиковая производительность ниже на 16.8%, стабильность выше
o Меньше диапазон колебаний ожиданий
o Более плавная деградация производительности во времени
☑️1.7. Объяснение наблюдаемых различий:
При checkpoint_timeout = '15m':
· Более редкие контрольные точки → меньше накладных расходов на запись WAL
· Выше пиковая производительность за счёт буферизации операций
· Но накапливается больше изменений → более долгие и интенсивные checkpoint
· Приводит к резким провалам производительности во время checkpoint
При checkpoint_timeout = '5m':
· Более частые контрольные точки → равномернее распределена нагрузка на диск
· Меньше накопленных изменений за один checkpoint → более короткие и предсказуемые пики нагрузки
· Выше минимальная производительность за счёт отсутствия экстремальных провалов
· Более стабильная и предсказуемая работа системы
☑️1.8. Рекомендация:
Для большинства продуктивных-сценариев checkpoint_timeout = '5m' предпочтительнее, так как обеспечивает более стабильную и предсказуемую производительность без экстремальных провалов, что критически важно для отзывчивости системы.
2. Сравнительный анализ типов ожиданий PostgreSQL
2.1. Распределение типов ожиданий
Эксперимент-1 (15 минут):
· LOCK (блокировки): 1 308 - 8 390 (доминирующий тип)
· TIMEOUT (таймауты): 654 - 3 440 (второй по значимости)
· IO (ввод/вывод): 58 - 126 (относительно низкие значения)
· LWLOCK (легковесные блокировки): 54 - 338 (наименьшие значения)
Эксперимент-2 (5 минут):
· LOCK (блокировки): 1 331 - 8 404 (по-прежнему доминирует)
· TIMEOUT (таймауты): 77 - 4 229 (возросли максимальные значения)
· IO (ввод/вывод): 53 - 75 (снизились максимальные значения)
· LWLOCK (легковесные блокировки): 69 - 262 (уже диапазон)
2.2. Коэффициенты корреляции с WAITINGS
Эксперимент-1 (15 минут):
· WAITINGS - LOCK: 0.96 (очень сильная положительная корреляция)
· WAITINGS - LWLOCK: 0.86 (сильная положительная корреляция)
· WAITINGS - IO: -0.56 (умеренная отрицательная корреляция)
· WAITINGS - TIMEOUT: -0.41 (слабая отрицательная корреляция)
Эксперимент-2 (5 минут):
· WAITINGS - LOCK: 0.84 (сильная положительная корреляция)
· WAITINGS - LWLOCK: 0.78 (умеренная положительная корреляция)
· WAITINGS - IO: -0.36 (слабая отрицательная корреляция)
· WAITINGS - TIMEOUT: -0.21 (очень слабая отрицательная корреляция)
2.3. Изменение паттернов ожиданий при уменьшении checkpoint_timeout
Ключевые изменения при переходе от 15m к 5m:
1. Уменьшение корреляции LOCK с общими ожиданиями (0.96 → 0.84):
o Блокировки стали менее доминирующим фактором в общих ожиданиях
o Система стала менее зависима от конфликтов блокировок
2. Снижение корреляции LWLOCK с общими ожиданиями (0.86 → 0.78):
o Легковесные блокировки также уменьшили свое влияние
o Меньше конфликтов за внутренние структуры данных СУБД
3. Ослабление отрицательной корреляции IO с общими ожиданиями (-0.56 → -0.36):
o Ввод/вывод стал меньше влиять на общие ожидания (в отрицательную сторону)
o Возможно, более частые checkpoint уменьшили пиковую нагрузку на диск
4. Увеличение максимальных значений TIMEOUT при снижении корреляции:
o Максимальные таймауты выросли с 3,440 до 4,229 единиц
o Но корреляция с общими ожиданиями ослабла (-0.41 → -0.21)
o Таймауты стали более независимым фактором
5. Существенное снижение диапазона IO ожиданий (126→75):
o Ввод/вывод стал более предсказуемым
o Меньше экстремальных значений IO ожиданий
2.4. Наиболее сильно коррелирующие типы ожиданий
В Эксперименте-1 (15 минут):
1. LOCK - 0.96 (очень сильная положительная корреляция)
o Основной драйвер общих ожиданий
o Увеличение блокировок почти линейно связано с ростом общих ожиданий
2. LWLOCK - 0.86 (сильная положительная корреляция)
o Второй по значимости фактор
o Внутренние легковесные блокировки существенно влияют на производительность
В Эксперименте-2 (5 минут):
1. LOCK - 0.84 (сильная положительная корреляция)
o По-прежнему основной фактор, но влияние уменьшилось
o Блокировки остаются ключевой проблемой, но менее критичной
2. LWLOCK - 0.78 (умеренная положительная корреляция)
o Значимость легковесных блокировок снизилась
o Система стала более устойчива к внутренним конфликтам
☑️2.5. Выводы об изменении паттернов
Эффект уменьшения checkpoint_timeout:
1. Снижение доминирования блокировок:
o При 15m: LOCK объясняет 92% дисперсии общих ожиданий (R² ≈ 0.96²)
o При 5m: LOCK объясняет 71% дисперсии общих ожиданий (R² ≈ 0.84²)
o Блокировки стали менее определяющим фактором производительности
2. Улучшение баланса между типами ожиданий:
o Распределение влияния стало более равномерным
o Ни один тип ожиданий не доминирует чрезмерно
3. Более предсказуемый ввод/вывод:
o Уже диапазон значений IO ожиданий
o Меньше экстремальных пиков дисковой активности
4. Парадокс таймаутов:
o Максимальные значения выросли, но корреляция снизилась
o Таймауты стали более редкими, но более выраженными, когда возникают
☑️2.6. Механизм изменений:
При checkpoint_timeout = 15m:
· Редкие, но интенсивные checkpoint
· Длительные периоды накопления изменений в памяти
· Высокие пики нагрузки на диск → больше конфликтов блокировок
· Сильная корреляция LOCK/LWLOCK с общими ожиданиями
При checkpoint_timeout = 5m:
· Более частые, но менее интенсивные checkpoint
· Меньше накопленных изменений за один checkpoint
· Более равномерная нагрузка на диск → меньше конфликтов блокировок
· Ослабление корреляции LOCK/LWLOCK с общими ожиданиями
☑️2.7. Резюме:
Уменьшение checkpoint_timeout с 15 до 5 минут привело к более сбалансированной системе, где ни один тип ожиданий не доминирует чрезмерно, что повышает предсказуемость и управляемость системы.
3. Анализ событий ожидания (wait_event)
3.1. Топовые wait_event по типу Lock
Эксперимент-1 (15 минут):
· transactionid: 348 787 событий (89.77% от всех событий Lock)
Эксперимент-2 (5 минут):
· transactionid: 356 740 событий (90.11% от всех событий Lock)
Изменения:
· Абсолютное количество: +7 953 события (+2.28%)
· Процентная доля: +0.34 процентных пункта
3.2. Топовые wait_event по типу LWLock
Эксперимент-1 (15 минут):
· LockManager: 10 290 событий (63.72% от всех LWLock)
· BufferMapping: 3 631 событий (22.48% от всех LWLock)
· Суммарно: 13 921 событий (86.20% от всех LWLock)
Эксперимент-2 (5 минут):
· LockManager: 9 823 события (74.99% от всех LWLock)
· BufferMapping: 1 803 события (13.76% от всех LWLock)
· Суммарно: 11 626 событий (88.75% от всех LWLock)
Изменения:
· LockManager:
o Абсолютное: -467 событий (-4.54%)
o Процент: +11.27 процентных пункта
· BufferMapping:
o Абсолютное: -1,828 событий (-50.34%)
o Процент: -8.72 процентных пункта
☑️3.3. Изменение распределения событий ожидания при уменьшении checkpoint_timeout
Общие тенденции:
1. Концентрация в пределах ключевых событий:
o В обоих экспериментах 2-3 события составляют 80+% ожиданий
o При 5m концентрация даже немного усилилась (88.75% vs 86.20% для LWLock)
2. Изменение баланса между событиями:
o LockManager усилил свою доминирующую позицию (с 63.72% до 74.99%)
o BufferMapping значительно снизил свою значимость (с 22.48% до 13.76%)
3. Стабильность transactionid ожиданий:
o Остался основным источником блокировок (~90%)
o Абсолютное количество даже немного увеличилось
3.4. Какие события ожидания стали более/менее значимыми?
Более значимые события (увеличили свою долю):
1. LockManager (LWLock): +11.27 процентных пункта
o Стал еще более доминирующим среди легковесных блокировок
o Несмотря на небольшое снижение абсолютного количества, его относительная значимость выросла
o Указывает на увеличение конфликтов управления блокировками
2. transactionid (Lock): +0.34 процентных пункта
o Усилил свою и так доминирующую позицию
o Остается основной проблемой блокировок
Менее значимые события (снизили свою долю):
1. BufferMapping (LWLock): -8.72 процентных пункта
o Наиболее значительное снижение доли
o Абсолютное количество уменьшилось в 2 раза
o Указывает на уменьшение конфликтов отображения буферов
Нейтральные/стабильные события:
· Не представлены другие события в топе, что говорит о высокой концентрации проблем
☑️3.5. Интерпретация результатов
Почему BufferMapping уменьшился:
BufferMapping отвечает за конфликты при доступе к хэш-таблице отображения буферов. При уменьшении checkpoint_timeout:
· Более частые checkpoint → меньше накопленных грязных страниц за один раз
· Более равномерная запись буферов на диск
· Меньше одновременных попыток модификации отображения буферов
· Результат: Снижение конфликтов BufferMapping на 50%
Почему LockManager стал более значимым:
LockManager управляет обычными блокировками (не путать с transactionid). Увеличение его доли может указывать на:
· Более частые операции управления блокировками из-за увеличенной активности системы
· Возможно, более эффективное использование буферного кэша приводит к увеличению конкурентного доступа
· Несмотря на снижение абсолютного количества, LockManager стал еще более доминирующим среди LWLock
Почему transactionid остался стабильно высоким:
transactionid блокировки связаны с конкурентным доступом к данным:
· Не зависит напрямую от настройки checkpoint_timeout
· Определяется в основном схемой приложения и паттернами доступа к данным
· Остается основной проблемой производительности в обоих экспериментах
☑️3.6. Выводы о влиянии checkpoint_timeout
Положительные эффекты уменьшения checkpoint_timeout:
1. Значительное снижение конфликтов BufferMapping (-50%)
2. Более равномерное распределение нагрузки на подсистему блокировок
3. Уменьшение абсолютного количества LWLock ожиданий
3.7. Неожиданные эффекты:
1. Усиление доминирования LockManager среди LWLock
2. Незначительный рост transactionid блокировок (возможно статистическая погрешность)
3.8. Рекомендации:
1. Для снижения BufferMapping: Уменьшение checkpoint_timeout эффективно
2. Для решения проблемы LockManager: Требуется дополнительная оптимизация (настройка max_locks_per_transaction, мониторинг блокировок)
3. Для transactionid блокировок: Требуется оптимизация приложения (сокращение времени транзакций, использование оптимистичных блокировок)
☑️3.9. Общий вывод:
Уменьшение checkpoint_timeout с 15 до 5 минут привело к перераспределению проблем с буферным отображением на управление блокировками, что может указывать на более эффективное использование буферного кэша, но требует дополнительной настройки системы управления блокировками.
4. Сводный анализ и рекомендации
4.1. Общее сравнение производительности
Средняя скорость операций:
· Эксперимент-1 (15m): Выше пиковая производительность (2.38M vs 1.98M)
· Эксперимент-2 (5m): Выше минимальная производительность (642 vs 140) и лучше стабильность
· Вердикт: Для среднесрочной стабильности предпочтительнее 5m, для краткосрочных пиков - 15m
Общие ожидания:
· Эксперимент-2 (5m): Имеет меньше общих ожиданий (максимум 9,087 vs 10,128)
· Более низкие минимальные значения ожиданий (2,189 vs 3,654)
· Вердикт: 5m checkpoint демонстрирует меньше общих ожиданий
4.2. Влияние checkpoint_timeout на паттерны ожиданий
Паттерны блокировок (LOCK, LWLOCK):
· LOCK: Остается доминирующим в обоих случаях (~90% через transactionid)
· LWLOCK: Существенное перераспределение:
o BufferMapping уменьшился на 50% (с 3,631 до 1,803 событий)
o LockManager усилил доминирование (с 63.72% до 74.99%)
· Корреляция с общими ожиданиями:
o LOCK: Снизилась с 0.96 до 0.84 (меньше определяющего влияния)
o LWLOCK: Снизилась с 0.86 до 0.78 (более сбалансированная система)
Ввод/вывод (IO):
· Диапазон IO ожиданий сузился (126→75) - более предсказуемая дисковая нагрузка
· Корреляция с общими ожиданиями ослабла (-0.56 → -0.36)
· Более частые checkpoint снизили пиковую нагрузку на диск
Таймауты (TIMEOUT):
· Максимальные значения выросли (3,440 → 4,229)
· Но корреляция с общими ожиданиями снизилась (-0.41 → -0.21)
· Таймауты стали более редкими, но более выраженными
4.3. Наиболее чувствительные к настройке checkpoint_timeout компоненты
SQL-запросы:
· scenario6 (queryID -4261790647437368643): Крайне чувствителен
o 15m: 100% Lock + 79.05% LWLock
o 5m: 100% Lock + 86.11% LWLock
o Увеличилась доля в LWLock ожиданиях
· scenario5 (queryID -9191196513623730485): Появился только при 15m (14.03% LWLock)
· Вывод: scenario6 требует особого внимания при любых настройках
Типы ожиданий:
· Наиболее чувствительные: BufferMapping (LWLock) - снижение на 50%
· Умеренно чувствительные: LockManager - изменение доли с 63.72% до 74.99%
· Наименее чувствительные: transactionid (Lock) - стабильно ~90%
События ожидания:
· BufferMapping: Резкое снижение при более частых checkpoint
· LockManager: Усиление доминирования при оптимизации дисковой подсистемы
· transactionid: Не зависит от checkpoint_timeout, определяется логикой приложения
☑️4.4. Практические рекомендации
Оптимальный checkpoint_timeout для данной нагрузки:
· Рекомендация: 5 минут
· Обоснование:
o Более стабильная производительность без экстремальных провалов
o Меньше общих ожиданий
o Более предсказуемая дисковая нагрузка
o Улучшение баланса между типами ожиданий
☑️4.5. Механизмы, лежащие в основе наблюдаемых различий
Основной механизм: Баланс между памятью и диском
1. При checkpoint_timeout = 15m:
o Накопление большого объема изменений в памяти (грязные страницы)
o Редкие, но интенсивные всплески записи на диск
o Высокий пиковый IO → больше конфликтов буферов (BufferMapping)
o Длительные периоды без checkpoint → выше пиковая производительность
o Но глубокие провалы во время checkpoint
2. При checkpoint_timeout = 5m:
o Более частый сброс изменений на диск
o Меньший объем данных за один checkpoint
o Более равномерная нагрузка на диск
o Меньше конфликтов за буферы (BufferMapping ↓50%)
o Но больше операций управления блокировками (LockManager ↑)
o Более стабильная, предсказуемая производительность
Второстепенные механизмы:
1. Эффект WAL (Write-Ahead Logging):
o При частых checkpoint меньше накопленный WAL
o Быстрее восстановление после сбоя
o Меньше риска переполнения WAL
2. Эффект буферного кэша:
o Более частые checkpoint освобождают буферы быстрее
o Улучшение turnover буферного кэша
o Возможное увеличение cache hit ratio
3. Эффект конкурентности:
o Меньше длительных эксклюзивных операций записи
o Улучшение параллелизма read/write операций
o Но увеличение общего количества операций управления блокировками
4.6. Заключительный вывод
Для продуктивной среды с требованием стабильности рекомендуется checkpoint_timeout = '5m' с дополнительной настройкой:
· checkpoint_completion_target = 0.9 для плавности
· Мониторинг и оптимизация запроса scenario6
· Настройка shared_buffers и effective_cache_size под конкретное железо
Для пакетной обработки с приоритетом пиковой производительности можно рассмотреть checkpoint_timeout = '15m', но с:
· Мониторингом провалов производительности
· Резервированием ресурсов под checkpoint
· Оптимизацией как scenario6, так и scenario5
4.7. Ключевое открытие:
Параметр checkpoint_timeout влияет не только на дисковую подсистему, но и на паттерны блокировок, что требует комплексного подхода к оптимизации.