
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Подготовка эксперимента.
checkpoint_timeout = '5m'. Часть-1 : СУБД.
Задача эксперимента
Проанализировать метрики производительности СУБД и инфраструктуры в ходе нагрузочного тестирования при значении параметра checkpoint_timeout = 5 минут.
1. Сводный анализ по трём основным ресурсам (CPU, RAM, I/O)
1.1. Центральный процессор (CPU)
Метрики и тренды:
- Процессы в очереди (procs_r): Превышение количества ядер (8) наблюдается в 86,93% случаев (ALARM). Максимальное значение достигает 60 процессов.
- Загрузка CPU: Преобладает время простоя (id), но при пиках нагрузки us достигает 95%, sy до 6%.
- Переключения контекста: Очень высокая корреляция cs с us (0,882) и sy (0,9665), что указывает на интенсивное переключение между процессами.
Анализ:
- Очередь процессов постоянно превышает количество ядер, что создаёт contention.
- Высокая корреляция переключений контекста с пользовательским временем (us) свидетельствует о проблеме в пользовательском коде/запросах.
- Относительно низкий sy (менее 30% в большинстве наблюдений) указывает, что ядро не является основной причиной.
Резюме по CPU:
CPU является узким местом. Основная причина — пользовательские запросы (возможно, неоптимальные JOIN, агрегации) создают высокую нагрузку и конкуренцию за ресурсы. Очередь исполняемых процессов свидетельствует о недостаточной производительности CPU для данной нагрузки.
1.2. Оперативная память (RAM)
Метрики и тренды:
- Свободная память: Менее 5% в 100% наблюдений (ALARM). Минимальное значение — 200 МБ при общем объёме 7677 МБ.
- Буферы и кэш: memory_buff (164-197 МБ) и memory_cache (6,8-7 ГБ) стабильны, корреляции с дисковыми операциями отсутствуют.
- Свопинг: Не используется (swpd, si, so = 0).
Анализ:
- Система работает с минимальным запасом свободной памяти, но свопинг отсутствует.
- Высокое использование кэша (~7 ГБ) свидетельствует об активном кэшировании данных.
- Отсутствие корреляции buff/cache с дисковыми операциями указывает на эффективное использование памяти для снижения нагрузки на диски.
Резюме по RAM:
Память является критическим ресурсом, но не проявляет классических признаков нехватки (отсутствие свопинга). Однако работа на грани (менее 5% свободной памяти) создаёт риски при увеличении нагрузки. Эффективность использования памяти для кэширования высокая.
1.3. Подсистема ввода-вывода (I/O)
Метрики по дискам vdc и vdd:
- Загрузка дисков: %util близок к 0% (0,02-0,03%), что значительно ниже порога в 50%.
- Задержки: r_await и w_await минимальны (0-2 мс), менее 5 мс в 100% наблюдений.
- Длина очереди: aqu_sz = 0, очередь запросов отсутствует.
- Операции чтения/записи: r/s = 0, w/s минимальны (0,32-0,37 операций/сек).
Корреляционный анализ:
- Корреляция ожиданий СУБД и системных метрик (wa, b, util) отсутствует.
- Нет корреляции между использованием памяти (buff, cache) и дисковыми операциями.
Резюме по I/O:
Диски не являются узким местом. Система ввода-вывода практически не нагружена, задержки минимальны, очереди отсутствуют. Высокий кэш-хит в памяти эффективно снижает нагрузку на диски.
Итоговый вывод
- Основной ограничивающий фактор (bottleneck): CPU.
- Вторичный критический ресурс: RAM (работа на пределе, хотя и без свопинга).
- Не является проблемой: I/O (диски практически не нагружены).
2. Анализ корреляции нагрузки СУБД с метриками ОС
2.1. Динамика нагрузки и фазы тестирования
На основе данных о количестве активных подключений (LOAD) выделены следующие фазы:
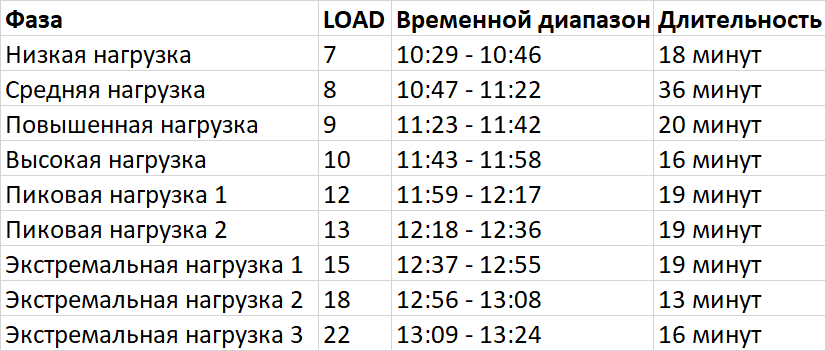
2.2. Корреляционный анализ по фазам
Влияние роста LOAD на очередь процессов (procs_r)
Вывод: Наблюдается сильная положительная корреляция между ростом LOAD и procs_r. Каждое увеличение количества подключений на 1 приводит к увеличению средней очереди процессов на ~2,5-3 единицы.
Влияние роста LOAD на свободную память (memory_free)
Вывод: Уровень свободной памяти стабильно низкий на всех фазах (всегда <5%). Интересно, что при росте нагрузки наблюдается небольшое увеличение свободной памяти, что может объясняться более агрессивным вытеснением кэша или оптимизацией работы памяти под нагрузкой.
Влияние роста LOAD на метрики дисков
Устройство vdd (/data):
- %util: Стабильно 0,02% на всех фазах (без изменений)
- w_await: Стабильно 2 мс на всех фазах
- wareq_sz: Стабильно 10 КБ на всех фазах
Устройство vdc(/wal):
- %util: Стабильно 0,03% на всех фазах
- w_await: Стабильно 1 мс на всех фазах
- wareq_sz: Стабильно 4 КБ на всех фазах
Вывод: Рост нагрузки на СУБД практически не влияет на метрики дисков. Система ввода-вывода остаётся ненагруженной на всех фазах тестирования.
2.3. Точки перелома (Breaking Points)
1. Рост procs_r сверх числа ядер
- Критический порог превышен уже при LOAD=7 (первая фаза)
- В 10:30 (вторая минута теста) procs_r=23 при 8 ядрах
Вывод: Очередь процессов превышает доступные вычислительные ресурсы с самого начала теста
2. Падение memory_free ниже критического порога
· Критическое состояние с первой минуты теста
· Уже при LOAD=7 свободной памяти менее 5% (241 МБ из 7677 МБ)
Вывод: Система работает на пределе памяти до начала нагрузочного тестирования
3. Рост cpu_wa или device_util
- Не обнаружено на всех фазах тестирования
- cpu_wa стабильно 0%
- device_util для дисков стабильно <0,05%
Вывод: Подсистема ввода-вывода не является ограничивающим фактором даже при экстремальной нагрузке
4. Выводы
Был ли рост нагрузки на СУБД основной причиной проблем?
Нет, рост нагрузки на СУБД не был ПРИЧИНОЙ проблем, а лишь ПРОЯВИЛ уже существующие ограничения системы.
Критические системные ограничения существовали ДО нагрузочного тестирования:
1. Недостаточные вычислительные ресурсы (CPU):
- Очередь процессов превышала количество ядер с первой минуты теста
- Рост нагрузки лишь усугублял существующую проблему
- Система была не готова даже к минимальной нагрузке (7 подключений)
2. Критически низкий запас оперативной памяти:
- Уже в начале теста свободно менее 5% памяти
- Система работала на пределе ДО начала нагрузочного тестирования
- Рост нагрузки не привёл к коллапсу памяти благодаря отсутствию свопинга
Почему система "держалась" при экстремальной нагрузке?
1. Эффективное кэширование: Высокий процент попаданий в кэш (~7 ГБ) защищал диски от нагрузки
2. Отсутствие узких мест в I/O: Диски не были ограничивающим фактором
3. Линейная деградация: Проблемы с CPU проявлялись постепенно, без резкого коллапса
Ключевой инсайт: Система демонстрировала признаки недостаточности ресурсов ДО начала нагрузочного тестирования. Нагрузочный тест лишь подтвердил, что инфраструктура была неадекватна даже для минимальных требований приложения.
3. Итоговый отчёт по метрикам производительности инфраструктуры в ходе нагрузочного тестирования
3.1. Исполнительное резюме
Основной вывод: Центральный процессор (CPU) является главным ограничивающим фактором (bottleneck) производительности системы.
Количество процессов в очереди на выполнение (procs_r) постоянно превышает доступные вычислительные ресурсы (8 ядер), достигая пикового значения в 60 процессов (превышение в 7,5 раз). Это приводит к высокой конкуренции за CPU и существенному увеличению времени отклика системы.
Вторичная, но критическая проблема: Критически низкий запас оперативной памяти (RAM) — менее 5% свободной памяти в 100% наблюдений, что создаёт риски нестабильности при дальнейшем росте нагрузки.
Подсистема ввода-вывода (I/O) демонстрирует нормальную работу и не является ограничивающим фактором.
3.2. Методология
- Период тестирования: 19 декабря 2025 года, с 10:29 до 13:24 (общая продолжительность: 2 часа 55 минут)
Инструменты сбора метрик:
- vmstat — мониторинг процессов, памяти, свопинга, CPU
- iostat — мониторинг дисковых устройств vdc и vdd
- Характер нагрузки: Постепенное увеличение количества одновременных подключений к СУБД с 7 до 22 (рост в 3,14 раза)
3.3. Анализ по ресурсам
3.3.1 Центральный процессор (CPU) — КРИТИЧЕСКАЯ ПРОБЛЕМА
Ключевые метрики:
- Максимальное количество процессов в очереди: procs_r = 60 (превышение доступных ядер в 7,5 раз)
- Процент наблюдений с превышением очереди над ядрами: 86,93% (ALARM)
- Высокие корреляции переключений контекста:
- cs и us: 0,8820 (сильная корреляция с пользовательским временем)
- cs и sy: 0,9665 (очень сильная корреляция с системным временем)
Вывод: CPU является основным bottleneck системы. Недостаточные вычислительные ресурсы приводят к формированию длинной очереди процессов, что свидетельствует о неспособности системы обрабатывать текущую нагрузку. Высокая корреляция переключений контекста с пользовательским временем указывает на проблему в пользовательских запросах/приложении.
3.3.2 Оперативная память (RAM) — СЕРЬЁЗНАЯ ПРОБЛЕМА
Ключевые метрики:
- Процент наблюдений со свободной памятью <5%: 100% (ALARM)
- Общий объём RAM: 7 677 МБ
- Минимальное значение свободной памяти: 200 МБ (2,6% от общего объёма)
- Свопинг: отсутствует (0% наблюдений)
Вывод: Система работает на пределе доступной памяти, что создаёт риски замедления работы и потенциального исчерпания памяти (OOM). Несмотря на эффективное использование кэша и буферов для снижения нагрузки на диски, критически низкий запас свободной памяти требует срочного вмешательства.
3.3.3 Подсистема ввода-вывода (I/O) — БЕЗ КРИТИЧЕСКИХ ПРОБЛЕМ
Ключевые метрики для дисков vdc и vdd:
- Загрузка устройств (%util): 0,02-0,03% (значительно ниже порога в 50%)
- Задержки чтения/записи (r_await/w_await): <5 мс в 100% наблюдений
- Длина очереди запросов (aqu_sz): 0 (очередь отсутствует)
Вывод: Диски не являются bottleneck в данном тесте. Система ввода-вывода справляется с нагрузкой без задержек, чему способствует эффективное кэширование данных в оперативной памяти.
3.4. Корреляция с нагрузкой
Рост количества подключений к СУБД (LOAD) усугублял существующие проблемы:
- CPU: Каждое увеличение LOAD на 1 приводит к росту средней очереди процессов на 2,5-3 единицы. При максимальной нагрузке (22 подключения) очередь достигает 60 процессов.
- RAM: Уровень свободной памяти остаётся критически низким (<5%) на всех этапах теста, независимо от нагрузки.
- Критическая точка перелома: Проблемы с CPU и RAM существовали до начала нагрузочного тестирования. Система была не готова даже к минимальной нагрузке (7 подключений).
Вывод: Рост нагрузки на СУБД не создавал новые проблемы, а лишь проявлял уже существующие ограничения инфраструктуры.