С каждым днем все реальнее становится видение мира, где машины не просто выполняют команды, а понимают, сопереживают и создают. Большие языковые модели (LLM) стоят у истоков этой революции, демонстрируя невероятные возможности в обработке естественного языка, генерации текста и даже творчестве. Но что же такое LLM на самом деле? Какие они бывают и как меняют нашу жизнь уже сегодня?
В этой статье мы рассмотрим:
- Что такое большие языковые модели?
- Какие типы LLM существуют и чем они отличаются?
- Какие параметры имеют LLM и как подобрать нужную?
Готовы ли вы узнать больше о технологиях, которые способны перевернуть наше представление о мире? Тогда вперед!
Открытые и облачные модели: в чем разница?
Прежде всего, LLM можно разделить на две большие категории: открытые и облачные модели.
Открытые модели доступны для свободного использования и модификации. Их код и параметры открыты, что позволяет исследователям и разработчикам изучать их внутреннюю работу, адаптировать под свои задачи и даже создавать новые модели на их основе. Примерами открытых LLM являются Mistral, Qwen, LLaMA и другие.
Облачные модели предоставляются в виде сервисов, доступ к которым осуществляется через API. Пользователи платят за использование модели в зависимости от объема запросов и других параметров. Облачные модели, как правило, более удобны в использовании, так как не требуют установки и настройки собственного оборудования. Примерами облачных LLM являются сервисы Google Cloud AI, Amazon SageMaker, Microsoft Azure AI и другие.
Основные отличия открытых и облачных моделей:
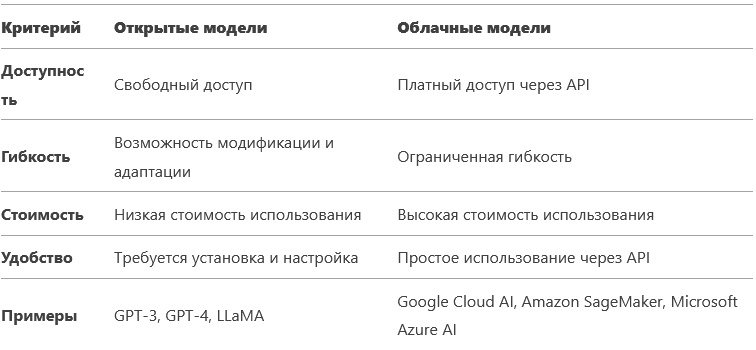
Выбор между открытыми и облачными моделями зависит от конкретных задач, бюджета и уровня технической подготовки.
В следующей части статьи мы рассмотрим основные типы LLM и их особенности.
Типы больших языковых моделей: классификация по входным и выходным данным
Большие языковые модели (LLM) можно классифицировать по типу входных и выходных данных, которые они обрабатывают. Это позволяет лучше понять их возможности и области применения. Рассмотрим основные типы LLM:
1. Текстовые модели (Text-to-Text)
Описание:
Текстовые модели принимают на вход текст и генерируют на выходе текст. Это наиболее распространенный тип LLM, который используется для решения широкого спектра задач, таких как:
- Генерация текста: написание статей, создание контента, наполнение сайтов.
- Перевод: перевод текста с одного языка на другой.
- Резюмирование: создание краткого изложения длинного текста.
- Ответы на вопросы: предоставление ответов на вопросы пользователей.
- Диалоговые системы: поддержание беседы с пользователем.
Примеры моделей:
- GPT-3, GPT-4: универсальные модели, способные решать широкий спектр задач, связанных с обработкой и генерацией текста.
- Qwen: модель, специально разработанная для решения задач, связанных с преобразованием текста.
- Mistral: крупномасштабная модель с открытым исходным кодом, ориентированная на обработку и генерацию текста на многих языках.
2. Текстово-аудио модели (Text-to-Audio)
Описание:
Текстово-аудио модели преобразуют текст в аудио. Они используются для:
- Синтез речи: создание голосовых сообщений, озвучивание текста, создание аудиокниг.
- Доступность: предоставление информации людям с ограниченными возможностями зрения.
Примеры моделей:
- musicgen-melody: модель, для генерации музыки.
- speecht5_tts: модель, предоставляющая синтез речи на многих языках.
- seamless-streaming: модель, для генерации многоязычной речи.
3. Аудио-текстовые модели (Audio-to-Text)
Описание:
Аудио-текстовые модели преобразуют аудио в текст. Они используются для:
- Распознавание речи: преобразование голосовых сообщений в текст, диктовка, транскрибирование аудиозаписей.
- Доступность: предоставление информации людям с ограниченными возможностями слуха.
Примеры моделей:
- openai/whisper: модель, обеспечивающая распознавание речи на многих языках с высокой точностью.
- mms-lid: определение языка аудиофайла.
- wav2vec2: модель для распознания речи.
4. Текстово-визуальные модели (Text-to-Image)
Описание:
Текстово-визуальные модели преобразуют текст в изображения. Они используются для:
- Генерация изображений: создание изображений по текстовому описанию, визуализация данных, создание иллюстраций.
- Дополненная реальность: создание виртуальных объектов по текстовому описанию.
Примеры моделей:
- DALL-E: модель от OpenAI, способная генерировать реалистичные изображения по текстовому описанию.
- Stable Diffusion: открытая модель, которая может создавать изображения по тексту, а также изменять существующие изображения.
- MidJourney: платформа для генерации изображений по тексту с использованием искусственного интеллекта.
5. Визуально-текстовые модели (Image-to-Text)
Описание:
Визуально-текстовые модели преобразуют изображения в текст. Они используются для:
- Оптическое распознавание символов (OCR): извлечение текста из изображений, сканирование документов.
- Описание изображений: создание текстового описания содержания изображения, доступность для людей с ограниченными возможностями зрения.
Примеры моделей:
- trocr: модель для распознания символов на изображении.
- blip-image-captioning: модель позволяет задать вопросы по изображению.
- CLIP (Contrastive Language–Image Pretraining): модель от OpenAI, способная понимать связь между изображениями и текстом, что позволяет ей выполнять задачи, связанные с описанием изображений и поиском изображений по тексту.
Классификация LLM по типу входных и выходных данных позволяет лучше понять их возможности и области применения. Выбор подходящей модели зависит от конкретных задач, с которыми вы сталкиваетесь.
Сжатые и несжатые LLM: оптимизация для эффективного использования
Большие языковые модели (LLM) обладают огромным потенциалом, но их использование сопряжено с рядом вызовов, таких как высокие требования к вычислительным ресурсам, памяти и времени обработки. Для решения этих проблем были разработаны сжатые LLM, которые сохраняют высокое качество генерации при меньшем объеме параметров и более высокой скорости работы.
Сжатые LLM: методы оптимизации
Сжатые LLM достигаются за счет применения различных методов оптимизации, таких как:
1. Квантование:
- Описание: Процесс уменьшения разрядности весов и активаций модели, что позволяет сократить объем памяти и повысить скорость вычислений.
- Типы квантования:
- Пороговое квантование: Веса и активации округляются до ближайшего значения из заданного набора.
- Линейное квантование: Веса и активации масштабируются и округляются до ближайшего целого числа.
- Нелинейное квантование: Используются более сложные функции для сопоставления весов и активаций с меньшим набором значений.
- системы.
- Примеры:
GPTQ: Метод квантования, разработанный для сжатия моделей GPT.
LLM.int8(): Метод квантования, который позволяет работать с моделями GPT-3 в 8-битном формате.
AWQ (Activation-aware Weight Quantization): Метод квантования, который учитывает активации нейронов при выборе значений для квантования весов, что позволяет сохранить точность модели.
GGUF (GGML Universal Format): Формат квантования, разработанный для эффективного хранения и выполнения моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встроенные
2. Обрезание:
- Описание: Процесс удаления наименее значимых нейронов или связей в модели, что позволяет уменьшить ее размер без существенной потери качества.
- Типы обрезания:
- Обрезание по весам: Удаление связей с наименьшими весами.
- Обрезание по активациям: Удаление нейронов с наименьшей активацией.
- Обрезание по градиенту: Удаление нейронов, которые вносят наименьший вклад в градиент.
- Примеры:
- SparseGPT: Метод обрезания, разработанный для сжатия моделей GPT.
- Lottery Ticket Hypothesis: Исследование, которое показало, что удаление "лишних" нейронов может улучшить производительность модели.
3. Модульное сжатие:
- Описание: Разделение модели на модули и сжатие каждого модуля отдельно.
- Примеры:
- DistilBERT: Уменьшенная версия BERT, созданная путем обучения меньшей модели на данных большей модели.
- TinyBERT: Еще одна уменьшенная версия BERT, которая использует методы квантования и обрезания.
Число параметров: влияние на качество генерации
Число параметров в LLM определяет ее сложность и, как следствие, ее способность к генерации текста высокого качества.
- Больше параметров:
- Плюсы: Большая способность к моделированию языка, лучшее понимание контекста, более разнообразные и точные ответы.
- Минусы: Высокие требования к вычислительным ресурсам, памяти и времени обработки.
- Меньше параметров:
- Плюсы: Меньшие требования к вычислительным ресурсам, памяти и времени обработки.
- Минусы: Меньшая способность к моделированию языка, худшее понимание контекста, менее разнообразные и менее точные ответы.
Важно: Сжатие модели не всегда приводит к ухудшению качества генерации. Эффективные методы сжатия позволяют сохранить или даже улучшить качество при меньшем числе параметров.
Сжатые LLM - это важный шаг в развитии технологии, который позволяет сделать ее более доступной и эффективной. Выбор подходящего метода сжатия и оптимизации числа параметров зависит от конкретных задач и доступных ресурсов.
Длина контекста: влияние на качество генерации
Длина контекста — это еще один важный параметр, который влияет на качество генерации текста в больших языковых моделях (LLM). Длина контекста определяет, сколько предыдущих токенов (слов или фрагментов слов) модель может учитывать при генерации следующего токена. Чем длиннее контекст, тем больше информации модель может использовать для генерации более релевантного и согласованного текста.
Влияние длины контекста на качество генерации:
- Более длинный контекст:
Плюсы:
Улучшенное понимание контекста: Модель может лучше понимать связи между предложениями и абзацами, что приводит к более логичной и согласованной генерации текста.
Поддержка длинных диалогов и текстов: Более длинный контекст позволяет модели эффективно работать с длинными текстами, такими как статьи, книги или многоходовые диалоги.
Улучшенная релевантность: Модель может генерировать текст, более релевантный предыдущему контексту, что особенно важно для задач, требующих глубокого понимания предметной области.
Минусы:
Высокие требования к памяти: Более длинный контекст требует больше памяти для хранения предыдущих токенов, что может быть проблематично на устройствах с ограниченными ресурсами.
Медленная обработка: Обработка более длинного контекста может занимать больше времени, что может быть критично для приложений с жесткими требованиями к скорости. - Более короткий контекст:
Плюсы:
Эффективность использования ресурсов: Более короткий контекст требует меньше памяти и вычислительных ресурсов, что делает модель более доступной для использования на устройствах с ограниченными ресурсами.
Быстрая обработка: Обработка более короткого контекста происходит быстрее, что может быть важно для приложений, требующих мгновенного ответа.
Минусы:
Ухудшение качества генерации: Модель может генерировать текст, менее релевантный предыдущему контексту, что может привести к потере логической связности и согласованности.
Ограниченная поддержка длинных текстов: Более короткий контекст может быть недостаточным для обработки длинных текстов или сложных диалогов.
Практические рекомендации по подбору LLM
Выбор подходящей большой языковой модели (LLM) - это комплексная задача, которая требует учета множества факторов. В этой части статьи мы предоставим практические рекомендации, которые помогут вам сделать осознанный выбор LLM для ваших задач.
1. Открытые LLM: преимущества для корпоративного использования
Открытые LLM обладают рядом преимуществ, которые делают их привлекательным выбором для развертывания внутри защищенного контура компании:
- Контроль данных: Используя открытые модели, вы сохраняете полный контроль над данными, которые обрабатываются моделью. Это особенно важно для компаний, работающих с конфиденциальной информацией.
- Гибкость и настройка: Открытые модели предоставляют возможность модификации и адаптации под специфические задачи компании. Вы можете обучать модели на собственных данных, добавлять доменную лексику и настраивать поведение модели.
- Безопасность: Развертывание открытых моделей внутри защищенного контура снижает риски, связанные с передачей данных во внешние облачные сервисы.
Рекомендация: Если ваша компания работает с конфиденциальными данными и вам важна гибкость и контроль, рассмотрите возможность использования открытых LLM.
2. Тип модели: выбор в зависимости от задач
Важно определиться с необходимым типом модели в зависимости от стоящих перед вами задач. LLM можно разделить на несколько основных типов по типу входных и выходных данных:
- Генерация текста (Text-to-Text): Подходит для задач, связанных с созданием, переводом, резюмированием и ответами на вопросы.
- Распознавание картинок (Image-to-Text): Используется для извлечения текста из изображений и описания содержания изображений.
- Генерация звука (Text-to-Audio): Применяется для синтеза речи и создания аудиоконтента.
- Генерация изображений (Text-to-Image): Позволяет создавать изображения по текстовому описанию.
Рекомендация: Выбирайте тип модели, который наилучшим образом соответствует вашим задачам. Например, для создания контента выберите модель генерации текста, а для синтеза речи - модель генерации звука.
Ресурсы железа: определение числа параметров и размера квантования
Доступные вычислительные ресурсы играют ключевую роль в выборе большой языковой модели (LLM). Чем больше параметров имеет модель, тем выше ее качество, но и тем больше требуется ресурсов для ее работы. Важно учитывать не только число параметров, но и размер квантования, а также длину контекста, чтобы найти оптимальный баланс между качеством и эффективностью использования ресурсов.
Число параметров:
- Большие модели с миллиардами параметров:
Плюсы:
Высокое качество генерации: Большое количество параметров позволяет модели лучше понимать язык, генерировать более разнообразный и точный текст.
Улучшенное понимание контекста: Модели с большим числом параметров способны лучше учитывать контекст, что важно для задач, требующих глубокого понимания предметной области.
Минусы:
Высокие требования к ресурсам: Работа с такими моделями требует мощных GPU и большого объема памяти, что может быть проблематично для устройств с ограниченными ресурсами.
Длительное время обработки: Большие модели могут обрабатывать запросы медленнее, что может быть критично для приложений с жесткими требованиями к скорости. - Сжатые модели с меньшим числом параметров:
Плюсы:
Эффективное использование ресурсов: Меньшее количество параметров позволяет модели работать на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы.
Быстрая обработка: Сжатые модели могут обрабатывать запросы быстрее, что важно для приложений, требующих мгновенного ответа.
Минусы:
Снижение качества генерации: Меньшее количество параметров может привести к ухудшению качества генерации текста, особенно в сложных или специализированных областях.
Ограниченная способность к моделированию языка: Сжатые модели могут хуже понимать контекст и генерировать менее релевантный текст.
Размер квантования:
- Квантование:
Описание: Процесс уменьшения разрядности весов и активаций модели, что позволяет сократить объем памяти и повысить скорость вычислений.
Типы квантования:
Пороговое квантование: Веса и активации округляются до ближайшего значения из заданного набора.
Линейное квантование: Веса и активации масштабируются и округляются до ближайшего целого числа.
Нелинейное квантование: Используются более сложные функции для сопоставления весов и активаций с меньшим набором значений.
Примеры:
GPTQ: Метод квантования, разработанный для сжатия моделей GPT.
LLM.int8(): Метод квантования, который позволяет работать с моделями GPT-3 в 8-битном формате.
AWQ (Activation-aware Weight Quantization): Метод квантования, который учитывает активации нейронов при выборе значений для квантования весов, что позволяет сохранить точность модели.
GGUF (GGML Universal Format): Формат квантования, разработанный для эффективного хранения и выполнения моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встроенные системы.
Длина контекста:
- Влияние длины контекста на качество генерации:
Более длинный контекст:
Плюсы:
Улучшенное понимание контекста: Модель может лучше понимать связи между предложениями и абзацами, что приводит к более логичной и согласованной генерации текста.
Поддержка длинных диалогов и текстов: Более длинный контекст позволяет модели эффективно работать с длинными текстами, такими как статьи, книги или многоходовые диалоги.
Улучшенная релевантность: Модель может генерировать текст, более релевантный предыдущему контексту, что особенно важно для задач, требующих глубокого понимания предметной области.
Минусы:
Высокие требования к памяти: Более длинный контекст требует больше памяти для хранения предыдущих токенов, что может быть проблематично на устройствах с ограниченными ресурсами.
Медленная обработка: Обработка более длинного контекста может занимать больше времени, что может быть критично для приложений с жесткими требованиями к скорости.
Более короткий контекст:
Плюсы:
Эффективность использования ресурсов: Более короткий контекст требует меньше памяти и вычислительных ресурсов, что делает модель более доступной для использования на устройствах с ограниченными ресурсами.
Быстрая обработка: Обработка более короткого контекста происходит быстрее, что может быть важно для приложений, требующих мгновенного ответа.
Минусы:
Ухудшение качества генерации: Модель может генерировать текст, менее релевантный предыдущему контексту, что может привести к потере логической связности и согласованности.
Ограниченная поддержка длинных текстов: Более короткий контекст может быть недостаточным для обработки длинных текстов или сложных диалогов.
Практические рекомендации:
- Оцените доступные вам вычислительные ресурсы: Учитывайте не только мощность GPU и объем памяти, но и скорость обработки и доступность ресурсов для вашего приложения.
- Выберите модель с оптимальным соотношением числа параметров и размера квантования: Для начала можно попробовать сжатые модели с умеренным квантованием и оценить их производительность.
- Учитывайте длину контекста: Выбирайте длину контекста, которая наилучшим образом соответствует вашим задачам и доступным ресурсам. Для задач, требующих глубокого понимания контекста, выбирайте модели с более длинным контекстом, а для задач с ограниченными ресурсами — модели с более коротким контекстом.
Следуя этим рекомендациям, вы сможете сделать осознанный выбор LLM, который будет оптимально соответствовать вашим задачам и доступным ресурсам.
Заключение
Выбор подходящей LLM требует тщательного анализа задач, доступных ресурсов и требований к безопасности. Следуя представленным рекомендациям, вы сможете сделать осознанный выбор и максимально эффективно использовать возможности больших языковых моделей для решения ваших задач.
Различные варианты LLM можно посмотреть на https://huggingface.co/models