Машинное обучение (ML) стало основой современных решений для анализа данных. Чтобы построить модели, которые могут успешно решать задачи бизнеса, необходимо понимать работу с признаками и оценку качества модели.

1. Регрессионный анализ: Линейная, полиномиальная и логарифмическая регрессия
Регрессионный анализ — это метод, используемый для определения зависимости одной переменной (зависимой или целевой) от одной или нескольких других переменных (независимых признаков). Этот анализ является основой многих моделей машинного обучения, когда требуется предсказать числовое значение. В зависимости от характера данных и взаимосвязи между переменными, используются разные виды регрессии.
Линейная регрессия
Линейная регрессия — самый простой и распространённый вид регрессии, при котором предполагается, что между целевой переменной и независимыми признаками существует линейная зависимость. Модель линейной регрессии можно представить как уравнение:
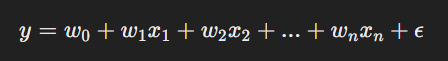
Где:
- yyy — целевая переменная,
- x1,x2,...,xnx_1, x_2, ..., x_nx1,x2,...,xn — независимые признаки,
- w0w_0w0 — свободный член (интерсепт),
- w1,w2,...,wnw_1, w_2, ..., w_nw1,w2,...,wn — коэффициенты при признаках, которые модель пытается определить,
- ϵ\epsilonϵ — ошибка модели.
Пример: предположим, что вы хотите предсказать цену квартиры на основе её площади и количества комнат. Линейная регрессия строит зависимость между этими признаками и ценой, настраивая коэффициенты модели.
Преимущества:
- Простота в реализации и интерпретации.
- Хорошо работает с линейными зависимостями.
Недостатки:
- Не подходит для сложных, нелинейных зависимостей.
- Чувствительна к выбросам и корреляции между признаками.
Полиномиальная регрессия
Когда зависимость между целевой переменной и признаками нелинейна, полиномиальная регрессия предоставляет более гибкую модель. Она расширяет линейную модель, добавляя полиномиальные степени независимых переменных:
Где x2,x3,...x^2, x^3, ...x2,x3,... — это полиномиальные степени признака.
Пример: если зависимость между площадью квартиры и её ценой имеет параболическую форму (например, цена сначала быстро растёт с увеличением площади, но потом её прирост замедляется), полиномиальная регрессия поможет смоделировать такую нелинейность.
Преимущества:
- Способна моделировать более сложные зависимости между признаками и целевой переменной.
- Увеличивает гибкость модели.
Недостатки:
- При слишком высоких степенях полиномов модель может переобучаться.
- Более сложна в интерпретации.
Логарифмическая регрессия
Логарифмическая регрессия применяется в случаях, когда зависимость переменных замедляется по мере увеличения значений признака. Модель принимает форму:
Пример: если увеличение стоимости продукта замедляется с увеличением его количества, логарифмическая регрессия может лучше описывать эту взаимосвязь.
Преимущества:
- Моделирует нелинейные зависимости, которые замедляются с ростом признаков.
- Легко интерпретируема в определённых ситуациях, особенно в экономике и финансах.
Недостатки:
- Неэффективна, если зависимость не имеет логарифмического характера.
- Требует трансформации данных для использования логарифма.
2. Классификация: Логистическая регрессия и Метод опорных векторов (SVM)
Классификация — это задача присвоения объектов к одной из заранее известных категорий или классов на основе признаков. В отличие от регрессии, которая предсказывает непрерывное значение, классификация решает задачи, связанные с предсказанием категорий (например, болен или здоров, спам или не спам). В этой статье мы рассмотрим два популярных метода классификации: логистическую регрессию и метод опорных векторов (SVM).
Логистическая регрессия
Логистическая регрессия используется для бинарных задач классификации, то есть когда есть два возможных класса (например, 0 или 1, «да» или «нет»). В отличие от линейной регрессии, которая предсказывает непрерывное значение, логистическая регрессия предсказывает вероятность принадлежности объекта к одному из классов. На основе этого прогноза вероятность затем преобразуется в один из двух классов.
Формула логистической регрессии выглядит так:
Где:
Преобразование сигмоидальной функции
В отличие от линейной регрессии, в логистической регрессии результат передаётся через сигмоидальную функцию, которая ограничивает значения предсказаний в диапазоне от 0 до 1. Это и есть вероятностная интерпретация. Сигмоидальная функция имеет форму:
Где z — линейная комбинация признаков.
Пример
Предположим, у вас есть данные о пациентах, включая такие признаки, как возраст, артериальное давление и уровень холестерина. Цель — предсказать, есть ли у пациента сердечное заболевание (класс 1) или нет (класс 0). Логистическая регрессия обучается на этих данных, чтобы предсказать вероятность наличия заболевания для новых пациентов.
Преимущества логистической регрессии:
- Простота интерпретации: коэффициенты в модели указывают на влияние каждого признака на вероятность целевого класса.
- Устойчива к переобучению: благодаря линейной природе она не склонна к переусложнению.
- Быстрая тренировка и вычисления: особенно полезна для больших наборов данных с большим количеством объектов.
Недостатки:
- Неэффективна для сложных зависимостей: если классы нелинейно разделены, логистическая регрессия не может эффективно решить задачу.
- Ограничена двумя классами: стандартная логистическая регрессия используется для бинарной классификации (хотя существуют расширения для многоклассовых задач).
Метод опорных векторов (SVM)
Метод опорных векторов (SVM, Support Vector Machine) — это мощный алгоритм для задач классификации, который ищет оптимальную гиперплоскость, разделяющую классы в многомерном пространстве признаков. Основная цель SVM — найти такую гиперплоскость, которая максимально увеличивает расстояние между точками разных классов, что позволяет минимизировать ошибку классификации.
Основные понятия SVM:
- Гиперплоскость: в двумерном пространстве это прямая линия, а в многомерном пространстве — это гиперплоскость, разделяющая данные на разные классы.
- Опорные векторы: это те объекты из набора данных, которые находятся наиболее близко к разделяющей гиперплоскости. Именно они оказывают влияние на определение положения этой гиперплоскости.
- Маржин (отступ): расстояние между разделяющей гиперплоскостью и ближайшими точками (опорными векторами) обоих классов. Задача SVM — максимизировать этот отступ.
Линейная и нелинейная классификация
- Линейная классификация: SVM ищет линейную гиперплоскость для разделения классов. Это подходит для данных, которые можно линейно разделить.
- Нелинейная классификация: для сложных данных, которые нельзя разделить линейной гиперплоскостью, SVM использует ядерные методы (kernel methods). Ядро преобразует исходное пространство признаков в более высокоразмерное пространство, где классы могут быть линейно разделены.
Наиболее популярные ядра:
- Линейное ядро: используется, когда данные линейно разделимы.
- Полиномиальное ядро: полезно, когда есть полиномиальные зависимости между признаками.
- Ядро Гаусса (RBF): для сложных, нелинейных зависимостей.
Пример
Допустим, у вас есть данные о клиентах банка, и вам нужно предсказать, покинет ли клиент банк (класс 1) или останется (класс 0). Признаки могут включать возраст клиента, его баланс на счету, активность в течение года и другие параметры. SVM будет искать гиперплоскость, которая разделит клиентов с разными решениями.
Преимущества SVM:
- Эффективен при высоких размерностях: хорошо работает с данными, которые имеют большое количество признаков (например, текстовые данные).
- Подходит для задач с небольшими выборками: в отличие от некоторых других методов, SVM может показать хорошие результаты даже при малом количестве обучающих данных.
- Гибкость через ядра: использование разных ядер позволяет адаптировать модель к сложным зависимостям между признаками.
Недостатки:
- Чувствительность к выбору гиперпараметров: выбор правильного ядра и настроек параметров (например, параметра C) может значительно влиять на результат.
- Трудности с интерпретацией: в отличие от логистической регрессии, результаты SVM сложнее интерпретировать, особенно при использовании нелинейных ядер.
- Требования к вычислительным ресурсам: при больших наборах данных или высокоразмерных признаках время обучения может быть значительным.
3. Функции потерь и оптимизация
Функции потерь и методы оптимизации — это ключевые компоненты процесса обучения моделей машинного обучения. Функция потерь измеряет, насколько предсказания модели отличаются от фактических значений, а оптимизация — это процесс минимизации этой ошибки. Правильный выбор функции потерь и метода оптимизации напрямую влияет на успех модели.
Функции потерь
Функция потерь (или функция стоимости) — это мера, показывающая, насколько предсказания модели отличаются от реальных значений. Она задаёт "цену" ошибки, то есть насколько сильно модель отклонилась от правильного результата. Выбор функции потерь зависит от задачи, которую решает модель (регрессия или классификация), и природы данных.
1. Среднеквадратичная ошибка (MSE)
MSE (Mean Squared Error) — одна из самых популярных функций потерь для задач регрессии. Она вычисляет среднюю величину квадрата разницы между предсказанными и реальными значениями.
Формула MSE:
MSE акцентирует внимание на больших ошибках, так как ошибки возводятся в квадрат. Это полезно, когда важно, чтобы большие отклонения от реальных значений были минимизированы.
2. Средняя абсолютная ошибка (MAE)
MAE (Mean Absolute Error) — ещё одна популярная функция для регрессионных задач. В отличие от MSE, MAE вычисляет среднюю абсолютную разницу между предсказанными и реальными значениями.
Формула MAE:
MAE менее чувствительна к выбросам по сравнению с MSE, так как ошибки не возводятся в квадрат.
3. Кросс-энтропия (Log Loss)
Кросс-энтропия (Log Loss) — это функция потерь, применяемая в задачах классификации, особенно для бинарных и многоклассовых задач. Она измеряет разницу между фактическим классом и предсказанной вероятностью для данного класса.
Формула кросс-энтропии для бинарной классификации:
Кросс-энтропия акцентирует внимание на тех примерах, где модель сильно ошибается, что помогает лучше корректировать обучение.
4. Гинг (Hinge loss)
Гинг-функция потерь используется в задачах с методом опорных векторов (SVM). Она вычисляет ошибку для классификационных задач, где важна правильность положения предсказания относительно гиперплоскости разделения классов.
Формула для бинарной классификации:
Если объект правильно классифицирован с достаточно большим отступом от гиперплоскости, потери равны нулю. Если объект расположен слишком близко к гиперплоскости или классифицирован неверно, возникают потери.
Методы оптимизации
Оптимизация — это процесс поиска таких параметров модели, которые минимизируют выбранную функцию потерь. В машинном обучении чаще всего используются градиентные методы оптимизации, которые основаны на вычислении градиента функции потерь и её обновлении на каждом шаге.
1. Градиентный спуск
Градиентный спуск (Gradient Descent) — это один из самых распространённых методов оптимизации, используемый для минимизации функции потерь. Идея заключается в том, чтобы изменять параметры модели в направлении антиградиента функции потерь. Это позволяет постепенно уменьшать ошибку и улучшать предсказания модели.
Формула обновления параметров:
Виды градиентного спуска:
- Полный градиентный спуск (Batch Gradient Descent): обновляет параметры после вычисления градиента по всему набору данных. Подходит для небольших наборов данных, но может быть медленным на больших данных.
- Стохастический градиентный спуск (Stochastic Gradient Descent, SGD): обновляет параметры после вычисления градиента для одного примера данных. Быстрее, но шумнее, так как обновления происходят чаще и на каждом шаге меняются.
- Мини-выборочный градиентный спуск (Mini-batch Gradient Descent): комбинирует преимущества двух предыдущих методов, обновляя параметры по мини-батчам (небольшим наборам данных).
2. Адаптивные методы оптимизации
Адаптивные методы изменяют шаг обучения в процессе обучения, что позволяет модели быстрее сходиться к оптимальному решению.
- Adam (Adaptive Moment Estimation): один из самых популярных адаптивных методов, который сочетает в себе преимущества градиентного спуска с моментом и RMSProp. Он использует как первую моментную оценку (среднее значение градиента), так и вторую моментную оценку (квадрат градиента), что делает его очень эффективным для большинства задач.
Формулы обновления в Adam:
2) \cdot (\nabla\theta J(\theta))^2 ]
Где:
Преимущества адаптивных методов:
- Автоматическая настройка шагов обучения: адаптивные методы автоматически корректируют шаг обучения для каждого параметра в зависимости от их градиентов, что ускоряет обучение.
- Устойчивость к редким большим обновлениям: методы, такие как Adam, используют экспоненциальное сглаживание, что делает их более устойчивыми к шуму в данных.
Недостатки:
- Переобучение: из-за слишком быстрого сходимости модели могут переобучаться на обучающих данных.
- Чувствительность к гиперпараметрам: хотя методы адаптивны, они всё ещё требуют настройки начальных параметров, таких как шаг обучения и моменты.
3. Методы второго порядка
Методы второго порядка, такие как метод Ньютона, используют не только градиенты, но и вторые производные (Гессиан) функции потерь для более точного поиска минимума.
Преимущества:
- Более точное направление обновления параметров: методы второго порядка учитывают кривизну поверхности функции потерь, что может привести к более быстрому сходу к оптимальному решению.
Недостатки:
- Высокая вычислительная сложность: вычисление Гессиана требует значительных ресурсов, особенно для моделей с большим количеством параметров, поэтому эти методы редко используются для больших задач.
4. Оценка точности модели, переобучение и регуляризация
Оценка точности модели, предотвращение переобучения и использование регуляризации — это ключевые аспекты построения надёжных и хорошо обобщающих моделей машинного обучения. В этом разделе мы подробно рассмотрим, как правильно оценивать модель, избегать переобучения и улучшать её общую производительность с помощью методов регуляризации.
Оценка точности модели
После того как модель обучена, важно оценить её качество, то есть насколько точно она может делать предсказания для новых данных, которых не было в обучающей выборке. Существует несколько методов и метрик для оценки модели в зависимости от задачи (регрессия или классификация).
1. Кросс-валидация
Кросс-валидация (Cross-validation) — это метод оценки, который позволяет проверить способность модели к обобщению на новых данных. Наиболее распространённый вариант — это k-fold кросс-валидация.
Процесс заключается в следующем:
- Данные делятся на kkk равных частей (folds).
- Модель обучается на k−1k-1k−1 частях,
- Модель обучается на k−1k-1k−1 частях, а затем проверяется на оставшейся одной части (называемой валидационным набором).
- Процесс повторяется kkk раз, каждый раз используя другую часть данных для проверки, а оставшиеся части — для обучения.
- Итоговая оценка модели получается путём усреднения всех kkk оценок.
Этот метод помогает уменьшить влияние случайных разбиений данных на тренировочную и тестовую выборки, что делает оценку более устойчивой и точной.
Преимущества кросс-валидации:
- Надёжность: учитываются все данные, и каждая часть данных поочередно становится и обучающей, и тестовой.
- Меньшая зависимость от случайных разбиений данных: модель проверяется на разных частях выборки, что даёт более точное представление о её обобщающей способности.
2. Метрики оценки точности
Выбор метрики зависит от типа задачи (регрессия или классификация).
Для регрессии:
- Среднеквадратичная ошибка (MSE): измеряет среднюю квадратичную разницу между предсказанными и истинными значениями. Чем меньше MSE, тем лучше модель.
- Средняя абсолютная ошибка (MAE): вычисляет среднюю абсолютную разницу между предсказанными и фактическими значениями. MAE менее чувствительна к выбросам по сравнению с MSE.
- R² (коэффициент детерминации): показывает, какую долю дисперсии целевой переменной объясняет модель. Значение R2R^2R2, близкое к 1, указывает на хорошее качество модели.
Для классификации:
- Accuracy (точность): доля правильных предсказаний среди всех предсказаний. Хорошо подходит для задач с примерно равным количеством классов.
- Precision (точность): доля правильных положительных предсказаний среди всех предсказанных положительных классов. Важна для задач, где критичны ложные срабатывания.
- Recall (полнота): доля правильно предсказанных положительных классов среди всех фактических положительных. Важна для задач, где критичны пропуски положительных классов.
- F1-score: гармоническое среднее precision и recall. Используется, когда важно сбалансировать эти два показателя.
- ROC AUC (площадь под кривой ошибок): показывает, насколько хорошо модель различает классы. Чем больше значение AUC (максимум 1), тем лучше модель справляется с классификацией.
Переобучение (overfitting)
Переобучение (overfitting) происходит, когда модель слишком хорошо запоминает обучающую выборку, но не может обобщать на новых данных. В результате модель отлично работает на тренировочных данных, но показывает низкие результаты на тестовой выборке.
Причины переобучения:
- Слишком сложная модель: если модель слишком гибкая (например, использует слишком много параметров), она может подстроиться под все особенности обучающей выборки, включая шум.
- Недостаток данных: при малом количестве данных модель может запоминать конкретные примеры, а не выявлять общие закономерности.
- Слишком долгое обучение: если модель тренируется слишком долго, она может начать подстраиваться под конкретные особенности тренировочной выборки.
Признаки переобучения:
- Низкая ошибка на обучающей выборке и высокая ошибка на тестовой выборке.
- Чрезмерно точные предсказания на обучающей выборке, которые не подтверждаются на новых данных.
Методы борьбы с переобучением:
- Регуляризация: добавление штрафов за сложность модели.
- Сокращение количества признаков: удаление незначимых признаков, чтобы уменьшить размерность и сложность модели.
- Использование большего набора данных: помогает модели обучаться на большем количестве примеров и лучше выявлять закономерности.
- Прекращение обучения на ранней стадии (early stopping): метод остановки обучения модели, если её производительность на валидационных данных перестаёт улучшаться.
Регуляризация
Регуляризация — это метод, который позволяет избежать переобучения, добавляя штраф за слишком сложную модель. Это помогает сделать модель менее подверженной влиянию шумов и улучшить её способность к обобщению.
1. L1-регуляризация (Lasso)
L1-регуляризация добавляет к функции потерь сумму абсолютных значений коэффициентов модели:
Где:
L1-регуляризация может занулять некоторые коэффициенты модели, что делает её подходящей для отбора признаков, так как она автоматически исключает менее значимые признаки.
2. L2-регуляризация (Ridge)
L2-регуляризация добавляет к функции потерь сумму квадратов коэффициентов:
L2-регуляризация сглаживает значения коэффициентов, делая их меньше, но не зануляет их. Этот метод помогает снизить сложность модели и уменьшить влияние на результаты выбросов.
3. ElasticNet
ElasticNet — это комбинация L1 и L2-регуляризаций. Она используется, когда необходим баланс между автоматическим отбором признаков (L1) и сглаживанием коэффициентов (L2). Формула регуляризации ElasticNet выглядит следующим образом:
Преимущества регуляризации:
- Предотвращает переобучение: регуляризация снижает вероятность того, что модель будет слишком подстраиваться под обучающие данные.
- Стабильность модели: регуляризованные модели обычно более устойчивы к изменениям в данных.
- Автоматический отбор признаков: L1-регуляризация может занулять незначимые коэффициенты, что делает её полезной для задач с большим количеством признаков.
5. Проблема качества данных: Пропуски и выбросы
Качество данных — один из важнейших факторов, влияющих на успех моделей машинного обучения. «Грязные» данные, содержащие ошибки, пропуски или выбросы, могут существенно снизить точность моделей и сделать результаты ненадёжными. В этом разделе мы рассмотрим, как справляться с основными проблемами качества данных, такими как пропущенные значения и выбросы, а также поговорим о методах их обработки.
Проблемы качества данных
Когда данные не являются чистыми или структурированными, это создаёт ряд проблем, которые могут повлиять на обучение моделей. Основные проблемы включают:
- Пропущенные значения: это когда данные отсутствуют для одной или нескольких переменных в наборе данных.
- Выбросы (аномалии): это наблюдения, которые сильно отличаются от остальных данных, и могут исказить результаты анализа или обучения.
Эти проблемы могут возникать по различным причинам, таким как ошибки при сборе данных, технические сбои, человеческий фактор и другие. Если не учитывать эти факторы, модель может быть либо слишком неточной, либо переобученной.
1. Работа с пропусками данных
Пропущенные данные — это одна из наиболее распространённых проблем в реальных наборах данных. Пропуски могут возникать по многим причинам: ошибки ввода, проблемы при сборе данных или отсутствующие записи. Важно правильно обработать пропуски, чтобы минимизировать их влияние на качество модели.
Типы пропущенных данных:
- MCAR (Missing Completely at Random): данные отсутствуют случайным образом, без какой-либо связи с другими признаками или целевой переменной.
- MAR (Missing at Random): данные пропущены не случайным образом, но пропуски могут быть объяснены другими признаками.
- MNAR (Missing Not at Random): данные пропущены не случайно, и это связано с самим признаком (например, люди неохотно раскрывают свой доход в анкетах).
Методы обработки пропусков:
1. Удаление строк или признаков
Этот метод заключается в полном удалении строк или признаков, содержащих пропущенные значения. Он может быть применён, если количество пропусков невелико или если признак с пропусками незначителен для модели.
- Удаление строк: можно использовать, если строки с пропущенными данными составляют небольшой процент от общего количества записей. Это предотвращает добавление шумов в модель, но не подходит для больших наборов данных с большим количеством пропусков.
- Удаление признаков: может быть использовано, если конкретный признак содержит много пропусков и его удаление не повлияет на общую производительность модели.
Преимущества:
- Простой метод для небольших наборов данных.
- Помогает избежать ложных предположений о пропущенных значениях.
Недостатки:
- Потеря информации, которая могла бы быть полезной для модели.
- Невозможно использовать, если пропусков много, или они критически важны для модели.
2. Заполнение пропущенных данных (импьютация)
Этот метод подразумевает заполнение пропусков разумными значениями, чтобы сохранить целостность данных. Существует несколько методов импьютации:
- Заполнение средним/медианой/модой: для числовых признаков пропуски можно заполнить средним, медианой или модой по этому признаку. Этот метод хорошо работает для признаков с нормальным распределением, но может быть неэффективен при наличии выбросов.
- Импьютация с использованием k-ближайших соседей (KNN Imputation): этот метод заполняет пропуски, используя значения, наиболее близкие к отсутствующим, основываясь на других наблюдениях (соседях).
- Множественная импьютация (Multiple Imputation): метод, при котором пропуски заполняются несколькими возможными значениями, а затем результаты усредняются. Это помогает избежать введения систематической ошибки при импьютации.
- Моделирование пропусков: можно использовать регрессию или другие модели для предсказания пропущенных значений на основе имеющихся данных.
Преимущества:
- Сохранение всех данных, даже при наличии большого числа пропусков.
- Увеличивает точность модели по сравнению с удалением строк или признаков.
Недостатки:
- Может вносить ошибочные предположения, особенно при использовании средних или медианных значений.
- Более сложные методы требуют дополнительных вычислительных ресурсов.
3. Использование индикаторов пропусков
Вместо заполнения пропущенных значений можно создать отдельный бинарный признак, который будет указывать на наличие или отсутствие данных в исходном признаке. Это позволяет модели самостоятельно учитывать пропуски как информацию.
Преимущества:
- Сохранение всех данных без заполнения или удаления.
- Может быть полезно в случае, когда пропуски являются важной информацией.
Недостатки:
- Увеличение размерности данных, что может усложнить модель.
- Требует дополнительного анализа для правильной интерпретации.
2. Работа с выбросами (аномалиями)
Выбросы — это наблюдения, которые сильно отличаются от остальных данных. Они могут возникать по ошибке или быть реальными, но необычными наблюдениями. Выбросы могут искажать обучение моделей, особенно для моделей, чувствительных к значениям, таких как линейная регрессия.
Методы обнаружения выбросов:
1. Графические методы
- Диаграмма размаха (boxplot): визуализирует распределение данных и выделяет потенциальные выбросы как точки, находящиеся за пределами "усов" графика.
- Диаграмма рассеяния (scatter plot): помогает выявить выбросы в зависимости между двумя или более признаками.
2. Статистические методы
- Межквартильный размах (IQR, Interquartile Range): выбросы определяются как данные, которые выходят за пределы 1.5*IQR (разница между первым и третьим квартилями). Этот метод помогает выявить выбросы в признаках с нормально распределёнными данными.
- Z-оценка (Z-score): выбросы определяются как значения, которые имеют абсолютное значение Z-оценки, превышающее заданный порог (например, 3 стандартных отклонения от среднего).
Методы обработки выбросов:
1. Удаление выбросов
Если выбросы являются явными ошибками, их можно удалить из набора данных. Это может быть оправдано, если выбросы составляют незначительную часть данных и не содержат полезной информации.
2. Замена выбросов
Выбросы можно заменить на более реалистичные значения. Например, можно заменить выбросы на значения, находящиеся на границе межквартильного размаха или использовать медианные значения признаков.
3. Логарифмическое или квадратное преобразование данных
Для признаков, содержащих выбросы, можно использовать логарифмическое или квадратное преобразование, чтобы уменьшить влияние выбросов на модель. Это помогает "сгладить" распределение данных.
4. Использование робастных моделей
Некоторые модели машинного обучения, такие как метод ближайших соседей или деревья решений, менее чувствительны к выбросам. Эти модели могут игнорировать выбросы, не давая им значительного веса при обучении.
6. Работа с признаками: Feature Engineering и Feature Selection
Работа с признаками — это ключевая часть подготовки данных для построения моделей машинного обучения. Правильное создание новых признаков (Feature Engineering) и отбор наиболее важных признаков (Feature Selection) помогают улучшить производительность модели, делая её более точной и стабильной. В этом разделе мы рассмотрим методы создания новых признаков и их отбора.
1. Feature Engineering (Создание новых признаков)
Feature Engineering — это процесс создания новых признаков или изменения существующих на основе исходных данных, чтобы улучшить обучение модели. В основе Feature Engineering лежит понимание данных, задач, которые необходимо решить, и создание признаков, которые могут лучше отражать важные закономерности.
Основные методы Feature Engineering:
1. Математические преобразования признаков
Этот метод заключается в применении математических операций к существующим признакам, чтобы создать новые. Примеры таких операций включают:
- Логарифмические преобразования: используются для признаков с большим разбросом значений, чтобы сгладить влияние выбросов. Например, можно использовать логарифм дохода для снижения разброса.
- Степенные преобразования: возведение признака в степень может помочь учесть нелинейные зависимости. Например, признак "возраст" можно преобразовать в "возраст в квадрате", если данные предполагают, что эффект возраста увеличивается или уменьшается с течением времени.
- Полиномиальные признаки: создание новых признаков путём комбинирования существующих. Например, умножение признаков между собой может выявить более сложные зависимости между ними.
2. Создание признаков на основе временных данных
Если данные содержат временные метки, можно извлечь дополнительные полезные признаки:
- Год, месяц, день, час: извлечение отдельных компонент из временных меток может помочь модели лучше понять сезонные или временные паттерны.
- Разница во времени: вычисление разницы между временными событиями, например, сколько времени прошло с момента предыдущей покупки или последнего посещения сайта, может быть полезным признаком для моделей прогнозирования.
3. Создание категориальных признаков
Категориальные признаки могут быть преобразованы в числовые с помощью следующих методов:
- One-hot кодирование: преобразует категориальный признак в набор бинарных признаков. Например, если признак "страна" принимает значения "Россия", "США", "Китай", то создаются три бинарных признака: "Россия", "США", "Китай", где 1 означает принадлежность к категории, а 0 — отсутствие.
- Label Encoding: этот метод присваивает каждой категории числовое значение. Например, категории "Россия", "США", "Китай" могут быть преобразованы в 0, 1, 2 соответственно. Этот метод полезен, если есть смысл в порядке категорий (например, для размера одежды).
4. Агрегация данных
Этот метод полезен, если данные содержат информацию о нескольких событиях или транзакциях для одного объекта. Агрегирование позволяет извлечь новые признаки, которые обобщают эти данные:
- Суммы, средние значения, медианы: например, можно создать признак "средняя сумма покупок клиента", агрегируя данные по всем покупкам клиента.
- Частота событий: можно создать признак, который подсчитывает, сколько раз произошло определённое событие, например, количество посещений сайта за последний месяц.
5. Извлечение текстовых признаков
Если набор данных содержит текстовые данные, их можно преобразовать в числовые признаки с помощью следующих методов:
- Мешок слов (Bag of Words): каждый уникальный термин в тексте становится отдельным признаком, представляющим количество раз, которое этот термин встречается в тексте.
- TF-IDF (Term Frequency-Inverse Document Frequency): метод, который учитывает частоту слов, но также уменьшает вес общих слов, таких как "и", "или", "но", чтобы улучшить качество признаков.
- Word Embeddings: сложные методы преобразования текста в векторные представления, такие как Word2Vec, которые учитывают контекст и смысловые связи между словами.
6. Создание взаимодействующих признаков
Иногда комбинации нескольких признаков могут лучше отражать взаимосвязи между ними. Взаимодействующие признаки можно создать путём умножения или деления одного признака на другой. Например, признак "площадь квартиры" можно разделить на "количество комнат", чтобы получить признак "средняя площадь на комнату", который может лучше объяснять цену квартиры.
Преимущества Feature Engineering:
- Повышение точности модели: хорошо продуманное создание новых признаков может значительно улучшить способность модели выявлять важные закономерности.
- Учёт сложных зависимостей: создание нелинейных или взаимодействующих признаков помогает моделям лучше отражать сложные зависимости между переменными.
Недостатки:
- Временные затраты: процесс создания новых признаков требует времени и глубокого анализа данных.
- Опасность переобучения: создание слишком большого числа признаков может привести к переобучению модели, если они не будут иметь реальной полезности.
2. Feature Selection (Отбор признаков)
Feature Selection — это процесс отбора наиболее значимых признаков для модели с целью улучшения её производительности, уменьшения вычислительных затрат и предотвращения переобучения. Избыток признаков может усложнить модель и ухудшить её способность к обобщению. Отбор признаков позволяет сфокусироваться только на тех переменных, которые действительно важны для предсказаний.
Основные методы Feature Selection:
1. Фильтрационные методы
Фильтрационные методы оценивают важность признаков на основе их корреляции с целевой переменной, независимо от выбранной модели.
- Корреляция: измеряет силу линейной связи между признаком и целевой переменной. Признаки с высокой корреляцией с целевой переменной могут быть полезными для модели.
- Chi-Square тест: используется для отбора категориальных признаков. Он оценивает, насколько распределение признака отличается от того, что можно ожидать при случайном распределении.
- ANOVA (Анализ дисперсии): этот тест используется для оценки значимости различий между средними значениями категориальных переменных.
Преимущества фильтрационных методов:
- Быстрота и простота: эти методы не требуют обучения модели, что делает их очень быстрыми и простыми в применении.
- Подходят для предварительного отбора: фильтрационные методы могут использоваться как первый шаг для сокращения набора признаков перед использованием более сложных методов.
2. Методы Wrapper (обёртки)
Методы обёртки используют модель для оценки производительности разных подмножеств признаков. Это позволяет учитывать взаимодействие между признаками и их влияние на целевую переменную.
- Рекурсивное исключение признаков (RFE, Recursive Feature Elimination): на каждом шаге метод удаляет наименее значимые признаки, пока не останутся только наиболее значимые. Метод использует модель для оценки значимости признаков на каждом этапе.
- Метод поиска по подмножествам (Sequential Feature Selection): метод поочерёдно добавляет или удаляет признаки из модели и оценивает производительность модели на каждом шаге. Это позволяет найти подмножество признаков, которое даёт наилучшие результаты.
Преимущества методов обёртки:
- Учитывают взаимодействие признаков: они оценивают комбинации признаков, что помогает лучше понять их совместное влияние на модель.
- Высокая точность: благодаря учёту взаимодействий признаки отбираются более тщательно.
Недостатки:
- Высокая вычислительная сложность: методы обёртки требуют многократного обучения модели, что может быть медленным и ресурсоёмким для больших наборов данных.
3. Методы на основе встроенных моделей (Embedded Methods)
Эти методы встроены в процесс обучения модели и автоматически отбирают признаки во время оптимизации модели. Примеры таких методов включают:
- L1-регуляризация (Lasso): как обсуждалось ранее, L1-регуляризация может занулять коэффициенты незначимых признаков, что позволяет автоматически исключать их из модели.
- Random Forest: алгоритм случайного леса может оценивать важность признаков на основе того, насколько сильно они влияют на точность предсказаний дерева решений. Признаки с низкой значимостью могут быть исключены.
Преимущества встроенных методов:
- Эффективность: признаки отбираются автоматически во время обучения, что экономит время.
- Высокая точность: методы встроены в модель, что позволяет учитывать взаимодействия и влияние признаков на целевую переменную.
Недостатки:
- Зависимость от модели: результаты зависят от конкретной модели, что может ограничить универсальность метода.
7. Деревья решений и ансамблирование
Деревья решений и методы ансамблирования — это два мощных подхода в машинном обучении, которые широко используются для решения задач классификации и регрессии. Деревья решений являются простыми и легко интерпретируемыми моделями, однако их сила значительно возрастает при использовании методов ансамблирования, которые объединяют несколько моделей для улучшения качества предсказаний. В этом разделе мы подробно рассмотрим, как работают деревья решений, их преимущества и недостатки, а также как методы ансамблирования, такие как случайный лес и градиентный бустинг, могут значительно повысить точность модели.
1. Деревья решений
Дерево решений (Decision Tree) — это алгоритм машинного обучения, который предсказывает значение целевой переменной на основе последовательности правил. Дерево решений представляет собой древовидную структуру, где каждый узел соответствует условию на один из признаков, а ветви — возможным значениям этого признака. Листья дерева представляют собой конечные предсказания (или классы, в случае классификации).
Как работает дерево решений?
- Разделение данных на основе признаков: на каждом узле дерева данные делятся на группы в зависимости от значений признаков. Например, в задаче классификации узел может разделить данные по признаку "возраст" на две группы: меньше 30 и больше 30 лет.
- Критерии разбиения: дерево решений использует различные критерии для оценки качества разбиения данных на каждом узле. Для задач классификации обычно используется критерий информационная выгода (information gain), основанный на уменьшении энтропии. Для регрессионных задач обычно используется критерий среднеквадратичная ошибка (MSE).
- Рекурсивное деление: процесс разбиения повторяется на каждом узле, пока не будут выполнены критерии остановки (например, максимальная глубина дерева или минимальное количество примеров в узле).
- Предсказание: когда данные достигают листа дерева, для них делается предсказание. В задачах классификации это может быть наиболее частый класс в листе, а в задачах регрессии — среднее значение целевой переменной для всех объектов в листе.
Преимущества деревьев решений:
- Простота интерпретации: дерево решений легко визуализировать и интерпретировать. Каждое условие в дереве отражает конкретное правило, которое объясняет процесс принятия решений.
- Работа с разными типами данных: деревья решений могут обрабатывать как числовые, так и категориальные данные.
- Не требуется масштабирование данных: деревья решений не чувствительны к масштабам признаков, поэтому их не нужно нормализовать или стандартизировать.
Недостатки деревьев решений:
- Склонность к переобучению: деревья решений могут строить слишком сложные модели, запоминающие шумы данных, что приводит к плохой обобщающей способности. Чем глубже дерево, тем больше вероятность переобучения.
- Нестабильность: небольшие изменения в данных могут привести к построению совершенно разных деревьев.
- Ограниченная предсказательная способность: одиночные деревья решений часто показывают худшую точность по сравнению с более сложными моделями, особенно при сложных данных с высоким уровнем шума.
2. Ансамблирование
Ансамблирование (Ensemble Methods) — это метод, при котором несколько моделей объединяются для улучшения общей производительности. Идея ансамблирования заключается в том, что комбинация нескольких моделей может давать более надёжные предсказания, чем одиночная модель. Существует несколько подходов к ансамблированию, наиболее известные из которых — бэггинг и бустинг.
Основные методы ансамблирования:
1. Бэггинг (Bagging)
Бэггинг (Bootstrap Aggregating) — это метод ансамблирования, который использует несколько базовых моделей, обученных на разных подвыборках данных, и усредняет их предсказания. Основная цель бэггинга — снизить разброс (variance) модели и, тем самым, уменьшить вероятность переобучения.
- Процесс бэггинга:Из исходного набора данных с возвращением случайным образом создаются несколько подвыборок (bootstrap).
Для каждой подвыборки обучается отдельная модель (например, дерево решений).
Результирующее предсказание получается путём усреднения (для регрессии) или голосования (для классификации) предсказаний всех моделей.
Пример: Случайный лес (Random Forest)
Случайный лес — это наиболее известный пример применения бэггинга с деревьями решений. В случайном лесу на каждом шаге разбиения узла используется только случайная подвыборка признаков, что снижает корреляцию между деревьями и улучшает общую производительность ансамбля.
Преимущества бэггинга и случайного леса:
- Снижение переобучения: за счёт усреднения предсказаний нескольких моделей, случайный лес меньше подвержен переобучению, чем одиночные деревья решений.
- Устойчивость к шумам: ансамбль деревьев решений даёт более стабильные предсказания даже при наличии выбросов и шумов в данных.
Недостатки:
- Большие вычислительные затраты: случайный лес требует обучения большого числа деревьев, что увеличивает время обучения и объём используемой памяти.
- Меньшая интерпретируемость: хотя каждое отдельное дерево решений легко интерпретировать, случайный лес как ансамбль моделей становится гораздо менее интерпретируемым.
2. Бустинг (Boosting)
Бустинг (Boosting) — это метод ансамблирования, который последовательно обучает несколько слабых моделей (обычно деревья решений), где каждая последующая модель пытается исправить ошибки предыдущей. В отличие от бэггинга, бустинг направлен на снижение смещения (bias) модели.
- Процесс бустинга:Начальная модель обучается на всех данных.
На каждом следующем шаге модель обучается на тех данных, которые были предсказаны неправильно предыдущими моделями. Таким образом, каждая последующая модель делает акцент на исправление ошибок предыдущих.
Финальное предсказание представляет собой взвешенную сумму всех слабых моделей.
Пример: Градиентный бустинг (Gradient Boosting)
Градиентный бустинг — это наиболее популярный алгоритм бустинга, в котором каждая следующая модель обучается на остатках (ошибках) предыдущих моделей. Градиентный бустинг широко используется в соревнованиях по машинному обучению и в реальных приложениях благодаря своей высокой точности.
Преимущества бустинга:
- Высокая точность: бустинг, особенно градиентный, может значительно улучшить точность модели по сравнению с одиночными моделями и бэггингом.
- Работа с несбалансированными данными: за счёт акцентирования внимания на ошибках, бустинг может хорошо справляться с несбалансированными наборами данных, где одна из категорий доминирует.
Недостатки:
- Склонность к переобучению: если количество шагов бустинга слишком велико, модель может переобучиться на обучающих данных, особенно если данные содержат шумы.
- Большие вычислительные затраты: бустинг требует многократного обучения моделей, что увеличивает время и объём вычислений.
3. Stacking (Стекинг)
Стекинг (Stacking) — это метод ансамблирования, при котором несколько разных моделей (например, дерево решений, логистическая регрессия и случайный лес) объединяются в мета-модель. Метамодель обучается на предсказаниях базовых моделей и делает финальные предсказания.
Преимущества стекинга:
- Гибкость: стекинг позволяет комбинировать модели с разными архитектурами, что может улучшить качество предсказаний.
- Высокая производительность: стекинг часто даёт лучшие результаты, чем использование одной модели или даже ансамбля одинаковых моделей.
Недостатки:
- Сложность реализации: стекинг требует тщательной настройки, а также может быть сложным для интерпретации.
- Высокие вычислительные затраты: использование нескольких моделей и их объединение требует больших ресурсов.
8. Метрики оценки качества модели
Метрики оценки качества модели являются важной частью машинного обучения, так как они позволяют измерить, насколько хорошо модель справляется с задачей предсказания. Выбор правильной метрики зависит от типа задачи (регрессия или классификация) и особенностей данных. В этом разделе мы подробно рассмотрим ключевые метрики для оценки качества моделей в задачах классификации и регрессии, а также обсудим такие важные аспекты, как проблема переобучения и выбор метрик для несбалансированных данных.
1. Метрики для задач классификации
В задачах классификации необходимо оценить, насколько точно модель предсказывает классы объектов. Существует несколько популярных метрик для оценки производительности моделей классификации, каждая из которых используется в зависимости от специфики задачи.
1.1 Accuracy (Точность)
Accuracy (Точность) — это доля правильно классифицированных объектов среди всех объектов. Это самая простая и распространённая метрика, особенно в задачах с примерно одинаковым количеством объектов каждого класса.
Формула для вычисления точности:
Где:
Преимущества:
- Простота расчёта: метрика легко вычисляется и интерпретируется.
- Подходит для задач с равными классами: если классы примерно сбалансированы, accuracy даёт хорошую оценку модели.
Недостатки:
- Неприменима для несбалансированных данных: если один класс сильно преобладает над другим, accuracy может быть очень высокой, даже если модель плохо классифицирует объекты меньшего класса. Например, если 95% объектов относятся к классу 0, модель, которая всегда предсказывает класс 0, будет иметь точность 95%, но будет бесполезной для предсказания класса 1.
1.2 Precision (Точность предсказаний)
Precision (Точность предсказаний) — это доля правильно предсказанных положительных объектов среди всех объектов, которые модель классифицировала как положительные.
Формула для вычисления precision:
Преимущества:
- Подходит для задач, где критичны ложные срабатывания: если задача подразумевает, что ложные положительные предсказания недопустимы (например, обнаружение мошенничества), precision становится важной метрикой.
Недостатки:
- Игнорирует ложные отрицательные: precision не учитывает объекты, которые были ошибочно классифицированы как отрицательные, что может быть критично в некоторых задачах.
1.3 Recall (Полнота)
Recall (Полнота) — это доля правильно классифицированных положительных объектов среди всех фактических положительных объектов.
Формула для вычисления recall:
Преимущества:
- Полезна в задачах, где важно минимизировать ложные отрицательные: например, при выявлении заболеваний важно обнаружить всех больных (максимизировать полноту), даже если это приводит к увеличению ложных срабатываний.
Недостатки:
- Не учитывает ложные положительные: модель с высоким recall может выдавать много ложных положительных, что может быть неприемлемо в некоторых задачах.
1.4 F1-Score
F1-Score — это гармоническое среднее precision и recall. Эта метрика используется, когда нужно найти баланс между precision и recall, особенно в случаях, когда классы несбалансированы.
Формула для вычисления F1-Score:
Преимущества:
- Балансирует precision и recall: F1-Score особенно полезна, когда нужно одновременно учитывать и ложные положительные, и ложные отрицательные предсказания.
Недостатки:
- Может скрывать детали: поскольку F1-Score объединяет две метрики, иногда полезно также рассмотреть precision и recall по отдельности, чтобы глубже понять результаты модели.
1.5 ROC-AUC (Receiver Operating Characteristic - Area Under the Curve)
ROC-AUC — это метрика, которая измеряет способность модели различать положительные и отрицательные классы. ROC-кривая показывает зависимость между долей истинно положительных (TPR) и долей ложно положительных (FPR) предсказаний при разных порогах классификации.
- ROC-кривая: это график, где по оси X откладывается FPRFPRFPR, а по оси Y — TPRTPRTPR.
- AUC (Area Under the Curve): это площадь под ROC-кривой. Чем больше площадь, тем лучше модель различает классы.
Преимущества:
- Подходит для несбалансированных данных: ROC-AUC хорошо показывает, насколько хорошо модель различает классы, даже если они несбалансированы.
- Универсальная метрика: AUC варьируется от 0.5 (случайное угадывание) до 1 (идеальная модель), и чем выше AUC, тем лучше.
Недостатки:
- Может быть неинформативной для сильно несбалансированных классов: в очень несбалансированных задачах AUC может не показывать всей картины, и стоит использовать дополнительные метрики.
2. Метрики для задач регрессии
В задачах регрессии модель предсказывает непрерывное числовое значение, поэтому для оценки её точности используются метрики, которые измеряют разницу между предсказанными и реальными значениями.
2.1 MSE (Mean Squared Error, Среднеквадратичная ошибка)
MSE — это среднее значение квадратов разности между предсказанными и истинными значениями. MSE часто используется как функция потерь при обучении моделей регрессии.
Формула для вычисления MSE:
Где:
Преимущества:
- Чувствительна к большим ошибкам: за счёт квадратичного характера метрики, MSE акцентирует внимание на больших ошибках, что полезно для задач, где важно минимизировать крупные отклонения.
Недостатки:
- Чувствительность к выбросам: из-за возведения ошибки в квадрат MSE может сильно увеличиваться при наличии выбросов в данных.
2.2 MAE (Mean Absolute Error, Средняя абсолютная ошибка)
MAE — это среднее значение абсолютных разностей между предсказанными и истинными значениями. MAE измеряет среднюю величину ошибки предсказаний.
Формула для вычисления MAE:
Преимущества:
- Менее чувствительна к выбросам: в отличие от MSE, MAE не возводит ошибки в квадрат, поэтому выбросы меньше влияют на итоговую метрику.
Недостатки:
- Игнорирует направления ошибок: MAE не учитывает, в какую сторону ошиблась модель (вверх или вниз), что может быть полезно в некоторых задачах.
2.3 RMSE (Root Mean Squared Error, Корень среднеквадратичной ошибки)
RMSE — это квадратный корень из MSE. Эта метрика также чувствительна к крупным ошибкам, но её результаты легче интерпретировать, так как она измеряется в тех же единицах, что и предсказания.
Формула для вычисления RMSE:
Преимущества:
- Интерпретируемость: RMSE измеряется в тех же единицах, что и целевая переменная, что упрощает её понимание.
Недостатки:
- Чувствительность к выбросам: как и MSE, RMSE акцентирует внимание на больших ошибках.
2.4 R² (Коэффициент детерминации)
R² измеряет, какая доля дисперсии целевой переменной объясняется моделью. Эта метрика варьируется от 0 до 1, где 1 означает, что модель идеально объясняет все вариации в данных.
Формула для вычисления R²:
Где:
Преимущества:
- Показывает, насколько хорошо модель объясняет данные: чем ближе R² к 1, тем лучше модель справляется с предсказанием.
Недостатки:
- Может вводить в заблуждение при малом количестве данных: R² может давать высокие значения даже для переобученных моделей, особенно при использовании сложных моделей с малым количеством данных.
9. Работа с текстовыми данными: Метрики близости и наивный Байес
Работа с текстовыми данными (обработка естественного языка) играет важную роль в машинном обучении, особенно в задачах классификации текстов, анализа тональности, информационного поиска и других приложениях. В отличие от числовых данных, текстовые данные требуют особого подхода, так как они имеют высокую размерность и сложную структуру. В этом разделе мы рассмотрим методы обработки текстовых данных, такие как метрики близости и алгоритм наивного Байеса, которые помогают преобразовывать текст в формат, пригодный для машинного обучения.
1. Проблемы работы с текстовыми данными
Текстовые данные представляют собой последовательности символов, слов и предложений, которые сложно использовать в стандартных алгоритмах машинного обучения без предварительной обработки. Основные проблемы включают:
- Высокая размерность: текстовые данные обычно содержат большое количество уникальных слов, что приводит к высокой размерности пространства признаков.
- Неоднородность данных: разные слова и выражения могут иметь одинаковое значение, а одно и то же слово может использоваться в разных контекстах с разным смыслом.
- Шум: текстовые данные часто содержат шум, такой как грамматические ошибки, сокращения и нерелевантные символы, которые могут исказить результаты.
Чтобы преодолеть эти проблемы, используются различные техники предварительной обработки текста и метрики для оценки близости между текстами.
2. Метрики близости для текстовых данных
При работе с текстовыми данными важно уметь сравнивать текстовые документы друг с другом для задач классификации, кластеризации и поиска информации. Для этого используются метрики близости, которые помогают измерить схожесть или различие между текстами. Вот некоторые из наиболее распространённых методов измерения близости текстов.
2.1 Косинусная близость
Косинусная близость (cosine similarity) — это метрика, которая измеряет угол между двумя векторами в векторном пространстве. В контексте текстовых данных каждый документ представляется вектором, где каждый элемент вектора соответствует частоте или взвешенной частоте слова в документе. Косинусная близость используется для измерения схожести двух документов, независимо от их длины.
Формула для косинусной близости между двумя векторами A и B:
Где:
Преимущества косинусной близости:
- Независимость от длины документа: косинусная близость хорошо работает даже с документами разной длины, так как она измеряет угол, а не абсолютные значения частот слов.
- Простота вычисления: косинусная близость легко интерпретируется и быстро вычисляется.
Недостатки:
- Игнорирует семантику: косинусная близость не учитывает значение слов, а только их частоту, что может привести к ошибкам, если синонимы или другие лексические вариации имеют разное представление в пространстве признаков.
2.2 Евклидово расстояние
Евклидово расстояние — это ещё одна популярная метрика для измерения различий между векторами, представляющими документы. В отличие от косинусной близости, евклидово расстояние измеряет абсолютное различие между двумя векторами, что делает его более чувствительным к длине документов.
Формула для евклидова расстояния между двумя векторами A и В:
Преимущества евклидова расстояния:
- Подходит для задач с нормализованными данными: если данные нормализованы или имеют одинаковую длину, евклидово расстояние может быть полезным для измерения близости.
Недостатки:
- Чувствительность к длине документов: евклидово расстояние может не подходить для текстов разной длины, так как оно измеряет абсолютные различия, что делает его чувствительным к масштабу.
2.3 Манхэттенское расстояние
Манхэттенское расстояние (также известное как "городские кварталы" или L1-расстояние) измеряет сумму абсолютных разностей между значениями векторов. В отличие от евклидова расстояния, манхэттенское расстояние менее чувствительно к большим разностям в отдельных измерениях.
Формула для манхэттенского расстояния:
Преимущества манхэттенского расстояния:
- Менее чувствительно к выбросам: манхэттенское расстояние меньше реагирует на отдельные большие разности в значениях, чем евклидово расстояние.
Недостатки:
- Может игнорировать мелкие различия: если в текстах есть небольшие, но значимые различия, манхэттенское расстояние может их не уловить так точно, как косинусная близость или евклидово расстояние.
2.4 Якорные методы (Jaccard similarity)
Якорный индекс (Jaccard similarity) измеряет схожесть между двумя множествами, что делает его полезным для текстовых данных, когда важно учесть количество общих слов между текстами.
Формула для якорного индекса:
Где:
Преимущества Jaccard similarity:
- Простой и интуитивно понятный метод: легко интерпретировать результат как долю совпадающих слов.
Недостатки:
- Чувствительность к редким словам: если документы имеют много общих слов, но содержат редкие и значимые слова, якорный индекс может неадекватно оценить их различия.
3. Наивный Байес для классификации текста
Наивный Байес (Naive Bayes) — это простой и эффективный алгоритм для классификации текстов, который основывается на байесовской теореме и предположении о независимости признаков. Несмотря на свою простоту, наивный Байес часто показывает высокую производительность в задачах классификации текста, таких как фильтрация спама, анализ тональности и категоризация документов.
Основные принципы наивного Байеса
Наивный Байес использует байесовскую теорему для оценки вероятности того, что текст относится к определённому классу, на основе частоты слов в тексте.
Формула для вычисления вероятности того, что текст относится к классу C:
Где:
Наивное предположение
Алгоритм называется "наивным", потому что делает упрощённое предположение, что все признаки (слова в тексте) независимы друг от друга. Несмотря на то, что это предположение редко выполняется на практике, алгоритм показывает хорошие результаты.
Виды наивного Байеса
- Мультиномиальный наивный Байес: используется для классификации текстов, где признаки — это частоты или количества слов.
- Бернуллиевский наивный Байес: применяется в задачах с бинарными признаками (например, присутствует слово или нет).
Преимущества наивного Байеса:
- Быстрота и эффективность: наивный Байес очень быстро обучается и предсказывает, что делает его идеальным для работы с большими текстовыми наборами данных.
- Хорошая производительность для текстовых данных: несмотря на упрощённые предположения, наивный Байес часто превосходит более сложные алгоритмы для задач классификации текста.
Недостатки:
- Наивное предположение о независимости: на практике слова в тексте часто зависят друг от друга, и это упрощённое предположение может снизить точность модели на некоторых данных.
- Чувствительность к редким словам: если слова встречаются очень редко, они могут незначительно влиять на модель, что может быть критично для специфических доменов.
10. Алгоритмы кластеризации и улучшение качества модели
Кластеризация — это один из ключевых методов машинного обучения, который используется для разделения данных на группы (кластеры) на основе их схожести. В отличие от классификации, кластеризация относится к методам неконтролируемого обучения, то есть данные не содержат заранее известных меток классов. Цель кластеризации — группировка объектов таким образом, чтобы объекты внутри одного кластера были более похожи друг на друга, чем на объекты из других кластеров. В этом разделе мы подробно рассмотрим основные алгоритмы кластеризации, их применение, а также методы улучшения качества модели.
1. Основные алгоритмы кластеризации
Существует множество алгоритмов кластеризации, которые используют различные подходы для разделения данных на кластеры. Рассмотрим наиболее популярные методы кластеризации.
1.1 Алгоритм k-средних (k-means)
Алгоритм k-средних (k-means) — это один из самых простых и широко используемых методов кластеризации. Он разделяет данные на kkk кластеров на основе расстояния между объектами и центроидами кластеров.
Принцип работы k-means:
- Инициализация: случайным образом выбираются kkk центроидов (средних точек) кластеров.
- Назначение объектов кластерам: каждый объект данных назначается к ближайшему центроиду на основе евклидова расстояния (или другой метрики).
- Обновление центроидов: центроиды обновляются как средние значения всех объектов, назначенных каждому кластеру.
- Повторение: шаги 2 и 3 повторяются до тех пор, пока центроиды не перестанут изменяться или не будет достигнуто заданное количество итераций.
Преимущества k-means:
- Простота и скорость: k-means легко реализовать, и он быстро работает на больших наборах данных.
- Чёткие границы кластеров: каждый объект чётко назначается одному кластеру, что даёт ясное разделение.
Недостатки:
- Чувствительность к выбору k: результат алгоритма сильно зависит от выбора числа кластеров kkk, которое нужно задать заранее.
- Нестабильность: алгоритм может дать разные результаты при разных начальных положениях центроидов.
- Неподходящ для сложных кластерных структур: k-means плохо работает с данными, где кластеры имеют форму, отличную от сферической.
1.2 Алгоритм иерархической кластеризации
Иерархическая кластеризация — это метод, который строит древовидную структуру (дендрограмму) для разделения данных на кластеры. Этот подход не требует предварительного задания числа кластеров и позволяет исследовать данные на разных уровнях кластеризации.
Принцип работы:
- Агломеративная иерархическая кластеризация (снизу-вверх): начинается с того, что каждый объект считается отдельным кластером. Затем кластеры последовательно объединяются на основе их схожести, пока не останется один кластер.
- Дивизивная иерархическая кластеризация (сверху-вниз): процесс начинается с одного кластера, который содержит все объекты, и постепенно этот кластер разбивается на более мелкие, пока каждый объект не станет отдельным кластером.
Методы определения расстояния между кластерами:
- Связь по одному элементу (single linkage): минимальное расстояние между любыми двумя объектами из двух разных кластеров.
- Связь по полному элементу (complete linkage): максимальное расстояние между любыми двумя объектами из двух разных кластеров.
- Связь по среднему (average linkage): среднее расстояние между всеми парами объектов из двух разных кластеров.
Преимущества иерархической кластеризации:
- Отсутствие необходимости задавать число кластеров: в отличие от k-means, иерархическая кластеризация не требует предварительного знания числа кластеров.
- Гибкость: даёт представление о структуре данных на разных уровнях, что полезно для исследования данных.
Недостатки:
- Высокая вычислительная сложность: иерархическая кластеризация может быть медленной на больших наборах данных, так как требует вычисления расстояний между всеми парами объектов.
- Отсутствие корректировки: уже выполненные объединения или разбиения кластеров нельзя отменить, что может привести к неэффективной кластеризации.
1.3 Алгоритм DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) — это алгоритм кластеризации на основе плотности, который находит кластеры в данных, основываясь на плотности объектов в пространстве. Этот метод может эффективно выделять кластеры любой формы и размерности, а также автоматически выявлять выбросы (шум).
Принцип работы DBSCAN:
- Параметры: задаются два параметра — ε\varepsilonε (радиус поиска соседей) и минимальное количество точек MinPtsMinPtsMinPts в окрестности ε\varepsilonε.
- Плотные области: алгоритм идентифицирует плотные области данных, где существует не менее MinPtsMinPtsMinPts точек в пределах радиуса ε\varepsilonε. Эти области считаются кластерами.
- Расширение кластеров: если точка находится в плотной области, она добавляется в кластер, а её соседи также проверяются. Кластеры расширяются, пока не будут найдены все точки, принадлежащие кластеру.
- Шум: точки, которые не принадлежат никакому кластеру, считаются шумом.
Преимущества DBSCAN:
- Работа с кластерами произвольной формы: в отличие от k-means, DBSCAN хорошо справляется с кластерами произвольной формы и не требует задания числа кластеров заранее.
- Устойчивость к выбросам: DBSCAN автоматически идентифицирует выбросы как шум и не включает их в кластеры.
Недостатки:
- Чувствительность к параметрам: эффективность алгоритма сильно зависит от выбора параметров ε\varepsilonε и MinPtsMinPtsMinPts.
- Плохо работает с данными разной плотности: DBSCAN плохо разделяет кластеры, если плотность данных сильно варьируется.
1.4 Алгоритм к-средних с итеративным улучшением (k-medoids)
Алгоритм k-medoids — это вариация алгоритма k-means, где центроидами кластеров выбираются не средние значения точек, а реальные объекты данных (медоиды). Это делает алгоритм менее чувствительным к выбросам.
Преимущества k-medoids:
- Устойчивость к выбросам: так как медоиды — это реальные объекты, а не средние значения, k-medoids менее подвержен влиянию выбросов.
Недостатки:
- Сложность и медлительность: k-medoids сложнее и медленнее, чем k-means, так как требует дополнительных вычислений для выбора медоидов.
2. Метрики оценки качества кластеризации
После выполнения кластеризации важно оценить качество полученных кластеров. Существуют различные метрики для оценки того, насколько эффективно данные были разделены на кластеры.
2.1 Внутрикластерное расстояние (Within-cluster distance)
Внутрикластерное расстояние измеряет, насколько близки объекты внутри одного кластера. Оно показывает, насколько объекты одного кластера похожи друг на друга. Чем меньше это расстояние, тем лучше кластеризация.
Формула для внутрикластерного расстояния:
Где:
2.2 Межкластерное расстояние (Between-cluster distance)
Межкластерное расстояние измеряет, насколько далеко друг от друга находятся центроиды разных кластеров. Чем больше межкластерное расстояние, тем лучше разделение между кластерами.
2.3 Индекс силуэта (Silhouette score)
Индекс силуэта измеряет, насколько хорошо объекты принадлежат своему кластеру по сравнению с ближайшим другим кластером. Значение индекса варьируется от -1 до 1, где значения, близкие к 1, указывают на хорошее разделение кластеров.
- .https://macim.getcourse.ru/freestudyreg наши бесплатные уроки Переходите на наш сайт macim. ru уже сегодня, чтобы не упустить уникальные предложения, эксклюзивный контент и возможности увеличения заработка.
Присоединяйтесь к нашему вебинару. Будущее уже здесь, и нейросети помогут вам оказаться на шаг впереди, обогнать ваших конкурентов и коллег, увеличить свой заработок и свое благосостояние, и смотреть в будущее более уверенно!
И не забывайте подписываться на наши соц.сети
YouTube: https://www.youtube.com/@MACIM-AI
Телеграм: https://t.me/MACIM_AI
Чат-бот: https://t.me/ChatGPT_Mindjorney_macim_bot
Вконтакте: https://vk.ru/macim_ai
#нейросети #искусственныйинтеллект