Никак не может "утонуть" по просмотрам вот эта статья:
Которая в свою очередь была написана по мотивам статьи другого автора:
Не думал, что так получится. За всё это время набрались комментарии с различными предложениями и возражениями, поэтому сделаю второй подход с повышенной сложностью.
Подводный камень в постановке задачи
В качестве исходных данных даётся уже сформированный файл, который содержит 5000 записей. Именно от этого числа я и отталкивался при решении – какую сортировку выбрать, как размещать в памяти и прочее. Но в задаче говорится, что число записей считывается первым из файла. То есть можно подложить файл с другим числом записей, и задача всё равно должна быть решена.
Числа в файле – уникальные, натуральные, не превышающие миллиарда. Значит, максимум в файле может быть миллиард чисел. Но ровно миллиард делать не надо, потому что тогда посчитать ответ можно будет чисто аналитически, ничего не программируя. Вместо этого я выбрал число 750 миллионов, то есть 2/3 от всего количества.
Вот именно от этого мы сейчас и попляшем, чтобы проверить, как работают старые решения, и найти, если повезёт, новые.
Подготовка файла
Даже создать такой файл уже непросто. Для начала нужно как-то выбрать 750 миллионов чисел, чтобы они все были уникальные, и чтобы они были перемешаны в случайном порядке.
К примеру, в языке PHP есть функция array_shuffle(), которая перемешивает массив. Если создать массив из элементов 1, 2, 3, ... и так до миллиарда, а затем перемешать его, то потом можно взять из него первые 750 миллионов элементов и записать в файл.
Так я и сделал, но... программе на PHP не хватило памяти. Придётся писать на C.
Сначала надо выделить память под миллиард 32-битных чисел (константа COUNT = 1000000000), и заполнить значениями от 1 до COUNT:

На это нужно 4 гигабайта памяти.
Перемешивание массива происходит так: пройти по каждому элементу и поменять его местами со случайно выбранным другим элементом.
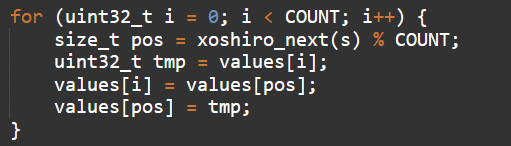
Функция rand() в языке C выдаёт диапазон значений от 0 до константы RAND_MAX, которая обычно равна 32767. Если мы попытаемся этот диапазон натянуть на миллиард элементов, большая часть из них просто никогда не поменяется. Поэтому здесь используется функция xoshiro_next(), которая использует алгоритм xoshiro и выдаёт значения в 32-битном диапазоне.
После того как массив перемешан, первые 750 миллионов элементов (константа N) пишем в файл:
И не забываем в самом начале файла записать значение N :)
Вся эта процедура занимает несколько минут, но генерация нужна только один раз, поэтому сойдёт.
В результате получился файл размером почти 8 гигабайт:
Испытание на прочность
Так как условия задачи соблюдены, я могу сразу же скормить этот файл первой версии своей программы. По крайней мере, она запустилась и работает...
Напомню, что задача описана по ссылкам, приведённым выше, и для её решения нужно провести сортировку всех чисел.
Я сделал вывод прогресса отсортированных (ещё даже не проверенных, а только отсортированных!) чисел, и судя по этому прогрессу, программа минут за 15 обработала 2 миллиона чисел (напомню, что расчёт был на 5000). Дальше сортировка будет квадратично замедляться, как и положено пузырьку, и даже в самом оптимистичном варианте время окончания составило бы не менее 90 часов. Чего я ждать не стал.
На смену пузырьку со словами "подержи мой стек" заступила функция qsort(), и дело сразу пошло веселей. Сортировка отработала за 3 минуты.
Далее нужно перебрать пары чисел, и внутри этого перебора должен быть ещё бинарный поиск среднего.
Чтобы не тратить время зря, я сделал тест пустого цикла перебора пар, в котором просто прибавляются счётчики:
Он идёт до половины диапазона, так как по условию задачи проверяются только чётные числа, которые у меня сложены отдельно, и чётных будет в среднем половина.
Пустой цикл накрутил около 5000 в час по внешней переменной i, и осталось наприседать наповторять таким образом всего лишь 374995000 раз. Поэтому можно сразу ставить крест на любых вариантах, где фигурирует такой перебор.
Способы поиска
Если данные содержат и исходные значения, и результаты, то поиск соответствия между значениями и результатами можно делать двумя способами.
- Прямой: перебирать все значения, вычислять результат, и затем искать результат.
- Обратный: каждое значение считать уже результатом и для него находить возможные исходные значения.
В зависимости от соотношения количества подходящих значений и результатов и от того, что конкретно требуется найти, поиск может оказаться короче в одном из вариантов.
Текущее решение использует прямой поиск, где перебираются пары и ищется среднее для них. Перебор пар имеет квадратичную сложность и изменить это нельзя.
Замечание в комментариях:
Пусть каждое число это уже среднее. Тогда можно найти такие числа, из которых получается это среднее. Если это число N, то оно получится из следующих пар: (N-1, N+1), (N-2, N+2) и т.д.
Как видим, для каждого числа N нужно будет перебрать до N/2 возможных пар, так что квадратичная зависимость сохраняется и здесь и поэтому никак не оптимизирует задачу.
Но ради эксперимента напишем программу.
Приведу интересующую часть кода:
Суть в том, чтобы перебирать каждое число в массиве и пытаться найти два числа слева и справа от него, которые составили бы пару. Пара получится, когда левое число меньше на N, а правое больше на N, чем среднее. Таким образом, мы берём начальные позиции pos_left и pos_right слева и справа от числа, и двигаем эти позиции в разные стороны, пока одна из них не упрётся в край массива. По пути мы пропускаем все нечётные числа. Если число слева даёт разницу меньше, чем справа (diff_left < diff_right), то двигаем только левую позицию, увеличивая разницу. Аналогично для правого числа.
В итоге программа работает быстро, но... для исходных 5000 чисел. Как только нужно посчитать 750 миллионов, прогнозы становятся всё такими же неутешительными.
Словари и множества
Часто упоминались структуры вроде множеств, словарей или отображений:
Сразу отмечу, что замена массива чисел на хэш-таблицу из миллиарда элементов не поможет, вернее поможет лишь для автосортировки и быстрого поиска значения. Но перебор пар в количестве N*N/2 всё равно никуда не девается, а именно в нём главная проблема.
Вариант с bit-array рассматривать не будем, так как у него из достоинств только экономия памяти, а раз памяти пока хватает, сделаем просто массив из 1 миллиарда байтов и будем в нём отмечать, какие элементы есть. Затем применим поиск пар от среднего, как в предыдущем варианте.
Таким образом мы действительно избавились от сортировки, но... Теперь 5000 чисел обрабатываются целых 25 минут! Что случилось?
Случилось страшное: теперь вместо 5000 чисел мы вынуждены перебирать весь миллиард, потому что 5000 чисел очень-очень редко распределены где-то внутри этого миллиарда.
Если чисел будет очень много, то решение будет оправданно, но выгод не принесёт. Хотите делайте перебором пар, хотите – перебором средних значений, но никуда от квадратичной сложности вы не денетесь, и поэтому данное решение, во-первых, ни от чего не спасает, а во-вторых, на малом количестве элементов ведёт себя значительно ХУЖЕ, чем мы могли бы ожидать.
Если использовать хэшмап/словарь/множество, то там не будут храниться пустые значения. Но тогда возникнет проблема с перебором пар внутри коллекции. Это будет итератор, в котором мы не можем назначить стартовый индекс, значит ключи коллекции надо будет получить в отдельный массив и бегать по нему отдельно, то есть это всё равно что... обычный массив. Ну и в конце концов, сам перебор никуда не денется.
Вот, к примеру, комментарий:
И вот та самая программа на Питоне:
И там очевидно есть перебор всех элементов в двух вложенных циклах (i, j).
Всё плохо?
Пожалуй да, с моей точки зрения всё плохо. Попробуем установить предел, до которого решение работает хотя бы с натяжкой. Посмотрим, сколько элементов можно обработать за полчаса тем или иным способом.
- Сортировка пузырьком с перебором пар + бинарный поиск: 330000
- Сортировка qsort с перебором пар + бинарный поиск: 330000
- Cортировка пузырьком с перебором средних: 570000
- Сортировка qsort с перебором средних: 600000
- Перебор пар без сортировки + поиск в хэш-таблице: Миллион!
- Хэш-таблица на миллиард с перебором пар: 5400
- Хэш-таблица на миллиард с перебором средних: 6000
Сортировка пузырьком для 330000 чисел была медленнее, чем quicksort, но не настолько, чтобы заметно повлиять на общее время. Перебор средних на массиве работает почти в 2 раза быстрее, чем перебор пар, так как перебирать внутренний цикл нужно не до N, а до N/2 максимум, но это различие всё равно станет несущественным при увеличении N.
Наконец, перебор пар в сочетании с поиском среднего по хэш-таблице работает быстрее бинарного поиска и в общем зачёте быстрее всех, но требует лишней памяти, так как хранится и массив чисел, и хэш-таблица с этими же числами, которая нужна только для поиска.
Попробуем запустить программу на Питоне на 750 миллионах чисел... она не смогла даже прочитать файл, выдав MemoryError. На миллионе чисел завелась, но через полтора часа пришлось остановить ввиду явного проигрыша. На 200 тысячах чисел получилось 40 минут. Ну, вот такая цена за "5 строчек вся программа".
Что делать для больших количеств?
Думаю, надо применять аналитические методы. К примеру, чем больше чисел присутствует в заданном пространстве, тем большее количество непрерывных цепочек они будут образовывать. А непрерывные цепочки можно посчитать аналитически, типа каждое N-е число там это среднее от (N-1, N+1). Но я в это пока не лез, ибо мне такое трудно даётся.
Можно применять многопоточную обработку на вычислительном кластере :) Но это как был метод грубой силы, так и остаётся.
Если у вас есть другое решение, буду рад его узнать!