Недавно на курсах, студенты попросили рассказать про использование кэшей и с удивлением обнаружил о том, что теоретическая или может академическая информация по проектированию системной архитектуры или архитектуры решений над сервисами не так и много. В данной статье попробовал собрать все знания, которые есть у меня на тему составления стратегии кэширования.
Про то, каким бывает кэш можно почитать тут:
Но основные примеры в этой статье будут относится к использованию кэша в back-end решениях в процессах обработки и передачи данных.
Начнем с назначения кэша.
- Повышение доступности данных.
- Повышение производительности при доступе к данным.
- Улучшение пользовательского опыта.
- Экономия ресурсов.
Чаще всего под кэшем понимают хранение данных в памяти для быстрого доступа к ним. Детали реализации подобных решений, разберем ниже. Из определения понятно, что кэш не подразумевает собственного персистентного хранилища и нужно помнить, что описанные выше задачи могут решаться иными способами, например с использованием колончатых СУБД, различных паттернов информационного взаимодействия и архитектурных решений. Использование кэширования в сложных решениях дает значительные выгоды, но так же несет в себе значительные риски.
Стратегия кэширования - артефакт производственного процесса определяющий:
- Состав и приняты развития (изменения) структуры кэшируемых данных.
- Принципы взаимодействия компонентов системы и/или решения в рамках процессов кэширования.
- Правила инвалидации данных кэша.
- Границы когерентности.
- Требования к согласованности данных в рамках технической реализации, а так же бизнес- процессов.
- Метрики качества работы кэширующих компонентов и сервисов.
- Процедуры прогрева и DR.
- Риски и ограничения, включая риски при потери когерентности кэша или данных в нем находящимся.
Стратегия кэширования не какой-то объемный бюрократический документ, это может быть статьей в вики, фиксирующей дата-модели и какие-то максимально важные определения из списка выше. Зачем стратегия может потребоваться, есть два паттерна:
1. Вы реализуете что-то схожее с NRT(Near Real Time) контекстом: быстро собираете, агрегатируете данные и отдаете их условно не ограниченному кругу потребителей. В таком случае, ожидания и паттерны использования вашего сервиса у потребителей могут превосходить ваши возможности. Как пример из банковской сферы, данные для отображения в клиентских приложениях брались из кэша, при этом когерентность кэша не гарантировалась. Часть потребителей начали использовать кэширующий сервис как интеграционный слой, что привело к существенным проблемам из-за конечного расхождения данных.
2. Данные в кэше по своей модели очень сильно отличаются от данных в основном хранилище. Как минимум, это точно приведет к раздельному пути эволюционного развития. Отказ от формирования правил работы с моделью очень быстро приведет к высоким, хотя и не явным, накладным расходам, например: на развитие правил трансформации, агрегации и сбора данных для кэша.
Метрики кэша.
Маленькая лирическая вставка:
Считается, что есть два поколения архитектурных подходов. Первые: на основе данных, вторые: на основе комплексных паттернов. Так вот почти все, что касается кэша - это прежде всего проектирование на основе данных.
Естественно, основной метрикой кэша является процент попадания - Hit rate. Процент данных извлечённых из кэша. Чем он ближе к 100% тем лучше, но это не точно, вернее точно в 99% случаев.
Так же принято выделять технические и специфические метрики.
Технические:
- RPS - чем меньше время ответа, тем лучше.
- Объем памяти/ресурсов
Специфические:
- Expired rate - процент удаленных записей по истечению TTL.
- Eviction rate - процент записей вытесненных из кэша по достижению порога памяти.
Чем объемнее и сложнее кэширующее решение, тем сложнее диагностирование проблем и сложнее устранение последствий .И как любое решение, решение содержавшие кэш, развивается, участвует в новых функциях и само обрастает новым функционалом. Для понимания состояния архитектуры и решения в целом, имеет смысл задуматься о динамических фитнес-функциях.
Например, если мы обогащаем какой-нибудь долгоживущий кэш по паттерну Transactional outbox, то рост данных в таблицу outbox в отношении с общим числом актуальных потребляемых записей в кэше говорит о степени снижения когерентности.
Общие схемы реализации кэша.
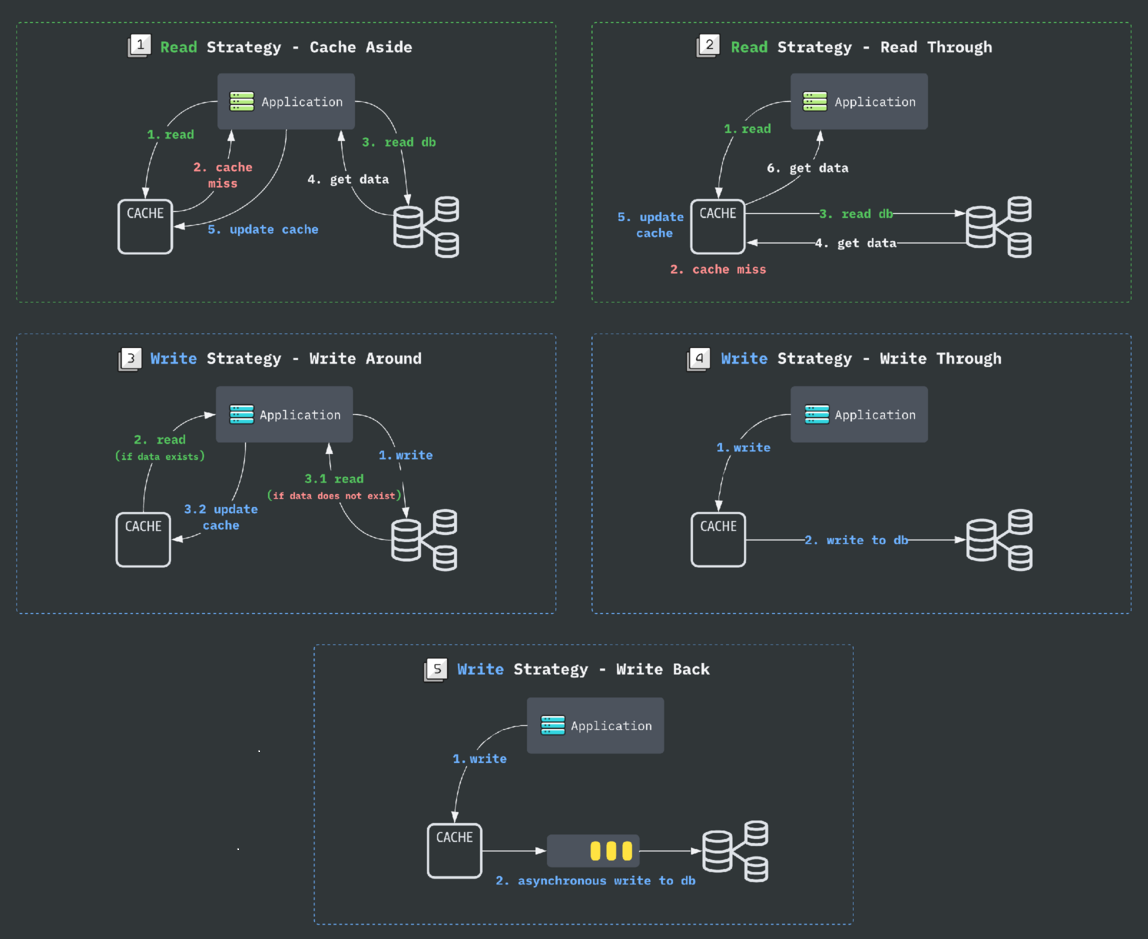
На текущей момент есть пять общепринятых схем реализации кэша:
Cache-Aside - Кэш в стороне.
Плюсы: Более гибкая модель данных, возможно отличсная от базы
Минусы: риск рассинхронизации данных. Данные согласуются с задержкой.
Read-Through - подробное чтение, кэш находится между приложением и базой. Если данных кэше нет - данные перечитываются из базы.
Плюсы: Архитектура проще и надежнее, так как используется модель данных базы.
Минусы: Увеличение нагрузки на БД. Согласованность данных между базой и кэшем сложна в реализации.
Write-Through - Сквозная запись - данные пишутся в кэш и в базу одновременно. Но в рамках одной транзакции.
Плюсы: Согласованность данных.
Минусы: Требования к координации между базой и кэшем. Операция записи медленнее.
Write-Back Обратная запись - Сначала пишутся в кэш, потом в базу с задержкой.
Плюсы: Сокращает количество операций записи.
Минусы: Риск потери данных. Возможная неконсистентность данных.
Write-Around Обходной путь. Данные пишутся только в базу, а читаются только из кэша. данные обновляются редко, считываются чаще.
Плюсы: Повышение производительности прилажухи. Предотвращает загрязнение кэша.
Минусы: Протухание кэша.
Некоторые правила проектирования агрегатов - дата-модели кэша.
При проектировании дата-модели кэша, естественно, если вы выбрали вариант с раздельными моделями в хранилище и в кэше, стоит акцентировать внимание на требования к когерентности кэша. По умолчанию в какой-то момент времени данные в кэше не соответствуют данным в хранилище.
Важно помнить, что такие платформы, как например tarantool позволяют хранить данные в разных квази-таблицах и объединять их при запросе. Имеет смысл избегать реляционных структур в связи с рисками утраты когерентности и сложностью с инвалидацией.
Правила вытеснения.
Предположим наш кэш ограничен по ресурсам и мы можем хранить только какое-то ограниченное количество однотипных записей. Тогда нам надо вытеснять условно старые данные новыми. Как это можно сделать?
Random.
Как-то часто все забывают, что такой вариант вообще есть. Когда мы рандомно выбираем и замещаем запись. Как бы такой метод не казался глупым, он вполне себе рабочий и применимый, например в случаях негомогенности структур данных(метаданных) кэша.
FIFO/LIFO
Логика очевидная из название - замещения выпихивание более старого или более нового. Очень хорошо рабочий вариант, если вы знаете, что у вас потребление(hit rate) у новых записей больше, чем у старых, то почему бы не использовать FIFO?
LRU (Least Reacently Used)
Вытесняется элемент к которому дольше всего не было обращений. В отличии от LFU метрика для вытеснения - время.
MRU (Most Recently Used)
Крайне специфичный кейс, мы вытесняем элемент к которому было последнее обращение. Понятно что работает, в случае когда вы точно знаете, что данные из кэша вам понадобятся не более чем один раз.
LFU (Least-Frequently Used)
Вытеснение по количеству обращений. Для каждого элемента подсчитывается количество обращений и вытесняем мы тот, который наименее часто был использован. Хорошо подходит для кэша с гомогенизированной метамоделью, в комбинации с инвалиджацией по времени или в случае с долгоживущим кэшом, например - контент на лэндингах.
Более продвинутые правила вытеснения:
Алгоритм Белади (OPT)
Предположим мы можем предположить (lol), когда к нашим данным может произойти обращение. В таком случае вытеснить мы можем те данные, к которым пользователь обратиться через наибольшее время.
В теории, подчеркну, в теории можно использовать в различных транзакционных системах и решениях, где транзакции обслуживаются многомерным кэшом в стейт-машинах. На практике крайне сложно реализуемый алгоритм.
Ну и для меня в целом, не понятно, зачем вообще его реализовывать, при любой реализации, кажется, что алгоритм повышает связанность в системе или решении.
Second Chance
У нас есть FIFO, проблема в том, что у нас в FIFO может быть элемент, у которого хит-рейт максимальный, а мы его все равно должны вытеснить. Что делаем:
- Добавляем флаг чтения к записи
- Если элемент прочитан, то устанавливаем флаг
- Перемещаем элемент в конец очереди
- Снимаем флаг
Clock
По идеи то же что и Second Chance. Если правильно помню, то по такой логике swap в linux работает. Все то же самое, только у нас не очередь, а некое кольцо по которому в одном направлении движется некая стрелка. При установке флага мы ни куда не двигаем элемент. Но вытеснение по той же логике как и в SC.
2Q (две очереди)
У вас есть две очереди FIFO и LRU, при вытеснении из второй очереди данные попадают в LRU, при вытеснении из первой - попадают во вторую.
Сложно? А то!
Разделим данные на горячие и теплые. При этом мы знаем, что первые обращения к горячим данным у нас будут активными, но с гэпом времени данные попадут в теплую зону. Для реализации этого гэпа времени им есть первая очередь.
Пример - лента в соц. сети и посты. Поначалу посты в горячей зоне, затем они становятся теплыми, пока не будут вытеснены с течением времени.
SLRU (Сегментированный LRU)
У нас есть три типа кэша: горячий, теплый и условно холодный, все работают по LRU.
При первом обращении перекладываем из холодного в теплый, при повторном с теплого - в горячий.
TLRU (Time Aware LRU)
Добавляем TTL к элементам кэша. При достижении некоего промежутка времени, элемент из кэша вытесняется безусловно.
LRU-K
Постраничное вытеснение. Объединяем данные в страницы и мерим количество обращений к ним.
LRU-2
Мерим не по первому, а по второму обращению к данным. Примером может вялятся маркетинговое продвижение, первый заход - лэндос, второй - пререндеринг заявки на кредит..
Инвалидация данных.
Нужно не дать кэшу протухнуть - максимально исключить снижение когерентности выраженное в наличии в кэше не актуальных данных. Для этой цели служит процесс инвалидации. Кроме того, чем меньше мусорных - не потребляемых записей в кэше, тем быстрее кэш отдает данные и тем выше метрика попадания.
Какие есть правила инвалидации:
Инвалидация по сроку жизни агрегата. По истечению срока жизни данные удаляются из памяти. Полезно устанавливать срок жизни при использовании любого другого правила инвалидации. Использование этого правила может быть дополнительным страховочным механизмом. Данное правило просто к реализации и вполне себе эффективно для данных, которые не меняются часто.
И тут немного про Jitter.
Возможна ситуация, куогда у вас, например, заканчивается срок жизни маркетинговой акции и идет переоценка товара, тогда мимо кэша в базу пойдет большое количество запросов, от чего базе наверняка поплохеет.
Jitter - случайная величина добавляемая к TTL
Аннулирование по ключу. Правило, в соответствии с которым, при поступлении нового значения или явного указания на инвалидацию соответствующего ключа, данные обновляются. Может выполнятся прямым запросом от сервиса-хранилища. Кроме того, могут быть вариации с мгновенным обновлением или инвалидацией с последующей обработкой запроса на данные сервером и обновлением кэша, что может существенно сэкономить ресурсы при плавающем значением метрики попадания в кэш.
Аннулирование при сквозной записи. Приложение ждет когда произойдет запись в хранилище, затем обновляет данные в кэше. Таким образом актуальность данных в кэше максимально возможная. Но такой подход снижает скорость работы приложения, так как приложение должно дождаться записи в хранилище.
Инвалидация через бан. В сторону кэширующего сервиса выполняется запрос, все данные удовлетворяющие критерию запроса немедленно удаляются. Досочно эффективный механизм инвалидацйии, но в то же время весьма сложный в реализации.
Обновление кэша при повторной проверке. Данные отдаются из кэша всегда, если они там есть, но при соблюдении установленных критериев, на сервер-хранилище отправляется запрос о корректности данных, если они не корректны кэш обновляется и данные передаются клиенту повторно.
Еще раз напомню, что стопроцентная когерентность мало того, что не достижима, но и не является самоцелью. Операция инвалидации, особенно инвалидации с обогащением - одни из самых дорогих, снизить стоимость использования кэша возможно, например за счет реализации паттернов слабой согласованности данных, например Eventually Consistent или вариаций на его тему.
Немного про Thundering Herd problema
Предположим, что мы инвалидировали данные, например по TTL и вдруг почему-то к этим данные происходит резкий рост обращений, то что происходит: клиенты ломятся в кэш, не получают оттуда данные, ломятся в базу и пытаются записать в кэш, например. Плохо кэшу, плохо базе. Что делать? Вспоминать про согласованность в конечном счете применительно к кэшу или лочить запись (мьютексы).
Инвалидирование и версионирование. Предположим, у нас есть картинка в кэше ivon v.1, нам надо инвалидировать данные, мы меняем картинку icon v.1 на icon v.2 такой картинки в кэше нет, мы ее перечитаем и положим в кэш.
То же самое относительно данных. Можно управлять кэшом через конфигурацию сервиса, когда к данным добавляется версия сервиса.
Прогрев кэша.
И тут приходит неожиданная проблема. Очень часто история с кэширующими сервисами начинается ни как история про реализацию функционала в отдельном сервисе, а как история про облегчение жизни БД. Типа, мы ставим между сервисом-хранилищем и фасадом кэш и кэш снимет часть нагрузки с БД. Упадет кэш-нечего страшного, прогреется как-то, ведь без него с болью, но работало же. по этому и DRP мы разрабатывать не будем и думать на этот счет тоже.
Так вот, часто наблюдаю картину, когда кэш, чаще всего, падает или теряется когерентность и кэш у нас пуст. При попытке штатного прогрева кэша (наполнения его данными), хранилище начинает давать отказы по производительности и вместо медленного прогрева система перестает работать вообще.
К чему этот весь спич - на этапе проектирования даже не исходя из прогнозов по росту нагрузки, стоит предусмотреть инструменты и регламент восстановления кэша до приемлемого работоспособного состояния. Ну и конечно стоит наблюдать за этим "приемлемым работоспособном состоянием" - обложить кэш метриками по попаданию запросов и проценту перенесенных данных.
Персистентное хранилище
Многие платформенные решения, такие как Tarantool или Ignite дают возможность дублировать данные в персистентном хранилище - хранить на диске.
Это, и хорошо ,и плохо одновременно.
Плюсы:
- Вы можете составлять гораздо более сложные агрегаты и снизить требования к актуальности данных.
- Прогрев кэша происходит очень быстро.
- Из коробки это значит, что вы можете строить федерации с стопроцентным соответствием данных в инстансах.
А минус один. Если вы не эльф-архитектор 80 lvl то падение кэша вы заметите не сразу и процесс записи в хранилище у вас может не остановиться, что приведет к потере когерентности системы на совершенно не очевидный процент.
Можно с этим как-то бороться? Конечно можно. Сложный путь - метрика когерентности. Простой путь - DRP подразумевающий постепенную актуализацию кэша в фоне после восстановления по всему объему данных.