Сегодняшняя публикация будет длиннее обычной (примерно вдвое) из-за того, что мы впервые попытаемся разобрать не просто идею, но сконструировать (в самых общих чертах, конечно) схему параллельного вычислителя (и обсудить достоинства/недостатки предложенной конструкции).
Итак, пришло время, базируясь на общих положениях согласно рис. 6, попробовать сконструировать наиболее общую схемы параллельной вычислительной системы (один из вариантов её - рис. 7).
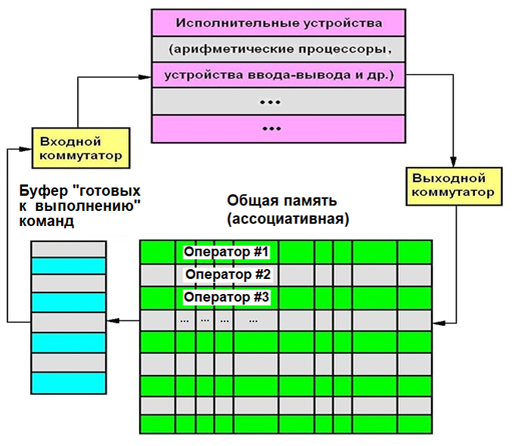
Как видно из рис. 7, предложенная схема (фактически архитектура вычислительной системы) представляет собой циклическую структуру, движение данных в которой совершается по часовой стрелке. Аналогом “облака операторов” может послужить общая память (показанная на рис. 7 в виде горизонтальных строк, каждая из которых содержит один оператор); сами же операторы в этой памяти не отсортированы нико́им образом. Эта общая память доступна по записи со стороны выходного коммутатора и по чтению со стороны входного коммутатора. Один из “столпов” компьютерных технологий Всеволод Бурцев назвал такую вычислительную систему суперпроцессором. Такой суперпроцессор может параллельно выполнять не только один алгоритм (программу), но и множество программ (многозадачный режим).
Названия коммутаторов “входной/выходной” назначены относительно поля параллельных вычислителей; расширенно согласно работы того же Всеволода Бурцева будем именовать их исполнительными устройствами, ибо среди них могут встречаться не только Арифметические Исполнительные Устройства (АИУ), но и устройства связи с внешними частями вычислительной системы – блоками ввода/вывода и др.
В такой вычислительной системе важным условием начала выполнением операторов является не условие окончания выполнения предыдущего по последовательному списку оператора, а условие Готовности К Выполнению (ГКВ) любого из операторов программы. Этот приём является, конечно, более общим относительно постулатов фон Неймана, однако реализация его технически затруднена (фон Нейман, конечно, прекрасно понимал существование указанной возможности, однако состояние технологий того времени практически однозначно “привело к тому, к чему привело” – был реализован вариант с последовательной выборкой и выполнением операторов).
Т.к. при корректной конфигурации облака операторов можно говорить об отсутствии программы (в её явном написании) и (с известной долей скепсиса) утверждать, что выполнение программы управляется не программой (концепция Control-Flow, как у фон Неймана), а самими данными (концепция Data-Flow)! Пожалуй, в деле разработки и пропаганды концепции Data-Flow следует отдать приоритет Джеку Деннису (MIT - Massachusetts Institute of Technology, старт работ относится к началу 70-х гг. XX века - см., напр., здесь).
В силу известных недостатков (см., напр., формулу (1) и пояснения в публикации #003) мелкогранулярного параллелизма (IPL-уровень машинных команд) была предпринята попытка разработки т.н. LGDF-вычислительной системы (Large Grain Data-Flow), в которой используются гранулы параллелизма значительно бо́льшего размера.
● Из известных проектов вычислительных систем архитектуры Data-Flow можно упомянуть JUMBO (Университет на Тайне, Великобртания), Manchester Dataflow Computer (MTI, USA), проекты Monsoon и Epsilon (США), CSRO (Австралия).
● В Институте Прикладной Математики им. М.В.Келдыша РАН (Россия) разработан язык DCF (Data-Control Flow) для реализации принципа Data-Flow, основанный на принципе реализации взаимодействия нитей (thread) в многоядерных процессорах и механизма то́кенов (динамическая модель Data-Flow).
Входной коммутатор (ВхК) осуществляет автоматическое динамическое распределение вычислительных ресурсов, назначая один из поля вычислителей для выполнения конкретного ГКВ-оператора:
- Сигналом начала цикла работы ВхК является момент освобождения от выполнения вычислений любого из поля АИУ.
- Далее ВхК проверяет условие существования ГКВ-операторов в буфере операторов.
- Если в буфере есть операторы, они (в порядке, заданном правилами вы́борки) пересылаются на свободный АИУ для выполнения.
- Процесс повторяется до момента выполнения всех операторов программы.
Выходной коммутатор (ВыхК) обеспечивает работу с общей памятью вычислительной системы:
- Сигналом начала цикла работы ВыхК является окончание выполнения оператора на любом из АИУ (с получением результата выполнения Result).
- Далее ВыхК подставляет значение Result во все поля операндов c тем же именем (адресом) для операций, находящихся в общей памяти вычислителя.
- Если среди операторов найдётся такой, у которого все операнды разрешены́ (т.е. имеют не случайное, а определённое предыдущими действиями состояние), они добавляются в буфер ГКВ-операторов.
И чисто формально вышеприведённая схема вполне работоспособна. Однако давно и хорошо известно, что “враг рода человеческого” скрывается в деталях. Да, тот самый, показанный в форме максвелловского демона на рис. 7 (публикация #007) ! Проблема - каким образом среди общего пула операторов программы определить ГКВ?
Простейший вариант – прямым (последовательным) перебором. При каждом сравнении (а их при последовательных сравнениях в среднем требуется половина от общего числа строк) коммутатор ВыхК проверяет, соответствует ли адрес результата выполнения на поле АИУ очередного оператора адресу первого и/или второго операндов каждого оператора пула команд и, если равенство найдено, устанавливает соответствующий бит готовности операндов. При времени последовательного считывания данных из общей памяти ≈10^(-9) сек (наносекунда, нсек) и числе сравниваемых элементов 10^9 имеем оценку времени поиска данных ≈1 сек! И это при времени выполнения каждой машинной команды порядка 1 нсек… Это значит, что в среднем примерно 500'000'000 единиц времени вычислительная система ищет нужные данные, а 1 единицу времени выполняет собственно вычисления… кошмар!
Кстати, а почему при последовательном сравнении в среднем требуется число сравнений, равное половине от общего числа сравниваемых элементов?
Ясно, что проблема состоит в способе доступа к данным, характерном для памяти с произвольным доступом (RAM – Random Access Memory), допускающей поиск в массиве данных исключительно последовательным образом (ведь конкретного адрес расположения нужных данных априори неизвестен!). Известные методы ускорения доступа (двоичный поиск, хеширование) требуют значительных вычислительных ресурсов (и времени!) для реализации.
Ассоциативная память в Data-Flow вычислительной системе
Близким к идеальному решением проблемы является применение ассоциативной памяти (безадресной памяти, реализующей одномоментное сравнение входных данных со всеми элементам памяти). Ассоциативная память успешно используется в качестве сверхбыстродействующей кэш-памяти, однако выпускается ограниченного объёма - проблему одновременного срабатывания миллиардов компараторов (устройств сравнения) напрямую решить затруднительно, а обходные решения снижают быстродействие ассоциативной памяти.
Принцип Out-Of-Order Execution в P6 (Pentium Pro)
В результате массовое применения параллельных вычислителей, основанных на идеях потоковой архитектуры (хотя известны проекты), “не случилось” (причина та же – излишние накладные расходы – в первую очередь на работу с ГКВ-операторами), однако собственно идея нашла применение в микропроцессорах общего назначения начиная с P6 (Pentium Pro фирмы Intel Corp., 1995) при реализации блока обработки спекулятивных выборок машинных команд (объёма порядка 2^5=32 штук); соответствующий блок процессора получил название DE (Dispatche/Execute Unit, устройство диспетчирования и выполнения команд) и функционирует в соответствие с принципом Out-Of-Order Execution (внеочередное исполнение, исполнение в порядке ГКВ).
Несмотря на сказанное, потоковый вычислитель является превосходным инструментом для исследования свойств алгоритмов, причём обычно представляющееся недостатком свойство таких вычислительных систем (требование однократного присваивания результатов вычислений в статической потоковой архитектуре) становится положительным свойством (позволяет подробнейшим образом анализировать историю изменения всех обрабатываемых данных).
С некоторыми ограничениями можно считать, что показанное на рис. 7 устройство относится к классу граф-машин – вычислительных устройств, максимальным образом имитирующих выполнение действий над графами как над сообществом вершин (предст́авленных операторами) и дуг (предста́вленных линиями передачи информации).
Эмоционально говоря, удивительным является вопрос - по какой причине подобная вышеприведённой схема вычислительной системы не явилась первой из исторически реализованных (классической фон Неймановский вычислитель представляется немно́гим сложнее по схеме, чем рассматриваемый!). Однако такое мнение слишком напоминает хорошо знакомое изречение из известного фильма “…словно в Истории работала банда двоечников!”. Исследователям пришлось пройти долгим и тяжёлым путём познания, совершить множество ошибок и реализовать ряд успешных проектов, чтобы осмыслить недостатки классической архитектуры и пройти дальше в конструировании неклассических схем вычислителей.
Я вот думаю, что фон Нейман никогда бы не смог даже высказать “работающую” идею своего компьютера, приняв за базовую концепцию Data-Flow машины! Похоже, он был немалым тактиком – выбирал наиболее реализуемые (при данном уровне технологий) ходы. А что думаете по этому поводу Вы?