Выдающимся свойством алгоритмов является возможность представле́ния их в виде гра́фов. Представив алгоритм графом, мы получаем мощнейший инструмент анализа в виде теории графов, позволяющий манипулировать графами практически неограниченно. Пожалуй, ни одного практически зна́чимого вывода мы не смогли бы сделать без использования графов (и ро́дственной теории)..!
Наконец-то ГРа́ФЫ…
Давайте построим граф, соответствующий алгоритму решения полного квадратного уравнения (впервые это решение дано великим индийским астрономом и математиком БРАХМАГУПТА (7-й век н.э.). Само уравнение представлено ниже, нужно найти его корни (значения х, при которых уравнение обращается в ноль):
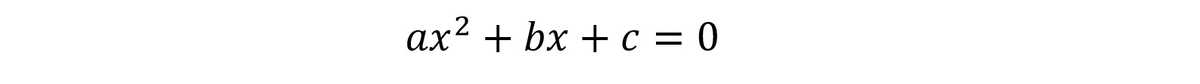
Корней, как известно, имеется два (ниже обозначены как x1 и x2):
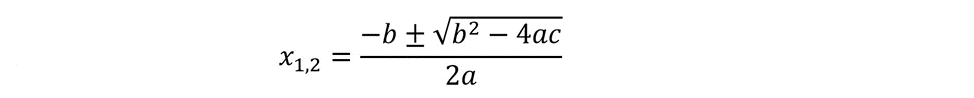
Первым делом перечислим все арифметические действия, необходимые для получения решения по этой формуле :
Исходные данные тут a,b,c (коэффициенты уравнения) и 4, 2 и -1 (константы, использующиеся при решении), выходные данные обозначены root_1 и root_2 (это и есть корни уравнения).
Всего операций получилось 11. Автор сознательно начал нумерацию с номера 100 для показа незна́чимости этого действа, ибо главное здесь – зафиксировать за определённым оператором конкретный номер (именно по нему мы и будем в дальнейшем идентифицировать оператор).
Заметим, что операция 106 заключается в вычислении квадратного корня, а его значение определено только для положительных значений. При p_sqr≥0 имеем два вещественных корня (при p_sqr=0 они одинаковые), при p_sqr≤0 корни имеют мнимую компоненту.
Такой граф называется информационным (ибо главное при его построении – информационные причинно-следственные зависимости); иногда будем называть его ИГА (Информационный Граф Алгоритма). По анализу причинно-следственных (какой оператор от какого/каких - зависит по информационным зависимостям) связей между операторами построен граф рис. 8. Взаимное расположение вершин (операторов) графа на плоскости абсолютно произвольно (автор рис. 8 руководствовался наименьшей высотой) – важно, чтобы вершин было не менее двух и они соединялись между собой информационными связями. На самом деле не нужно “на глазок” находить эти связи (всё равно “вручную” это зачасту́ю можно сделать лишь в простейших случаях) – всё без особого труда совершается на программном уровне.
Заметим, что в описании алгоритма графом присутствуют только операторы, изменяющие данные, и на́прочь отсутствуют операторы второстепенные (напр., управление памятью и др.; они могут быть учтены при необходимости), это позволяет сосредоточить анализ на управлении обработкой данных. В этом и заключается одно из основных отли́чий алгоритма от программы (согласно которому последняя была построена).
Граф на рис. 8 является напра́вленным (все ду́ги – соединяющие "кружочки" – вершины графа) линии имеют стрелку только на одном конце (что фактически является следствием направления течения времени) и ациклическим (граф не имеет петель - циклов).
Ну вот перед нами ИГА (Информационный Граф Алгоритма). Первая (основная) задача – выявить собственно параллелизм в графе.
● Что-ж… Нет проблем – воспользуемся вышеописанным (публикация #008, рис. 7) методом выборки “подходящих” операторов из “облака операторов”. Процедура последовательного перебора неэффективная без применения ассоциативной памяти, но кое-как “с горем пополам” реша́емая с учётом кэширования etc. Осталось поставить фильтр по свойствам операторов (по условию "готовности к выполнению", длительности выполнения и самого оператора и линий передачи данных и т.д. и т.п. – можно даже статистически учесть диапазоны изменения этих величин - сложность фильтра не ограничиваем). Такая система будет работоспособна, конечно (вопросы эффективности её пока не рассматриваем).
● А можно ли использовать определённые особенности графа и упростить процесс получения информацию о наличии (скрытого – т.е. невидимого невооружённым взглядом) параллелизма в нём?..
Заметим, что (как указывалось ранее) часть информации при представле́нии алгоритма графом не была использована. Отсутствует информация о временны́х параметрах (данные “беру́тся” непонятно откуда и неясно куда записываются – а ведь на эти действия требуется время; длительность выполнения машинных команд также не определена). Без учёта параметров времени трудно говорить об адекватном моделировании. В системе SPF (см. публикацию #013) с целью уточнения модели введены параметры (ме́ры) для вершин графа (операторов, расширение файлов *.mvr) и дуг (информационных связей, расширение *.med) и API-вызовы для их обработки (подробнее см. файл API_User.pdf); эти параметры могут интерпретироваться, в частности, как длительности выполнения соответствующих операций. Т.к. эти ме́ры относятся к параметрам исполняющей системы (а не к АЛГОРИТМУ !), подобное разделе́ние логически оправдано.
- Один из самых простых (но изящных) методов – построение (специальных) сечений (информационного) графа. Это относительно несложная (математическая) процедура, заключающаяся в делении графа на т.н. ярусы параллелизма. Наша цель – представить граф в виде, удобном для анализа на параллелизм (естественно, нико́им образом не изменяя сам граф) – мы просто изображаем граф в ином виде (форме). Основная идея (фильтрация) остаётся неизменной, однако фильтр ставится по одному параметру – по причинно-следственной связи между операндами и операторами.
Страшная штука под названием ЯПФ
Нижеприведена процедура разбиения графа на сечения таким образом, что каждое содержит операторы, мо́гущие выполняться одновременно (т.е. параллельно). Примем, что входные данные алгоритма располагаются на ярусе с номером 0 и будем строить сечения графа, нумеруя их последовательно начиная с 1; полученную форму графа будем называть ЯПФ (Ярусно-Параллельной Форма).
- Найти среди всех вершин графа (операторов, причём в данном случае под операторами можно понимать гранулы параллелизма любого размера) такие, у которых нет вход́ящих дуг. Помещаем их на ярус номер 0 (это будет ярус исходных данных ЯПФ).
- Среди оставшихся операторов найти такие, которые по дугам (информационным зависимостям) зависят только от операторов, размещённым на предыдущих ярусах. Найденные операторы поместим на следующий после предыдущего ярус.
- Если у всех операторов на последнем созданном ярусе не имеется выходящих дуг, считаем построение ЯПФ завершённым; в противном случае повторяем пункт 2).
Здесь важным понятием является фильтр генерации сечений графа (в данном случае он определён слове́сно как “зависят только от операторов, размещённым на предыдущих ярусах”, нет проблем определить его и строго математически). Это фактически наиболее простой фильтр. Фильтр может быть иным (более сложным); тогда ярусов получится больше (обычно).
Если при этом все входные вершины расположены на начальном ярусе, ЯПФ называют канонической (каноническая ЯПФ является единственной для заданного графа).
Заранее неизвестно, сколько ярусов в ЯПФ ока́жется (для знатоков сообщу, что это число определяется величиной критического пути в графе). Получим ЯПФ информационного графа, все вершины (операторы) в которой расположены на ярусах, максимально прибли́женных к началу выполнения алгоритма (“верхняя” ЯПФ); можно строить ЯПФ с конца (начиная с выходных данных) – тогда в ЯПФ все операторы будут находиться на ярусах с наименьшими номерами (“нижняя” ЯПФ). В обоих случаях вычислительная сложность процедуры разбиения оценивается O(N^2), где N – число вершин (операторов) в графe (при анализе для каждой вершины графа просматриваются все остальные вершины).
Фактически описанный алгоритм является примером алгоритмов обхо́да графов в ширину (Breadth-First Search, BFS) - на каждом его шаге находятся (по принципу принадле́жности ГКВ) вершины, составляющие кайму́ (по́лосу вершин, примыкающих непосредственно к уже обрабо́танной части графа); именно вследствие постепенного (ша́гового) распространения каймы критический путь является маршрутом максимальной длины. В кайме должно быть не менее одного оператора – иначе процесс выявле́ния ярусов параллелизма с помощью ЯПФ-процедуры следует заверши́ть.
“Готовый” ЯПФ, полученный согласно вышеприведённой процедуры, показан на рис. 9 (в данном случае показана “верхняя” ЯПФ). Всего получилось 6 ярусов ЯПФ. Принято называть высотой ЯПФ число ярусов в ней, а шириной ЯПФ – максимум число операторов по ярусам (в данном случае 4).
А кстати – необходимо ли получать все яруса ЯПФ сразу? Почему бы не получить сначала первый ярус (и тут же “распараллелить” его – т.е. распределить на заданное число параллельных вычислителей)?.. и так далее до конца алгоритма. Заметим, что именно так поступают (в целях упрощения) в большинстве распараллеливающих компиляторов. Результат при этом будет вполне рабочий, однако хуже, чем вариант получения полного ЯПФ… Почему? Да просто потому, что в случае получения полного ЯПФ (всех его ярусов) появляется возможность анализировать параметры (в первую очередь, ширину каждого яруса – т.е. форму огибающей) ЯПФ с целью выбора наилучшего метода целенаправленных преобразований его же! Напр., невозможно использовать метафору BULLDOZER (см. публикацию #015) – для определения направления движения необходимо “видеть”, куда движемся. В общем случае при получении полного ЯПФ имеется возможность “взгляда сверху” с просто́ром для лучшей ориентации в сложившейся ситуации и, в конечном итоге, выявле́ния бо́льшего потенциала параллелизма в ИГА.
- Близкие методы исследований применял (конечно, много глубже, чем автор в своей работе) в своё время акад. Валентин Воеводин. Им предложена т.н. “теорема об информационном покрытии” (о формулировках здесь и тут), примени́мая к линейному классу программ. Решается всё тот же (чисто практический, кстати!) вопрос – предсказать, каким образом изменяются параметры (параллельной) вычислительной сложности алгоритмов при изменении их параметров (напр., максимальных значений индексов в индексных выражениях - а это определяет степень дискретизации при решении задач сеточными методами)? В зависимости от ответа определяется, какую вычислительную систему необходимо использовать для решения данной задачи (или наоборот - какой сложности задачу можно решить на данной системе). Может быть, уважаемым Читателям (когда-нибудь в будущем) удастся доказать эту теорему?..
По результатам работ академика была разработана программная система V-Ray, направленная на анализ исходных кодов программ с циклами (в самом деле, “Вычислительная трудоёмкость скрывается в циклах!”).
Суммируя сказанное, можно утверждать, что для каждого конкретного алгоритма ЯПФ, построенная на основе его информационно графа в условиях неограниченного параллелизма, обладает определёнными параметрами:
1. Характеризуется минимальной высотой, количественно определяемой числом вершин (операторов), находящихся на критическом пути графа.
2. Все возможные значения ширин ярусов ЯПФ располагаются между ЯПФ в “верхнем” и “нижним” её вариантах.
Но, как гова́ривал великий Энтони Хоар, “В каждой большой программе живет маленькая программа, которая пытается выбраться наружу”. Перефрази́руя высказывание, можно сказать, что “из этого что-то следует”… а именно – возможность целенаправленно выбора рациональной (по заданным критериям) конфигурации ЯПФ. Но до этого мы ещё “дойти” должны!..
Позвольте слова два сказать?.. Только что мы (преде́рзко!) заявили Миру, что “распараллелили определённый алгоритм, получив в режиме неограниченного параллелизма ЯПФ с высотой 6 и шириной 4”. На самом деле необходимо было уточнить, что ЯПФ была построена при размере гранул параллелизма равным машинным командам (приблизительно считаем их равными арифметическим выражениям, это соответствует идеологами ILP – Instruction-Level Paralleliыm). Это автор к тому говорит, что при иных размерах гранул параллелизма результаты могут быть совсем иными!
● Вообще-то для наилучшей реализации параллелизма с разными размерами гранул используются вычислительные системы различной архитектуры. До сих пор неясно, какой размер гранул можно считать оптимальным (пожалуй, это следствие разнообразия сущности “алгоритм”).
● Обычно по мере возрастания размеров гранул параллелизма (а их – по времени выполнения – стараются выбирать примерно одинаковыми) сложность процесса выявления гранул возрастает (кроме вы́рожденных случаев – когда размер гранул приближается к размеру всей программы). А как думают Читатели – почему возрастает..? А почему стараются выбирать размер гранул примерно одинаковым?..
Кстати, а что делать при возникновении критической ситуации при вычислениях (программного или аппаратного прерыва́ния)? Обработка прерываний стандартная – совершаются преопределённые прерыванием действия (на иных параллельных вычислителях таковы́е могут и продолжаться – до момента произведения операций, связанных с негото́вностью по операндам; здесь придётся использовать некие семафоры, сигнализирующие о возникновение подобной ситуации).
Мы что-то "распараллелили"… обсудим результат?
Мы получили ЯПФ информационного графа алгоритма в виде ярусов, расположенные на которых операторы обладают свойском выполняться параллельно. Это превосходно для первоначальной визуализации потенциала параллелизма – высок он или “не очень”. Отрицательным свойством ЯПФ является как казавшееся положительным его свойство – расположение всех операторов “в линеечку” (по ярусам) – ведь из этого следует, что стартовать все они должны одновременно (и, честно говоря, заканчиваться тоже). Но полное время выполнения операторов неодинаково (даже при равном времени выполнения самого оператора) - напр., один из них обращался за своими операндами к внутренним регистрам процессора, второй – в кэш память, а третий – вообще в оперативную память. Относительная разница по времени между этими обращениями часто составляет несколько сотен раз!
Недостатком выявления параллелизма в ИГА методом построения ЯПФ является как раз желательность (а в идеале – обязательность по условию получения максимума временно́й плотности кода) одинаковости по времени выполнения гранул параллелизма (более точно – постоянства в пределах каждого яруса). Принципиальная ограниченность в достижи́мости максимальной плотности кода является серьёзным недостатком ЯПФ-подхода (что несколько сглаживается в некоторых специальных случаях - напр., при использовании для расчётов в случае процессоров со сверхдлинным машинным словом).
На рис. 10 показаны разные варианты моментов синхронизации выполнения операторов (длительность выполнения которых условно показана высотой красных столбиков). На рис. 10 a) разные варианты синхронизации, а на рис. 10 b) – синхронизация старта операторов по единому моменту (условно - времени “наступления момента яруса”). Для процессоров со сверхдлинным командным словом вариант 10 b) подходит идеально (в самом деле – все отдельные машинные команды в слоте сверхдлинного слова априори стартуют совместно), в большинстве иных случаев – нет. Нельзя требовать излишнего от математической процедуры получения ЯПФ – мы требовали только учёта причинно-следственных закономерностей (в виде однонаправленных информационных связей – “стрелочек”) и ничего больше. “Из ничего не выйдет ничего!” – гова́ривал король Лир.
Т.о. за рассматриваемым методом получения ЯПФ следует оставить лишь грубую, предварительную оценку потенциала параллелизма в алгоритме (преимуществом его является лишь невысокая – квадратичная – оценка вычислительной трудоёмкости этого приёма).
Ясное дело – имеются (ну не может же не быть!) и иные способы выявления параллелизма по графу алгоритма. А какие именно Вы можете предложить (крепко подумав предварительно)?
Рекомендую ознакомиться с книгой Ильи Федотова – там имеется достаточно внемлемое перечисление приёмов выявления в алгоритмах скрытого потенциала параллелизма.
Опять “забыли про овраги”..!
У любого представления программы в форме алгоритма имеется не очень удобная особенность, заключающаяся в проблемах описания усло́вности выполнения отдельных блоков программы. Хотя пособники современного стиля оформления программ вовсю критикуют конструкции “if/else”, в любом языке программирования высокого уровня эти конструкции имеются (и никакой разумный разработчик от них отказываться не собирается). Как поступить при разработке алгоритма? Ведь каждое условие формально потребует построения нового, отличного от предыдущих, информационного графа (и его ЯПФ, разумеется)! Число их (особенно, если условные переходы совершаются по значению “плавающих” переменных) трудноизмеримо… Разве можно анализировать каждый?
Классическим методом реализации условности выполнения частей программы является применение т.н. “регистра-счётчика команд“, однако при наличии нескольких параллельно работающих вычислителей его использование затруднительно.
На самом деле, решение давно известно и даже успешно применяется в процессорах архитектуры ARM (Advanced RISC Machine, иногда Acorn RISC Machine, фирма ) и Itanium (Intel Corp.). Заключается оно в использовании т.н. предикатов (двоичных переменных, в зависимости от значения “истина” или “ложь” которых данный оператор (машинная команда) выполняется или не выполнятся); сам предикат также вычисля́ем. В Itanium’е имеется 64 доступных каждому из параллельных вычислителей аппаратных двоичных регистров для помещения в них предикатов, в программном пакете ПРАКТИКУМ DF (см. публикацию #010) эти регистры предста́влены программно (переменные-предикаты обрабатываются трёхсимвольными инструкциями с именами, начинающимися с символа ‘P’ на латинице).
В Itanium’е, например, реализован режим спекулятивного выполнения (команда на конвейере физически выполняется, однако результат её выполнения в процессорных регистрах не сохраняется); это частично удлиняет работу программы, но сохраняет беспроблемным режим работы конвейера.
- “Побочным эффектом” применения техники предикатов является ненужность предсказа́ния переходов (программа фактически становится линейной) в программах (кстати, требующая немалых схемотехнических ресурсов процессора).
Использование предикатов фактически равносильно добавлению дополнительного операнда каждому оператору, что позволяет избежать мультивариантности ИГА (и его ЯПФ, естественно).
Как Вам “на вкус” идея использования предикатов? Оправдано ли её применение? Больше пользы или вреда приносит она?
Авторские ресурсы:
Информация о канале вообще и его оглавление…
- В работе мы будем использовать специализированное авторское программное обеспечение (фактически исследовательские инструменты), предназначенное для выявления в произвольных алгоритмах параллелизма и его рационального использования при вычислениях.
В.М.Баканов. Практический анализ алгоритмов и эффективность параллельных вычислений. ISBN 978-5-98604-911-3. 2023. LitRes.ru