DeepSeek-R1 — это модель искусственного интеллекта, разработанная китайской компанией DeepSeek, которая выделяется своими выдающимися способностями к рассуждению. Её обучение началось с версии DeepSeek-R1-Zero, которая была обучена исключительно с помощью подкрепляющего обучения (далее - RL) без предварительной настройки под наблюдением. Это позволило модели развить способности к самооценке и многократному размышлению, но возникли проблемы, такие как плохая читаемость и смешение языков.

Чтобы решить эти проблемы, была создана DeepSeek-R1, которая включает данные "холодного старта". Эти данные — это начальные примеры цепочек рассуждений, сгенерированные предыдущей моделью DeepSeek-V3, которые использовались для настройки под наблюдением перед применением RL. Этот многоэтапный процесс включал генерацию данных, настройку под наблюдением и последующее RL, что улучшило как способности к рассуждению, так и читаемость.
Производительность и сравнения
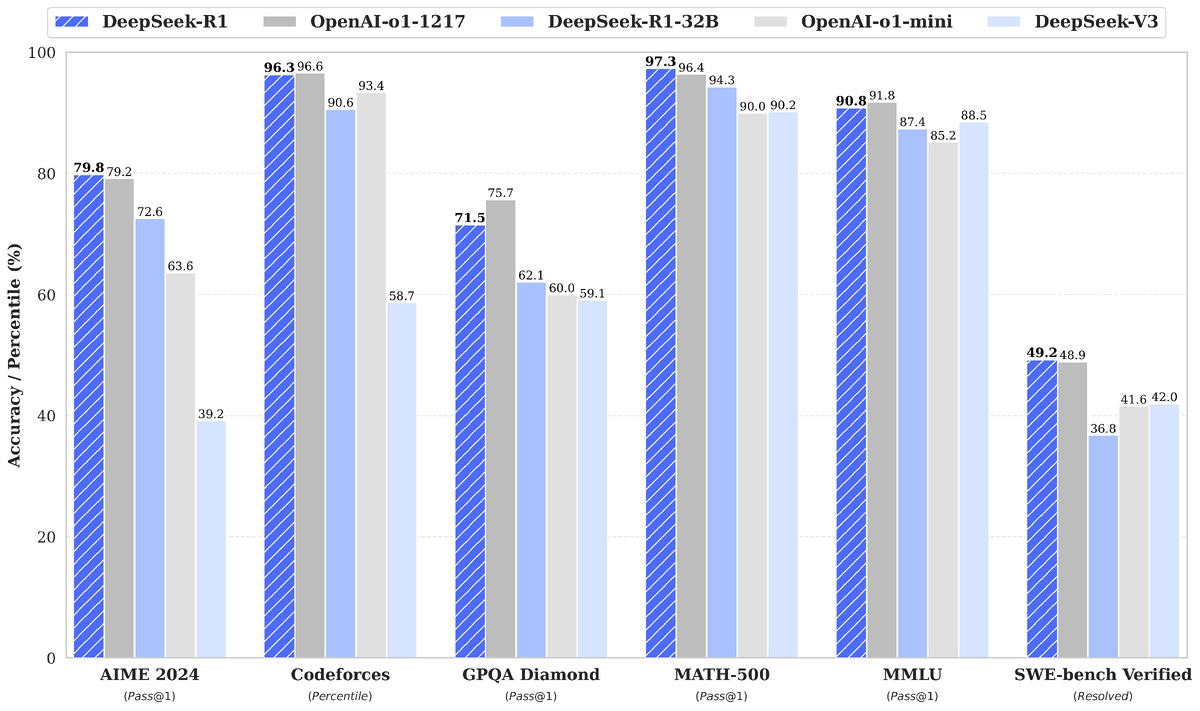
DeepSeek-R1 показывает впечатляющие результаты в различных тестах. Например, она достигла 97,3% точности в тесте MATH-500, что немного лучше, чем 96,4% у OpenAI o1-1217. В задачах программирования, таких как Codeforces, её рейтинг составил 2029, что близко к 2061 у o1-1217. В тестах на рассуждения, таких как AIME 2024, она набрала 79,8%, немного опередив o1-1217 с 79,2%.
Кроме того, DeepSeek выпустила уменьшенные версии модели (от 1,5B до 70B параметров), которые также показывают конкурентоспособные результаты, что делает ИИ-доступными для более широкой аудитории.
Экспертные мнения
Исследователи ИИ отмечают, что метод обучения DeepSeek-R1 представляет значительный прогресс. "Одним из самых впечатляющих аспектов DeepSeek-R1 является её способность соответствовать или превосходить производительность закрытых моделей, таких как o1, при этом будучи открытой и доступной для сообщества", — говорит доктор Эмили Ван, ведущий исследователь в области ИИ. Открытость модели способствует сотрудничеству и ускоряет развитие ИИ.
Подробный анализ обучения DeepSeek-R1 и её революционного подхода
DeepSeek-R1, разработанная китайской компанией DeepSeek, стала заметным событием в мире текстовых моделей ИИ, особенно благодаря своим выдающимся способностям к рассуждению, которые соперничают с моделью OpenAI o1. Эта статья подробно исследует процесс её обучения, анализирует, что делает её революционной, и рассматривает её производительность в сравнении с другими ведущими моделями.
Контекст и предыстория
DeepSeek-R1 — это первая генерация моделей рассуждений, представленная DeepSeek, и она включает две ключевые версии: DeepSeek-R1-Zero и DeepSeek-R1. DeepSeek-R1-Zero была обучена исключительно с помощью крупномасштабного подкрепляющего обучения (RL) без предварительной настройки под наблюдением (SFT), что было необычным подходом. Это позволило модели продемонстрировать замечательные способности к рассуждению, включая самооценку и многократное размышление, что редко встречается в традиционных моделях. Однако у DeepSeek-R1-Zero были проблемы, такие как бесконечное повторение, плохая читаемость и смешение языков, что ограничивало её практическое применение.
Чтобы решить эти проблемы, была разработана DeepSeek-R1, которая включает данные "холодного старта" перед применением RL. Эти данные, как выяснилось, представляют собой примеры цепочек рассуждений, сгенерированные моделью DeepSeek-V3, которые использовались для настройки под наблюдением, чтобы обеспечить более прочную основу перед RL. Этот подход был описан в техническом отчёте, доступном на GitHub DeepSeek-R1.
Процесс обучения: Подробности
Обучение DeepSeek-R1 включало многоэтапный процесс, который можно разбить на следующие этапы:
- Генерация данных "холодного старта": DeepSeek-V3 использовалась для создания тысяч примеров цепочек рассуждений (CoT), что обеспечило начальную базу для обучения. Это было описано в статье на Medium, где подчёркивается, что такие данные значительно улучшают производительность модели.
- Настройка под наблюдением (SFT): Эти данные использовались для тонкой настройки модели, что помогло улучшить читаемость и избежать смешения языков, как указано на Hugging Face.
- Подкрепляющее обучение (RL): После SFT применялось RL для дальнейшего улучшения способностей к рассуждению, фокусируясь на точности и эффективности решения задач. Это позволило модели достичь производительности, сравнимой с OpenAI o1, как показано в DeepInfra.
Этот подход контрастирует с традиционными методами, где модели обычно проходят предварительное обучение на больших текстовых корпусах, за которым следует SFT. Использование чистого RL для DeepSeek-R1-Zero было революционным, так как оно показало, что RL может развивать способности к рассуждению без SFT, хотя и с ограничениями. Добавление данных "холодного старта" в DeepSeek-R1 решило эти проблемы, что делает её подход уникальным.
Производительность: Сравнение с другими моделями
DeepSeek-R1 была протестирована на различных бенчмарках, и её результаты впечатляют. Ниже приведена таблица с ключевыми метриками, сравнивающими DeepSeek-R1 с другими моделями, такими как OpenAI o1 и GPT-4o, основываясь на данных с Hugging Face:
Заключение
DeepSeek-R1 представляет собой значительный шаг вперёд в обучении моделей ИИ, сочетая подкрепляющее обучение с данными "холодного старта" для достижения выдающихся результатов. Её открытый характер и конкурентоспособная производительность делают её важным вкладом в развитие ИИ, потенциально влияя на будущие модели и ускоряя инновации в сообществе.