Рассмотрим возможности создания искусственных наборов данных с заданными свойствами для задач классификации. Как и датасеты для кластеризации их можно получить специальной функцией библиотеки Scikit-learn - make_classification.
Она имеет следующие параметры:
n_samples - количество точек данных;
n_classes - количество классов;
n_features - число признаков разных типов, количество каждого из которых задается параметрами:
n_informative - информативные,
n_redundant - производные (линейные комбинации информативных),
n_repeated - повторяющиеся.
Соответственно, бесполезных признаков - n_features-n_informative-n_redundant-n_repeated.
n_clusters_per_class - число кластеров, на который разбит каждый из классов точек.
Эти кластера, распределены по области значений информативных признаков. Они задают независимые скопления точек и привносят определенную долю шума.
class_sep - управляет длиной каждой из сторон кластера (равна 2*class_sep). Чем она больше, тем сильнее кластера отделяются;
weights - задает пропорции классов, чтобы вносить несбалансированность;
flip_y - доля точек, для которой класс задается случайно, вносит шум в данные;
random_state - инициализатор счетчика случайных чисел для воспроизводимости эксперимента;
shift - задает сдвиги в значениях признаков;
scale - определяет мультипликатор для признаков;
shuffle - опция перемешивания, при этом не только точек, но и порядка признаков, иначе они идут в последовательности - n_informative, n_redundant, n_repeated.
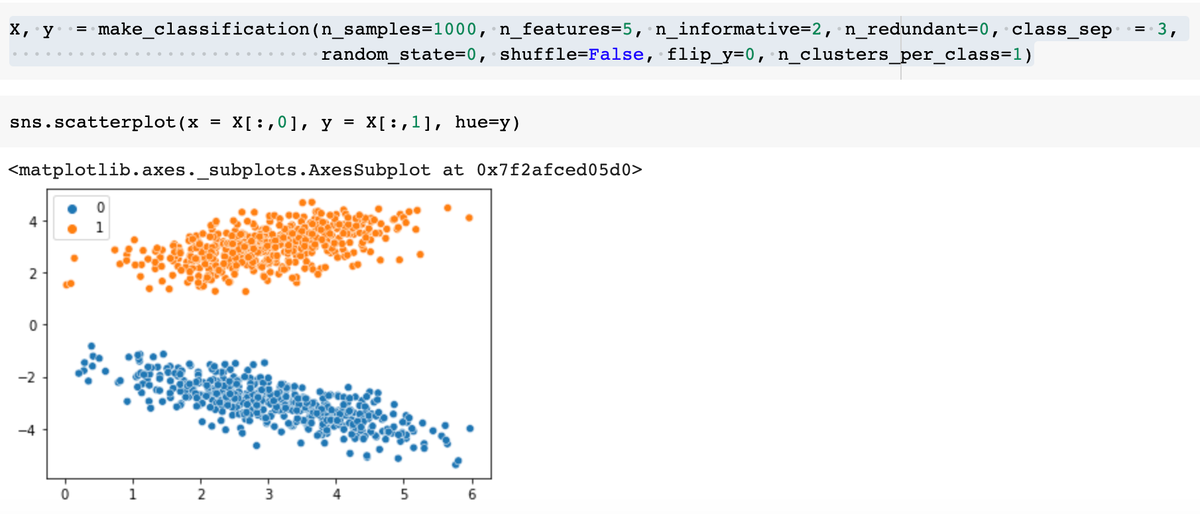
Из всего перечисленного самое сложное - это параметры, связанные с кластерами. Визуализируем взаимное распределение информативных координат точек для двух классов при разном количестве кластеров - 2 и 1:
если кластера 2:
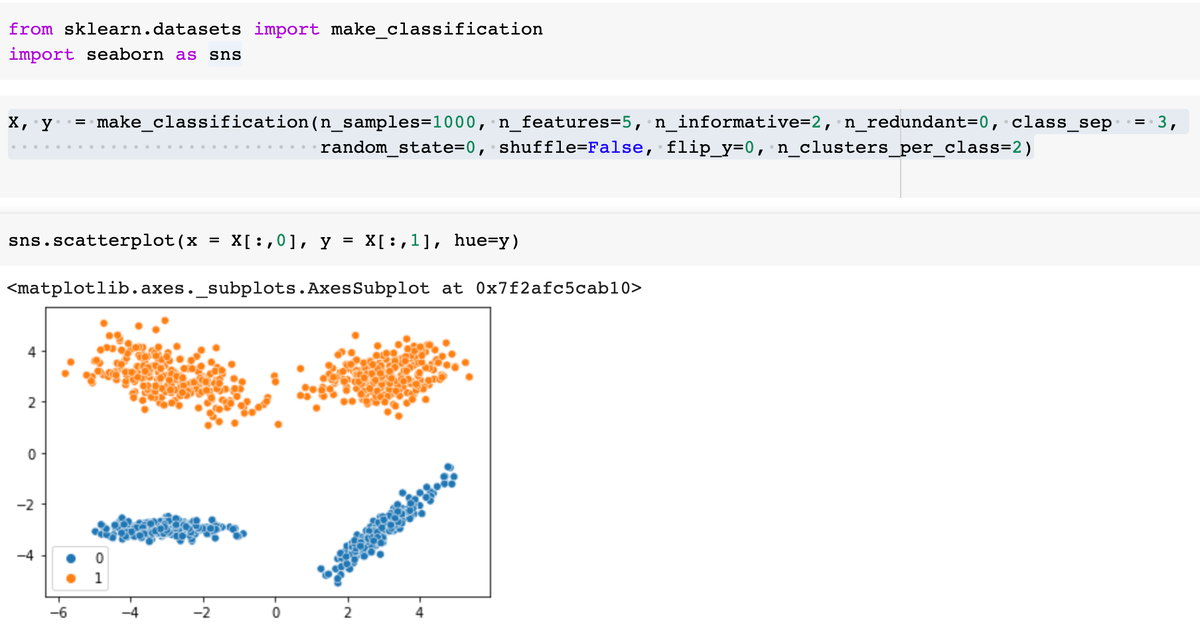
Если 1: