Мои другие большие статьи.
Почему позитивисты привели физику к краху. Разбор Электродинамики, СТО, ОТО, Стандартной модели, модели виртуальных частиц, темной материи.
Почему я не верю в марсоходы на Марсе и полеты на Луну.
Библия с научной точки зрения.
Кто построил пирамиды, когда их построили и зачем.
Роскосмос - провал в каждом действии.
Является ли униполярный двигатель примером безопорного движения?
Глобальное потепление это мошенничество.
Предположительная фальсификация статистки по коронавирусу.
История развития процессоров хорошо описана в статье: «Эволюция микропроцессорных архитектур». Если вкратце то:
"Институт точной механики и вычислительной техники. Он был создан по приказу Сталина в 1948 году"
«Второе поколение (1954–1962) ознаменовалось переходом от электронных ламп к полупроводниковым диодам и транзисторам со временем переключения порядка 0.3 мс. Появление регистрового файла позволило организовать машины либо с регистровой архитектурой, либо со стековой архитектурой. Тогда стековая архитектура превалировала над регистровой, благодаря очень компактному коду.
Третье поколение вычислительной техники (1963–1972) ознаменовалось переходом от дискретных полупроводниковых элементов к интегральным микросхемам, что обусловило скачок производительности. Зарождаются принципы конвейеризации и суперскалярности (принципы мелкозернистого параллелизма). Появляются многозадачные ОС. Архитектура системы команд (ISA) сильно развивается, предоставляя программистам более развитые команды. Такую ISA впоследствии назовут CISC.
Четвертое поколение (1972–1984) осуществило переход на СБИС (тысячи транзисторов на одном кристалле). Появление языков высокого уровня привело к резкому снижению востребованности CISC инструкций, так как компиляторы использовали только небольшое подмножество из них. Оказалось целесообразным перейти к архитектуре с сокращенным набором команд (RISC).
В девяностых годах доминируют суперскалярные процессоры. Принципы мелкозернистого параллелизма эксплуатируются максимально. Процессор содержит сложную логику динамического планирования в неупорядоченной модели обработки. Увеличение числа конвейеров и станций резервации приводит к экспоненциальному росту взаимосвязей между ними, что ограничивает дальнейшее распараллеливание на уровне команд.
Итак, назревшая необходимость использования более высоких уровней параллелизма определила перспективные пути развития GPP: VLIW, SMT и CMP. Переход от RISC к VLIW (как в процессорах общего, так и специального назначения) позволил преодолеть ограниченность ILP. Тенденции многопоточного (SMT) и многоядерного процессирования (CMP) привели к аппаратной поддержке крупнозернистого параллелизма.»
Как мы видим VLIW является дальнейшим развитием процессорных архитектур. Кстати впервые теоретически VLIW была разработана в СССР. Почему же произошел крах архитектуры VLIW? На сайте www.anandtech.com в свое время вышел подробный разбор архитектуры Intel и HP IA-64 если такую кто-то еще помнит.
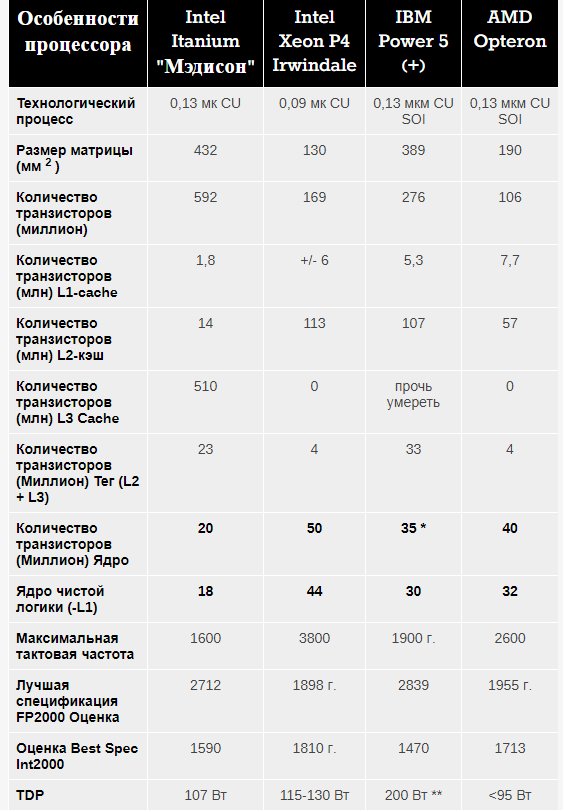
Так собственно ядро Itanium составляло всего 18 млн. транзисторов, а с совместимостью с x86 примерно 20 млн. транзисторов. При этом производительность ядра была очень конкурентоспособной. Что же произошло? Ответ заключается в том что инструкции IA-64 были размером приблизительно 40 бит, IBM Power 30 бит, а x86-64 всего 20 бит. Т.е. IA-64 для той же эффективности требовалось в два раза больше кэша чем x86-64. Вместо того что бы наращивать мелкие ядра Intel приняла решение наращивать кэш L3. Это было ошибочное решение. (Для крупных ядер ARM и в особенности x86-64 выгоднее увеличивать кэш L3, L2 и в ряде случаев L1, так как ядра занимают много места и до бесконечности количество ядер увеличивать невозможно, лучше кэш L3/L4 размещать на отдельном чиплете). Так же большие вопросы вызывают очень маленькие кэши L1 и L2. И хотя IA-64 в в два раза превосходила по производительности на ватт IBM Power 5, она так же значительно уступала x86-64. Поскольку у Intel уже была другая архитектура, то по сути следовало сделать выбор либо в пользу x86-64 или IA-64, к сожалению выбор, был очевиден. Как итог всей этой истории VLIW сам по себе оказался не виноват. Надо еще сказать что Intel не только пустила под откос концепцию VLIW, но и по сути выкрала разработки из России, выкупив разработчиков Эльбруса с помощью г-на Бабаяна (сам Бабаян не имеет прямого отношения к разработке ЭВМ, он занимался ПО, а весь его пиар был нужен только для того что бы подороже продаться на запад). Есть еще одна история с Transmeta. Сразу хочу сказать что концепция делать VLIW процессор с динамической компиляцией вызывает большие сомнения так как вы сразу можете вычесть 20-30% производительности процессора на накладные расходы. Возможно у Transmeta были еще какие-то проблемы так как их ядро содержало больше транзисторов чем VIA C3 и было медленней. Самое интересное, что точку в производстве процессоров Transmeta так же поставила Intel. После того как Transmeta подала иск против Intel произошли довольно странные вещи. Через некоторое время Transmeta вдруг продает пакет спорных лицензий за копейки и прекращает разработку процессоров. Мое мнение заключается в том что Intel произвела рейдерский захват и заменила менеджмент Transmeta на более послушный, после чего забрала лицензии на технологии энергосбережения. Вы скажите не может быть! Но иск был на огромную сумму, так как Intel пришлось бы заплатить за огромное количество процессоров произведенных за несколько лет. Единственной успешной VLIW архитектурой стали VLIW5 и VLIW4. Это были выдающиеся GPU, которые смогли захватить солидную долю рынка. Почему их закрыли? Мода на VLIW стала проходить. Те кто закрыл VLIW потеряли солидною долю рынка, но главное же это не доля рынка, а следование моде ведь правда?
x86-64 против ARM против RISC-V.
В индустрии среди ведущих архитекторов идет дискуссия о том важны ли ISA. И я слышал мнение, что архитектура гораздо важнее ISA. Конечно, эффективная архитектура очень важна. Но вот пример. ARM потребляет меньше энергии чем x86-64. Почему? Ответ потому что x86-64 осуществляет трансляцию из CISС в RISC (все современные процессоры x86-64 внутри являются RISC). Трансляция требует энергии, поэтому еще никому не удалось создать такой же эффективный x86-64 процессор как ARM и я думаю это не удастся никогда. RISC-V при той же производительности может занимать более чем в двое меньшую площадь чем ARM, RISC-V эффективнее чем ARM. Нет ни каких сомнений в том что ISA гораздо важнее архитектуры.
Концепция Маленький Большой.
В ARM существует довольно интересная концепция «Маленький Большой».
Достоинства этой концепции. Маленькие фоновые ядра могут поддерживать фоновые задачи тогда когда нет большой нагрузки и загружать мощные ядра нет смысла. Но на ПК это не имеет ни какого смысла. Второе достоинство этой концепции в том что производительность широких ядер растет в линейно, тогда как количество транзисторов растет в квадрате. Если разместить 4 ядра на той же площади что и одно большое то такие ядра будут только в два раза слабее большого. Третье достоинство это маркетинг. Мы можете продавать кучу ядер но часть из них будут слабыми.
Недостатки. Существенным недостатком является то что очень сложно распределить нагрузку между ядрами. С фоновыми задачами все ясно их перемещаем на слабые ядра. Если же допустим процесс завис то его так же необходимо переместить на слабое ядро, но планировщик будет думать что процессу требуется много производительности и такой процесс поместят на производительное ядро. Это очень часто случается с браузером Хромиум в Виндовз, у него постоянно зависают страницы.
Вторым недостатком является то что слабые ядра могут не поддерживать все функции крупных ядер, такие как виртуальная многопоточность, дополнительные расширения и т. д. Кроме того слабые ядра, как правило, работают на меньшей частоте, все это приводит к тому что слабые ядра становятся не в два раза менее производительными, а гораздо больше.
Если и делать на ПК концепцию Большой Маленький то слабые ядра должны поддерживать многопоточность и все инструкции, а так же должны иметь ту же частоту что и большие ведь экономить энергию не требуется. Я скептически отношусь к Большой Маленький на ПК так как только ограниченный класс программ поддерживает большое количество ядер.
Почему СССР перешел на IBM-360.
Вы не поверите, но до перехода на IBM-360 СССР был на мировом уровне в создании ЭВМ. СССР так же принадлежит приоритет в создании первой в мире ЭВМ с программируемой структурой. Создание компьютерной сети в 1958 году, на 7 лет раньше чем в США. Впервые применена суперскалярная архитектура. БЭСМ-6 была одной из лучших ЭВМ в мире.
"В БЭСМ-6 было реализовано расслоение оперативной памяти на блоки, допускающие одновременную выборку информации, широко использован принцип конвейеризации команд. Был впервые внедрен метод буферизации запросов, создан прообраз современной кэш-памяти, реализована эффективная система многозадачности и обращения к внешним устройствам и многие другие инновации, некоторые из которых применяются до сих пор"
Так БЭСМ-6 обладала быстродействием в 1 млн. операций, CDC-6400 так же 1 млн. (Была CDC-6600 2-3 млн операций, но поскольку она использовала много параллельных блоков, есть сомнения что она достигала пиковой производительности в реальных задачах). Следует отметить что существует мнение что БЭСМ-6 является клоном Атлас и CDC-1604. Тем не менее оно полностью ошибочное. Позже БЭСМ-6 была выпущена в виде эмулятора Эльбрус-1К2 2,5-3 млн и Эльбрус-1К-Б 4-5 млн операций в секунду, но сути это был перевод БЭСМ-6 на микросхемы с усовершенствованиями, дальнейшего развития линейка БЭСМ так и не получила.
По стечению обстоятельств Эльбрус не только помогла БЭСМ-6 прожить еще какое то время, но и была практически единственной выжившей после перевода всего на IBM совместимость, высокопроизводительной архитектурой которая развивались быстрее чем западные архитектуры. Так Эльбрус-1 был первой суперскалярной архитектурой, впервые в СССР использовал TTL микросхемы. В программном отношении ее главное отличие — ориентация на языки высокого уровня. Для данного типа комплексов были также созданы собственная операционная система, файловая система и система программирования «Эль-76». Производительность Эльбрус-1 1980 года составляла 10-12 млн. операций. Эльбрус-2 1985 год, до 125 млн операций в секунду. Эльбрус-3 1991 год, 1 млрд операций в секунду. Эльбрусы очень хорошо показывают какими темпами могли бы развиваться собственные ЭВМ в СССР.
Если сравнивать советские ЭВМ и ЭВМ EC, то легко подсчитать, что перевод на IBM архитектуру отбросил нас примерно на 6 лет. Да последняя ЕС-1766, обладала быстродействием от 600 млн (первое более реально) до 2 млрд операций, но мы такую ЭВМ могли бы произвести еще в 1981-1989 году. Она была запланирована на 1995 год и только большая необходимость и огромная господдержка позволили ее выпустить в 1987 году, на 8 лет раньше.
В 2000 году подписанты под IBM 360 и прежде всего г-н Пржиялковский организовали ответ в котором оправдывали переход на IBM 360 катастрофическим отставанием от запада, вот их аргументы.
1. «Эта оценка является неверной в принципе, потому что делается только с точки зрения оригинальности аппаратной архитектуры ЭВМ, тогда как роль и место вычислительной техники определяются значимостью и масштабом ее применения для решения народно-хозяйственных и оборонных задач.»
Итак по версии подписантов быстродействие и оригинальные идеи оказывается не являлись передовым краем ЭВМ, а надо смотреть на широту применения ЭВМ. Тут я хочу отметить что на самом западе и тогда и сейчас почему то мнение совершенно противоположное. Гонка быстродействия и применения различных идей, которые позволят получить это быстродействие происходит постоянно. Т.е. фиксируем то что подписанты нам попросту лгут.
2. «В конце 60-х годов в СССР выпускалось одновременно множество различных типов ЭВМ самого разнообразного назначения, чаще всего несовместимых друг с другом.»
Создание программносовместимой архитектуры не требовало перехода на IBM 360 и авторы не могут этого не знать. Кроме того на западе ситуация была такой же — была масса архитектур которые были не совместимы между собой. IBM 360 была всего лишь одной из, а не единственной, как это пытаются утверждать подписанты. Более того многие считают IBM 360 откровенно неудачной архитектурой, продавленной на рынок мощью IBM. Пентиум 4 продался гигантским тиражом, но был тупиком. В СССР единообразие да же не требовало создание программносовместимой архитектуры, надо было только в директивном порядке назначить самую удачную архитектуру базовой и от нее выпустить упрощенные и более быстрые варианты. Т.е. и тут подписанты лгут.
3. «Отставание тогда было как раз драматическим, потому что суммарный годовой выпуск всех типов ЭВМ (а их насчитывалось более 20) в СССР составлял всего около тысячи штук, что никак не могло удовлетворить потребности народного хозяйства и обороны страны. А в США к тому времени был уже налажен массовый выпуск ЭВМ. Соответственно имело место серьезное отставание и в области прикладного и системного программного обеспечения ЭВМ. Академик А. А. Дородницын в докладе на Коллегии ГКНТ СССР в январе 1969 г. оценивал это отставание в 9 лет, указывая, что в СССР тогда было всего 1,5 тыс. программистов, а в США - 50 тыс.»
Количество выпускаемых ЭВМ решалось планами по выпуску ЭВМ, количество программистов решалась планами по выпуску программистов — какое вообще отношение к этому имеет решение о переходе на IBM 360? Нам что IBM программистов стала готовить? Я могу да же больше сказать ЕС 1020 была выпущена тиражом всего в 755 шт, а ведь она была наиболее простой, по идее подписантов она должна была стать самой массовой ЭВМ в СССР поскольку должна была устанавливаться практически чуть ли не в любое учреждение в СССР, куда можно было вообще установить ЭВМ, но оказалась невостребованной. Тогда как близкая по быстродействию к предыдущей ЭВМ ЕС-1022 была произведена чуть большим тиражом 3828 против 2889 т.е. ни какого роста в разы (увеличение можно списать как на то что у ЕС-1022 в своем классе не было конкурентов, так и на рост экономики). Это рушит все аргументы подписантов о том что один только переход на IBM 360 сразу делал ЭВМ более востребованными и более массовыми. Все закончилось пшиком. Более того по ряду данных отечественные ЭВМ до ЕС, были гораздо надежнее, ЭВМ серии ЕС постоянно ломались. Убытки были большие, так кто что там говорил про пользу для экономики от ЕС серии?
4. «Всего за 20 лет промышленностью были поставлены для народного хозяйства и обороны страны более 16 тыс. вычислительных комплексов ЕС ЭВМ.»
А в 60-х годах ЭВМ по признанию подписантов поставлялись около 1000 шт/год. 1000 шт умножаем на 20 лет получаем 20000 шт за 20 лет. Получается что в 60 годах в СССР производили больше ЭВМ чем позже ЕС ЭВМ. ЕС ЭВМ просто суперджет какой то.
5. «Задача разработки семейства моделей, программно совместимых между собой и с машинами семейств 360 и 370 фирмы IBM, была в инженерном отношении даже более сложной, чем разработка семейства с собственной оригинальной архитектурой.»
Т.е. подписанты признают что по сути делалась двойная или да же тройная и никому ненужная работа, вместо того что бы создать оригинальную архитектуру на которой можно было сконцентрировать все усилия. И все это исключительно для организации совместимости с западом.
По сути подписанты в типичной манере западников и после развала СССР пытались утверждать что IBM 360 была неким чудом, одно только внедрение которой сразу бы увеличило выпуск ЭВМ и программистов в разы. На деле же ничего этого не произошло, а различное количество выпускаемых в СССР и США ЭВМ обуславливалось различным типом экономик. В плановой экономике такого количества ЭВМ было просто не нужно. Объяснить это просто: в СССР ЭВМ устанавливались в институты, заводы, НИИ и собственно все. На западе существовал огромный спрос со стороны частных организаций, которые закупали ЭВМ для конкуренции между собой, т.е. с точки зрения плановой советской экономики просто грели воздух и создавали мельтешение. Эти организации и потребляли подавляющее количество ЭВМ. Никакая западная архитектура не могла увеличить продажи ЭВМ в СССР, потому что это завесило не от системы команд, а от типа экономики, скорей да же наоборот собственные ЭВМ были дешевле и поэтому продажи были бы чуть больше, но сотни тысяч ЭВМ продавать было некому, на них не было покупателей. Аналогичная ситуация была и по легковым автомобилям. В США был культ частных домохозяйств и загородных домов, где без собственной машины ни куда. В СССР все жили в городах и ездили в автобусах. Ни какая копия западной машины не подняла бы продажи автомобилей в СССР до уровня США. Еще хуже обстояло с якобы поставленной задачей увеличить количество программистов. Копирование западного ПО делало большое количество программистов не нужными, т.е. декларировалось одно, а на деле по факту выходило совершенно другое. Поэтому есть все основания полагать что основная цель была идеологическая, а аргументы прикручивали по ходу этого фарса.
Так почему же в СССР было принято такое решение? Предлог заключается в том что IBM-360 обладал одним достоинством это была первая универсальная архитектура. Т.е. с выходом следующей модели не надо было переписывать весь софт, что для других архитектур было обычным делом. Так же поскольку нам якобы должно было пойти западное ПО "с целью возможного использования того задела программ, который можно полагать имеющимся для системы 360". Предательство заключалось в том что вместо копирования концепции применительно к уже советским ЭВМ, было принято дикое решение копировать сами ЭВМ IBM-360 т.е. да же не 8 битный байт или систему команд, а тупо создавать клоны зарубежных ЭВМ ЕС-1020 (20 тыс операций, 755 шт, 71-75 года), ЕС-1022 (80 тыс операций, 3828 шт, 75-82 года). ЕС-1022 была чуть быстрее на микросхемах, чем самая массовая ЭВМ СССР на транзисторах в 1968 году. Вот и думайте стоило ли оно того. Самое интересное, что да же сейчас суперкомпьютеры создаются на экзотических архитектурах, если это сулит выигрыш в производительности, кроме того известно, что специализированные архитектуры всегда быстрей универсальных, а переписать ПО стоит не так уж и дорого, более того обычно да же сейчас с выходом следующей модели процессора ПО обычно все равно оптимизируется, переход на универсальную архитектуру нужен был прежде всего обычным ПК, переписывать ПО каждый раз там действительно не имело ни какого смысла. Т.е. все что происходило было авантюрой. Это привело к целому ряду последствий. Во-первых, ЭВМ IBM-360 были очень медленными. Во-вторых, они были изготовлены на другой технологической базе, пока мы бы привели свою технологическую базу в соответствие с западной IBM бы уже выпустила 2-3 поколения, что фактически и произошло. Далее мы фактически навсегда обрекали себя на отставание, что потом неоднократно демонстрировалось западниками в качестве якобы доказательства отсталости СССР.
Вот что об этом говорит типичный научно популярный прозападный ресурс:
«Советская микроэлектроника в 1970-х, несмотря на отдельные успехи, от американской сильно отставала и все больше склонялась к копированию западных образцов. Был выпущен и аналог i8080, получивший обозначение КР580ИК80.»
Главным исполнителем всего этого был Келдыш.
Почему это произошло? Это была политика Брежнева. Есть очень сильные подозрения, что Брежнев пришел к власти в СССР при прямой поддержке США. Кроме того Брежнев исповедовал так называемую идеологию разрядки. Смысл идеологии разрядки заключается в том что бы сдавать западу все то что запад хочет лишь бы запад не раздражать. США очень не нравилось первенство СССР в ЭВМ, поэтому США Брежнева попросили ликвидировать, Брежнев послушно ликвидировал. Скажите это не правда? Что ж я могу рассказать такую же историю только про космос. США безумно раздражало первенство СССР в космосе и вдруг Брежнев закрывает Н-1 и всю Лунную программу, а после этого открывает абсолютно бесперспективный проект Энергия-Буран во главе главного врага Королева Глушко. У нас до сих пор есть рыдальцы (наш Шаттл) по программе Энергия-Буран с красивыми сайтами, главный офис одной бывшей космической организации построен в виде Энергии-Бурана, хотя они сразу могли делать его в виде Спейс Шаттл что люди не путались и знали на кого работает эта организация. Все эти люди предатели. Ах какая жалось загубили, загубили, лично мне жалко не то что загубили Энергию-Буран, а то сколько на нее выкинули денег и времени. История с Н-1 1 в 1 похожа на ликвидацию советских ЭВМ.
Патриоты и псевдопатриоты.
Смысл всей этой истории заключается в том что всегда существуют люди которые готовы проголосовать за самое глупое и вредное решение если оно спущено сверху, более того таких людей большинство. Я таких людей называю псевдопатриотами, поскольку они регулярно путают интересы страны с интересами отдельных политиков. Те кто защищал советские ЭВМ или уволились или продолжали работать, но уже выполняя принятое решение. В современной России таких решений принимали и принимается масса. Я например больше не интересуюсь современным космосом, потому что есть большая вероятность что через 10-20 лет будут с ностальгией вспоминать не количество пусков и долю рынка в 2000-х годах, а то что у нас вообще была космонавтика.
Современное положение на рынке компьютеров.
AMD.
Руководство АМД имеет проблемы с расстановкой приоритетов:
Все ресурсы брошены на серверный рынок и там действительно все хорошо: рост числа ядер, рост каналов памяти, MI300 очень впечатляет.
В то же время старт десктопной платформы провалился. Меня не слишком интересуют сервера, но что мешает АМД взять у АРМ/
SiFive их серверные ядра, разместить на своих чиплетах вместо Zen и продать? АРМ компактнее x86 в 1,8 раза, а RISK-V компактнее АРМ еще в 2 раза, у Zen Xc нет ни каких шансов.
1. Zen4 нельзя было выпускать на АМ5, так как платформа была дорогой, в то же время был огромный спад, Zen4 надо было выпускать на платформе АМ4, но Zen4 синхронизировали с серверной платформой, на продажи в десктопах было наплевать.
2. Zen4 надо было выпускать с чиплетами по 10 ядер, так как 16 ядер уже не достаточно, но АМД выпускает одни и те же чиплеты и для десктопов и для серверов, поэтому вместо 10 ядерного чиплета посчитали что проще получить убытки в десктопах чем возится с дополнительным чиплетом. Это серьезная ошибка. TDP в 170/230 Вт не имеет ни какого смысла так как по тестам дал микроскопический прирост.
3. Провал старта Zen4 это не первый провал АМД, точно так же провалился старт Zen3 поскольку АМД не учла дефицит, а до этого провалился старт Zen2 4000 в ноутбуках. У АМД нет опционов на покупку дополнительных пластин в дефицит и нет запасного поставщика что является серьезной ошибкой. Пока руководство АМД рассуждало что альтернативы TSMC нет, руководство NV поехало к Самсунг и наладило производство упаковки для их процессоров - это разница между некомпетентностью и компетентностью.
4. В ноутбуках нет разделения на чиплет CPU и чиплет GPU, поэтому АМД там не может значительно наращивать количество ядер ни CPU ни GPU почему нет никто не знает, но скорей всего АМД просто не заморачивается ибо пофиг. Так же именно в ноутбуках пригодился инфинити кэш, но его там нет. Можно сделать один чиплет CPU один чиплет GPU и один общий кеш L4 отдельным чиплетом для CPU и GPU. Ядра Zen Xc ничем не помогут АМД в ноутбуках. Дело в том что малые ядра в мобильных процессорах нужны для экономии энергии, тогда как Zen Xc АМД делает в ноутбуках для экономии площади, как бы есть разница? Кроме того экономия площади очень не велика всего около 35%. И все это только ради того что бы не делать чиплеты в ноутбуках. Т.е. если АМД хочет извлечь пользу из малых ядер им их придется спроектировать отдельно, но так что бы они поддерживали все функции больших ядер ну AVX512 можно запускать на 1/4 от полной скорости. Кстати почему АМД убрала FMA4 очень хорошие инструкции.
5. В десктопах то же было бы неплохо сделать мощные АПУ для тех кто не хочет покупать дискретную графику: 2 чиплета CPU + 1 чиплет GPU уровня 3050-3060 или хотя бы 1 чиплет CPU + 1 чиплет GPU, но АМД встроила графику в IOD...
6. Почему мобильные CPU АМД выходят через пол года после их анонса? Никто не знает, но скорей всего ответ в том что мобильные чипы ни как не связанны с серверным сегментом, поэтом АМД пофиг их делают как и пользовательские видеокарты просто что бы не расстраивать акционеров.
7. Радеон графикс. Нескончаемый эпик фейл. Была отличная архитектура VLIW5 с которой АМД была в лидерах, они все рушат и выпускают GCN, которая на 30% менее эффективна и проигрывают NV. Была Фури. Странные карты с HBM, которая была там не нужна, но эти карты продавались, все что надо было это увеличить количество блоков в 1,5 раза и обогнать NV. Они назначают К., который в игровых видеокартах ничего не понимает и он вместо хорошей игровой видеокарты добавляет к Фури 40% площади серверных функций и АМД вынуждена продавать Вегу64 в убыток. Но GCN была еще ничего по сравнению с настоящим бредом под названием RDNA, которую разработал как говорят тот же К. Вместо того что бы ее выкинуть ее запустили в продакшен. С RDNA 2 АМД вполне могла бы выиграть, но вместо того что бы оптимизировать RDNA 1 и удвоить ее с шиной 512 бит, АМД встроила туда инфинити кэш который занимал 1/4 площади чипа. Надо быть полным идиотом что бы увеличить площадь чипа на 1/4 вместо того что бы развести на плате дополнительную копеечную шину в 256 бит. Естественно NV снова победила, а АМД снова пролетела. Потому что от главы АМД поступило "мудрое" указание развивать GPU как CPU. RDNA3. Вместо того что бы сделать 8 SE, АМД делает только 6 SE и проигрывает NV причем проигрывает с треском, убытки ничто ведь есть указание любой ценой беречь ширину шины. GPU не CPU в GPU если есть возможность надо всегда избегать больших кешей и делать ставку на широкую шину. При этом RDNA 3 на 70% менее эффективна чем RDNA 2 и не смотря на распускаемые одним из ютьюб каналом слухи дело не в чиплетах 7600 ничем не отличается от 6700 кроме архитектуры и если учесть частоту то 7600 всего на 10% быстрей 6700. Чиплетов нет, а производительность не выросла. Первое что АМД должна была сделать в RDNA 3 это удвоить блоки рейтресинга, затраты транзисторов минимальны, а эффект огромный. Кроме того каждая версия RDNA хуже предыдущей: 4890 70,9 балла/млрд. транзисторов, 5870 VLIW5 46,4 балла/млрд. транзисторов, 6970 VLIW4 43,6 балла, 7970 GCN 1.0 36,6 балла, 290X GCN 2.0 35,2 балла, R9X GCN 3.0 30,6 балла, 590 GCN 4.0 31,1 балл, 5700XT RDNA 1.0 25,1 балл, 6950XT RDNA 2.0 17,2 балла, 7900XTX RDNA 3.0 10 баллов. Когда АМД представляла HD58хх они заявли что 256bit шина не ограничивает видеокарту и многие АМД тогда поверили, тем не менее это была ложь. При удвоении блоков в два раза в средним видеокарта только в 1,47 раза быстрее 4890, т.е. WLIV5 быстрее чем GCN почти в 2, а эффективность RDNA падает как камень с каждой итерацией. Вместо того что бы просто разделить RDNA 3 на два чиплета один чиплет GPU и один чиплет кеш, АМД кеш разделила на 6 частей и теперь мы имеем 7800XT, которая по производительности будет в лучшем случае равна 6800XT. RDNA 3.0 это катастрофа. 7900XTX имеет только в 1,2 больше блоков но количество транзисторов возросло в 2,15 раза. По самым лучшим подсчетам скорость рейтрейсинга возросла на 1 блок только в 1,32 раза. Куда ушли остальные транзисторы? АМД заявила что ее интересует только серверный рынок. Судя по всему это правда. Когда я попросил АМД сделать 7950XTX с 8 ядрами АМД ничего сделала, когда я сказал что неплохо бы сделать MI350X с HBM3E сразу пошли слухи о ее подготовке. Если вы вполне доходные пользовательские рынки держите за второсортные и ничего туда не вкладываете, то вам не следует здесь ждать какого либо успеха. MI300X это отличная грамотно спроектированная карта, 7900XTX похожа на какой то хлам в котором сломали да же энергопотребление в простое не добавив туда практически ни каких функций. де 6900XT можно считать Fury, которая была не идеальна, но реально работала, 7900XTX это самая настоящая Vega64, я бы да же сказал что это хуже чем Vega64 в 7900XTX количество транзисторов на один блок увеличилось в 1,79 раза, в Vega64 только в 1,4 раза. При этом 6900XT ни в коем случае нельзя считать идеальной, так разгон 6900XT с 2250 до 2600-2800 МГц привел всего к росту 4% производительности. Это значит 6900XT была ограничена 256 битной шиной памяти. АМД опять солгала складывая ПСП кэша с ПСП памяти, если данные не поступают в кэш вовремя то ни какая ПСП кэша не будет достаточной. Ей требовалось не менее 288 бит, а еще лучше 320 бит. Почему инженеры АМД выбрали 256 битную шину? Возможно потому что у АМД самые глупые инженеры. Я слышал слухи про RDNA 4 это очередной инженерный шедевр, который провалился бы: делать 3D склейку чипов будет очень дорого. Можно же просто было сделать 3 чиплета: 2 чиплета GPU, 1 чиплет кеша и не дорого и работает. Почему АМД не использует чипы памяти разной плотности и шину 96 бит? 7600 смотрелся бы гораздо лучше с памятью 10Гб с одним чипом памяти двойной плотности чем с 8 ГБ. Я считаю что если АМД не вернет VLIW5 и не прекратит использовать GPU в качестве подопытного кролика вместо здорового консерватизма они практически гарантировано закопают свое подразделение графики в течении нескольких лет.
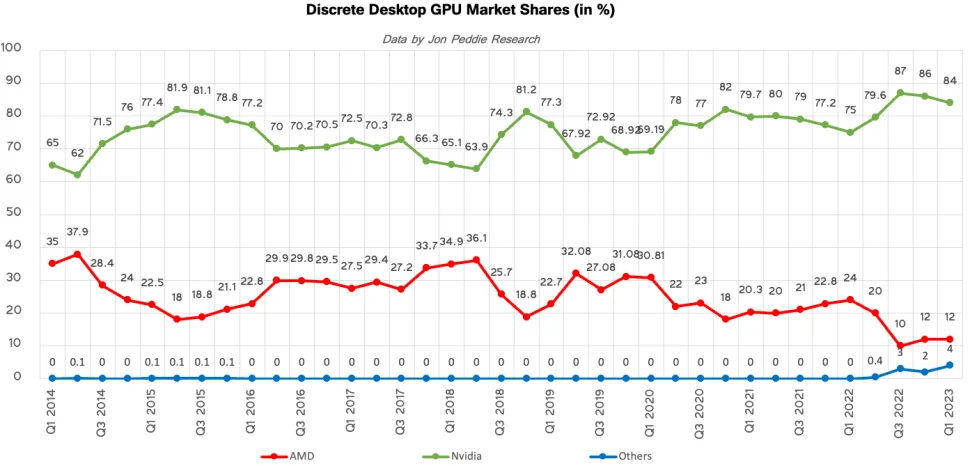
Ни когда еще с 2014 года доля Радеон не падала так низко.
Заявление АМД о том что они не могут сделать в ноутбуках чиплеты является очередной маркетинговой ложью. АМД говорит что чиплеты не энергоэффективны и поэтому вместо того что бы увеличивать количество ядер в чиплетах они увеличивают в серверах количество чиплетов и поэтому их сервера такие производительные и энергоэффективные. Подождите я что-то запутался. Кстати я считаю что надо на серверные CPU снизить цены на 10-15%, что бы доля АМД росла и росла прибыль. Так как после повышения цен на Zen4 доля АМД перестала расти. Месяц назад они рассказывали что они не могут сделать 24 ядра на АМ5 потому что им не хватает пропускной способности памяти, хотя они могли это сделать да же на АМ4 хотя бы как 8-10 Zen4(X3D) + 16 Zen4c + DDR4-4000. И они сейчас представляют HEDT 64 ядра на 4 каналах памяти или 16 ядер на один канал. Просто для того чтобы разделить платформы и не дать обычным пользователям ни ядра больше чем АМД считаем необходимым (на этой "гениальной" стратегии АМ5 + 16 ядер АМД получила убытки три квартала в десктопном сегменте). А сейчас доля АМД в ПК зависла на уровне 19-20%. Нет больше ядер и многопоточной производительности больше чем у конкурента нет роста доли рынка. То же самое касается и ноутбуков. АМД должна была сделать 10-12 ядер и чиплеты еще с Zen3, но предпочла только повышать цены. АМД совершает ту же самую ошибку что и с Athlon64 не заняв и 50% рынка взвинтили цены и раст доли АМД остановился. Эти люди ни когда не будут лидерами вечно довольствуясь номером 2.
Я не согласен с руководством АМД:
1. Отсутствием в видеокартах VLIW5 и постоянными попытками сделать из пользовательских видеокарт серверные, что каждый раз заканчивается полным провалом и убытками.
2. Постоянным повышением цен что свело рост доли АМД к минимуму. Если вы владеете мизерной долей рынка то рентабельность в 50% не имеет ни какого смысла. Так АМД так и не смогла восстановить свою долю рынка в мобильном сегменте после катастрофы в 3 квартале 2022 года.
При этом на мобильные процессоры приходится 70% продаж всех пользовательских CPU. Более того переименование 7000 линейки в 8000 еще привело к падению доли рынка так как преимущество над конкурентом сократилось до 13-14% при 55Вт и до 24-25% при 25Вт (Zen4 против Meteor Like). А ведь когда то АМД превосходила конкурента в 3 раза при 25Вт по производительности (Zen2 против Ice Like). У АМД имеются очень хорошие чипы HX в том числе и X3D для высокопроизводительных и игровых ноутбуков. Они превосходят при 100Вт чипы конкурента при 230Вт, более того это обычные десктопные чипы упакованные в мобильную упаковку, т.е. для АМД очень дешевые и массовые. Хотите купить эти отличные ноутбуки? Удачи вам в поиске потому что купить их практически не реально. Если это не саботаж то я не знаю что это такое.
3. Выпуск Zen4 на АМ5. Я очень долго говорил что использовать DDR5 до 6400 не имеет ни какого смысла и тем не менее АМД выпустила Zen4 с дорогой и медленной 5200. По видимому что бы синхронизировать переход на DDR5 с серверной платформой, хотя в этом не было ни какого смысла. Такое чувство что в АМД работают непроходимые глупцы. Так же я против того что АМД полностью забросила APU. Они выходят с большим опозданием, а некоторые вроде 6000 линейки да же не появляются в продаже. Кроме того АМД делает некоторые мобильные процессоры вроде X3D или 7900M эксклюзивными для производителей что снижает и так мизерные продажи.
4. Выпуск 4 Zen5 + 8 Zen5c является ошибкой так как это переводит данный процессор из мейнстрима в бюджетные решения. Надо было делать 12 Zen5c ядер для низковольтных решений и 12 Zen5 для обычных. Бессмысленное крохоборство руководства АМД перешло все разумные пределы. Чиплетный процессор не имеет чиплета с 12 ядрами, что позволило бы комбинировать различные варианты от 8 ядер до 24 с интегрированной графикой разной производительности.
5. ИИ. Очень хорошая технология. Есть только одна проблема, при большой занимаемой площади она совершенно бесполезна для покупателя, так как чрезвычайно слабая но будьте уверены что каждый покупатель оплатит дополнительную площадь кристалла. Покупатель хочет что бы компьютер написал ему текст на заданную тему, распознал рукописный текст, сжал бы звук и видео ИИ кодеком с встроенной фреймгенерацией и апскейлингом, пересчитал бы фильм из 24 кадров в 36 или 48, перевел черно-белый фильм в цветной, перевел бы фильм с одного языка на другой с сохранением оригинального голоса и интонаций, удалил или добавил на фотографии объекты - ничего этого CPU ни GPU не могут. Они слишком маломощные. ПО для пользователей нет потому что делать его из-за слабости встроенных блоков ИИ бессмысленно. Я против того что бы встраивать большие блоки ИИ в процессоры так как они все равно абсолютно бесполезны для пользователей, единственно кому они приносят пользу это руководству компании для того что бы похвастаться перед инвесторами. Мне надоело спасать АМД от глупостей которые генерирует руководство АМД.
Теперь они рассказывают что они не могут сделать чиплеты в ноутбуках хотя бы для основного их чипа 25-55 Вт, хотя они конечно же могут это сделать, но они не хотят давать пользователям слишком много ядер и слишком мощную интегрированную графику. По слухам Стрикс Пойнт будет монолитным и иметь либо 4 Zen5+8 Zen5c либо 12 Zen5c. А так же будет 4 нм. Это не имеет ни какого смысла так как только 4 ядра Zen5 или полное их отсутствие сделают данный чип бесполезным для игр, что сразу скажется на доле АМД на рынке. Ядра ZenXc вообще для ноутбуков не имеют смысла так как они дают очень небольшую экономию площади по сравнению с ZenX. Для ноутбуков нужны либо ZenX либо маленькие ядра в 1/4 площади ZenX для экономии энергии.
Они урезали свои мобильные дискретные чипы и их топовая видеокарта 7900М по производительности между 4800М - 4070М, хотя они могли только снизить частоты своих десктопных видеокарт и обогнать NV по производительности.
Потеря 10% рынка десктопов и 8% рынка ноутбуков всего за один квартал с 2 по 3 ничему АМД не научила.
Как уничтожить только что купленное подразделение персональный рецепт от руководства АМД.
1. Купить Радеон Графикс в деятельности которой вы ничего не понимаете.
2. Интегрировать Радеон Графикс в компанию, причем не интересуясь целевой аудиторией.
3. Вложить в доработку VLIW5 много денег и достигнуть с HD5000 победы.
4. Выкинуть VLIW5, вложить много денег в другую архитектуру GCN.
5. Проиграть конкуренцию с GCN.
6. Сделать хорошую карту Фури.
7. Запихнуть в GCN кучу неграфических блоков что бы сделать из нее серверный ускоритель Vega 64 - снова проиграть. Единственная хорошая идея в Vega 64 это было исполнение на FP64 двух инструкций FP32, если бы она еще могла на FP64 выполнять 4 инструкции FP16 или 8 инструкций FP8 было бы еще лучше, но для геймеров эти функции совершенно бесполезны.
8. Разработать еще худшую архитектуру RDNA вместо того что бы вернуться к VLIW5. Снова проиграть.
Хорошо заметно что как только в Радеон Графикс все налаживается, руководство АМД делает все что бы все рухнуло. HD5000 достигла успеха - ликвидировать VLIW5. Фури достигла определенного успеха - поменять руководство и напихать туда неграфических блоков. 6000 линейка была более менее успешна, хотя она была бы еще успешней без кэша, давайте все уничтожим и сделаем снова все наоборот, а что бы быстрей тонуло напихаем в карту 128 ИИ блоков. Запихивание неграфических блоков в игровые карты это пунктик у руководства АМД.
Разберем на примере RDNA 3. Необходимо что бы RDNA 3 была чиплетной тогда да же с худшей эффективностью, АМД могла бы сделать больший чип и выиграть. Вместо 8 SE они делают 6 SE и проигрывают (по моим подсчетам этого как раз бы хватило что бы чуть чуть но обойти NV в растеризации). Едем далее. Логично что бы именно графический процессор стал чиплетным, а кэш монолитным поскольку чиплетный GPU это хорошее вложение в будущее, потом все GPU можно делать из чиплетов от 1 до 4, монолитный кэш эффективен, чиплетный же кэш сделать большого ума не надо но это ничего не дает кроме задержек и роста объема кэша. Следовало сделать 2 чиплета GPU + 1 чиплет кэша. Но Радеон Графикс делает все наоборот GPU монолитный, а кэш чиплетный и аж на 6 частей. Руководство Радеон Графикс знало что у них слабая производительность рейтресинга. Вместо двух блоков на конвейер они оставляют 1 блок на конвейер, за то внедряют 2 блока AI на 1 конвейер. Возникает вопрос зачем? Пользовательских приложений AI нет и профессиональных кстати то же (различные графические и аудио программы только разрабатываются) и AI блоки не будут продавать видеокарты, логично было либо пока не встраивать данные блоки либо встроить их минимум например 32 или 64 блока. Т.е. на рейтрейсинг АМД наплевать поскольку она о геймерах не заботится, да же не смотря на то что низкая производительность рейтресинга заставляет продавать видеокарты значительно дешевле и блоки рейтресинга занимают очень небольшое место, а встроить 128 блоков AI, которые совершенно бесполезны, но занимаю очень много места это совершенно не проблема. Растеризация. NV удвоила блоки расчетов, но на конвейер там один блок ALU и один FPU. АМД удвоила блоки как у NV и да же сделала VLIW2 но почему то VLIW2 используется не для склейки частых, а для для редких инструкций надо ли удивляться что от удвоения исполнительных устройств производительность выросла на 10%? Так откуда у АМД возьмется +70% производительности как у NV? По факту RDNA 3 это карты которые не имеют целевой аудитории еще одна Vega64, только все еще хуже. Производительности растеризации нет, производительности рейтресинга нет - значит карты не нужны ни геймерам ни профессионалам, для которых рейтресинг очень важен. Блоки ИИ геймерам и профессионалам не нужны, а для серверов их производительности не достаточно, ставить игровые видеокарты в сервера можно только от безысходности. Как итог 7000 линейку АМД делала для себя, вот пусть она эти карты и покупает тогда, если мнение клиентов АМД категорически не интересует. Недавно. Хорошо бы NV представила DLSS для рейтрейсинга - тут же читаю новость DLSS 3.5 для рейтресинга. Перед анонсом 7900XTX: хорошо бы что бы был чиплетный GPU большой площади с удвоенными блоками рейтрейсинга - чиплетного GPU нет, большего числа блоков рейтресинга нет, GPU маленький, за то есть чиплетный кэш и куча неграфических вычислений. Никто не виноват что Радеон Графикс и АМД делают не то что хотят геймеры, а все ровно наоборот - именно поэтому у NV доля 85%, а у АМД 12%. Т.е. руководство Радеон Графикс выполняет безумные приказы руководства АМД, которое в свою очередь руководствуется чем угодно, но только не интересами геймеров, поэтому падение доли Радеон Графикс с 24% до 12% совершенно не удивительно. Я считаю что Радеон Графикс должна быть частично отделена от АМД, что бы концентрироваться только на геймерах и 10 млрд рынке видео игр, она должна отчитываться перед АМД только по двум параметрам: доля рынка и прибыль. Серверное подразделение может быть с АМД, кстати почему MI300 делают целый год и почему только у MI300X есть 192ГБ HBM? Так же я считаю что в игровые видеокарты должна быть возвращена VLIW5.
Intel.
12 поколение принесло много плохого. Так 4 маленьких ядра занимают 128% от большого, а одно 32%. При этом на одной частоте маленькое ядро имеет только половину производительности большого ALU и 1/3 FPU. Маленькие ядра так же имеет меньшую частоту и не имеют НТ. Т.е. ни какого выигрыша от маленьких ядер нет. Для сравния ядра P470 имеют всего в 1,5 раза меньшую чем P670 производительность IPC, имя при этом занимая почти 1/4 площади и работая на той же частоте, что и P670. Обзоры по alder lake произвели крайне неприятное впечатление. Такое чувство что Intel заносило деньги чемоданами или да же вагонами. Одни обозреватели в выводах заявили что эти процессоры лучший выбор да же несмотря на огромное TDP, другие измеряли TDP в играх, хотя это совершенно бессмысленно поскольку запутанные такими обзорами покупатели в обычных приложениях не досчитаются существенной производительности, третьи несмотря на то что в обычных приложениях важна латентность, а не ПСП объявили что надо покупать DDR5, а не DDR4 (DDR4-3800 CL16 равна DDR-6000 CL40), четвертые вообще не заметили у Intel предельную температуру в 100 градусов, больший TDP и большее падение производительности и заявли что 95 градусов АМД невозможно охладить, хотя охлаждение с температурой ни как не связано, так же ряд сайтов сравнивали оптовые цены Intel за 1000 процессоров с розничными ценами АМД. Макрософт выпустила новую систему специально под новые процессоры, но почему то не оптимизировала ее под процессоры конкурента.
Графическая архитектура Intel Arc... провалилось. Если коротко то главный архитектор сделал очередную Vega64, опоздавшую уже не на полгода, а на 1,5 года, не ориентированную на геймеров, а Intel добавила к этому "легендарное" качество своих драйверов и не адекватные цены.
Itanium были бы хорошими процессорами, если бы Intel не увлеклась гигантоманией в частности огромным L3 кешем. Если бы Itanium производились бы по современным тех процессам, а не по устаревшим то можно было бы легко обменять объем кеша на количество ядер, так как ядра очень маленькие и все было бы вполне хорошо.
PRAM зачем Intel купила PRAM вместо CB-RAM? Никто не знает. CB-RAM это лучшая альтернативная память на рынке. Она не деградирует, может хранить до 8-9 бит в ячейке. Может использовать тех процессы более современные чем Флэш. Легко штабелируется. Более того непонятно зачем PRAM использовалась в SSD вместо того что бы использовать ее в оперативной памяти где она была рентабельна. Итог. Ринувшись на модные тренды они получили убытки сами и практически похоронили рынок альтернативной памяти.
NVIDIA.
Горящие разъемы 12VHPWR. Когда разъемы видеокарт 4090 начали гореть некий ютуб канал GN провел некое расследование. Они купили несколько видеокарт 4090 и тестировали их и у них не сгорел ни один разъем, после чего этот ютуб канал обвинил во всем пользователей, дескать они не до конца вставляют вилку в разъем вот он и сгорает. NVIDIA тут же приняла эти выводы и выпустила новый разъем с удлиненными силовыми контактами и укороченными сигнальными. Тем не менее разъемы продолжают гореть. Почему?
Дело том что GN не является сертифицированной лабораторией, все их выводы ничего не значат. Допустим шанс выиграть в лотерею составляет 0,5% (примерный шанс что ваш разъем сгорит) если вы купили 10 лотерейных билетов и если ни один билет не выиграл то значит ли что лотерея мошенничество? Ответ нет. Тем не менее GN заявили что с разъемом все в порядке. Т.е. это GN являются мошенниками. На каком основании NVIDIA приняла выводы какого то не сертифицированного ютуб канала за истину не известно, но думаю дело в деньгах. Немного переделать разъем и спихнуть всю вину на пользователей гораздо проще чем взять вину на себя, отзывать видеокарты и полностью переделывать разъем.
Реальная причина горения разъема давно известна. Запас по току контактов слишком низок и контактов слишком много. Если на одном или нескольких контактах возникает повышенное сопротивление то ток начинает течь через остальные контакты и разъем сгорает. Пользователи ни в чем не виноваты.
Что теперь?
Микрон последний раз покупал оборудование в 2009 году и может производить 90 нм и теоретически 65 нм. Запад в нм мы уже не догоним. Выход есть переходить на GaN транзисторы, частоту чипа можно увеличить в 5-15 раз. Такую электронику можно ставить в спутники. Роскосмос сейчас переходит на микросборки и чип платы это технологии 60-70-х годов. Эти деятели последние 15 лет говорили об импортозамещении, но когда пришло время оказалось, что ничего не сделано. Видимо были слишком заняты приватизацией и развалом Роскосмоса, а так же ликвидацией Протона-М.
У нас есть собственная архитектура Эльбрус. От былого величия Эльбрус-3 остались одни воспоминания. Так же есть и кое какие ошибки в развитии:
1. Проектирование архитектуры под конкретный техпроцесс. Пока архитектуру спроектируют меняется уже 2 техпроцесса. Как итог Эльбрусы всегда выпускаются на старых техпроцессах и всегда отстают. ИФМ РАН к 2030 году завершит разработку российского рентгеновского EUV-литографа. Очень круто по всем характеристикам превосходит западный, вот только он в 30 году сможет делать микросхемы 16 нм, другие в это время запустят 2 нм с нанолистами. 16нм к 2030 году на сверхдорогой рентгеновской литографии это глупо. Я давно предлагаю сначала перейти на электронную безмасочную литографию, а потом на электронную масочную литографию и забыть об этих лазерах.
2. Очень низкая частота процессора для данного техпроцесса, ее можно поднять в 2 раза. Так же отсутствует функция уменьшения тока при таком же или чуть большем напряжении. Это очень сильно снижает ТДП при той же частоте процессора. Такая функция есть на материнских платах Асус и она реально работает. Более того транзисторы можно проектировать специально под низкий ток тогда эффект будет еще больше. Например ток при том же напряжении можно будет уменьшить в 5 раз.
3. В компилятор не вкладывалось значительных сил. Потери на компиляторе до 2,5 раз. Суммарно техпроцесс + оптимизация на частоту + оптимизация компилятора могли бы сделать Эльбрус в 8 раз быстрее. Если еще перейти на GaN то скорость можно поднять в 2-3 раза. Т.е. итого 16-24 раза. Так же на мой взгляд перспективен Иридий, приемлемое сопротивление при очень хорошем сопротивлении электромиграции. Можно делать да же серебряный проводник в оболочке из иридия.
4. Отсутствие биннинга. Процессор или без повреждений или его выкидывают.
5. Отсутствуют чиплеты. Например несколько чиплетов CPU, чиплетов GPU, отдельный общий кеш L4, HBM память. Так же можно рассмотреть CB-RAM память в качестве энергонезависимой DDR или да же L4 кеша.
6. Отсутствует сжатие инструкций и аппаратного сжатие кеша. Это критично так как в отличие от других архитектур здесь нет декодера и в кеше лежат сырые данные.
7. Отсутствие виртуальной многопоточности.
8. Отсутствие собственного высоко оптимизированного языка.
9. Отсутствует собственная VLIW видео архитектура. Для числодробилок и видеокарт VLIW идеальна. Затраты низкие производительность высокая. Можно так же использовать один FP64 для двух FP32 и четырех FP16.
10. Разработка ведется на специально спроектированных под каждый процессор ПЛИС, хотя расчеты показывают что использование GPU является более выгодным, так как ускорение больше, кроме того добавив GPU можно проектировать более сложный CPU не меняя всю аппаратную часть. Так же ошибочно ведется моделирование всего CPU со всеми ядрами - это дорого и не нужно. Моделируем одно ядро - отладка архитектуры. Потом моделируем ядро с памятью и периферией. Затем 4 ядра для отладки межпроцессорного взаимодействия. Затем можно эмулировать все ядра и отлаживать только межпроцессорный интерфейс. Крутить весь CPU с большим количеством ядер с памятью и периферией - хорошо живете и деньги не считаете!
Поэтому Эльбрусы вроде живы, но конкурируют они не с самыми свежими западными процессорами. Основная проблема Эльбрусов это очень слабый компилятор. Преимущество VLIW в том что вы можете либо сильно раскидывать инструкции по конвейерам в компиляторе либо делать это гораздо менее эффективно в самом процессоре. Поэтому у VLIW есть очень серьезные преимущества. Кроме того вам не надо тратить транзисторы на декодер и блок переупорядочивание команд. Но поскольку компилятор гораздо эффективнее, его создание и стоит гораздо дороже. Разница как между кодированием видео в реальном времени с низким сжатием и кодированием гораздо медленнее с гораздо большим сжатием - выгода от сильного сжатия очевидна. Так если Эльбрусу написать нормальный компилятор, а не то что там есть сейчас производительность можно поднять до 2,5 раз. Еще один путь забития конвейеров это виртуальная многопоточность. Я считаю оптимальным 1 поток на 2 конвейера. У Эльбруса 6 конвейеров, значит оптимальным будет 3 виртуальных потока на 1 ядро. Так же возможна модификация какого либо языка специально для VLIW архитектуры. Мне нравится язык D.
Мне удалось решить проблему зависимых инструкций. Процессор можно делать очень широким. Допустим у нас 8 конвейеров. Первая инструкция в слове выполняется как обычно, вторая и последующие инструкции на втором конвейере ничего не делают, на второй такт первая инструкция передвигается на вторую стадию, а вторая инструкция на первую стадию второго конвейера, но результаты вычисления первой инструкции могут использоваться для второй инструкции. Третья инструкция и последующие все еще ожидают. Таким образом когда первая инструкция будет выполнена вторая инструкция все еще будет выполнятся и для нее уже будут готовы результаты вычисления первой инструкции.
Проблема Эльбруса так же и в хроническом отставании по техпроцессам. Разработчики к каждому техпроцессу готовят новую архитектуру и пока они ее готовят, техпроцессы уходят далеко в перед. Так 6 версия архитектуры привязана к 16 нм, а 7 к 7 нм. Т.е. пока 7 версию не доделают процессор на 7 нм не выйдет. При этом 16 ядреный процессор 6 версии архитектуры на 16 нм занимает слишком большую площадь 618 мм2. Почему бы его было не выпустить на 10 или 7 нм? Расходы бы сократили, частоту подняли. Следует переводить Эльбрус на готовый техпроцесс без изменения архитектуры, а архитектуру запускать тогда когда она будет готова на том техпроцессе который будет доступен. Возможно так же что архитектура Эльбруса несколько устарела, возможно стоит подумать об другой VLIW архитектуре, которая вберет в себя все достижения современного процессоростроения. Особенно стоит обратить внимание на сжатие инструкций. Может быть, за основу взять RISC-V. Если планируется штатная поддержка других архитектур, то стоит использовать ПЛИС вместо софтверный трансляции. Я думаю что смог решить проблему невозможности использования зависимых инструкций в одном слове. Что бы решить проблему надо сдвинуть каждый конвейер на одну ступень назад. Тогда первая инструкция будет выполнятся первой в первом конвейере, вторая инструкция будет выполнятся во второй такт на втором, когда результаты первой инструкции будут готовы и т.д. При этом на второй такт можно будет выполнять следующую первую инструкцию в первом конвейере.
Почему создаваемый российский рентгеновский сканер это ошибка? Сейчас для возобновления производства Эльбрусов строится завод и разрабатывается новый рентгеновский сканер. Есть только одна проблема, к тому моменту когда он заработает он сможет производить только 10-нм, которые к тому времени безнадежно устареют. Конечно позже мы сможем производить и более тонкие транзисторы, но вот беда к тому времени когда мы сможем это сделать безнадежно устареют сами Эльбрусы. Сканер конечно надо разрабатывать но я считаю что разрабатывать надо электронно-масочный сканер а не рентгеновский, в отличие от электроно-лучевого электроно-масочный сканер не имеет проблем с производительностью, а вот отличие от рентгеновского проблем с сверхдорогим источником света, но сейчас самое главное купить через третьи руки хороший сканер который может производить 12-7 нм продукцию - этого нам хватит на несколько лет и не будет стоить огромных денег.
Плохая гос поддержка.
Очень тревожная ситуация сложилась с гос поддержкой. В новом проекте минпромторга понятие отечественный компьютер по сути заменяется системой баллов. Причем сумму баллов можно набрать не устанавливая ни отечественный процессор ни видимо отечественною материнскую плату. Кроме того и сроки внедрения отечественных компьютеров в госорганах и банках переносится. Так же когда некоторые госорганы цифровизировали (медицину в том числе) я надеялся что поступит заказ на отечественные компьютеры, но никакого заказа так и не поступило.
«Компания заявила о противоречии проекта изменений в постановление правительства №719 «О подтверждении производства промышленной продукции на территории России» утверждённой президентом России Доктрине информационной безопасности, а также Стратегии развития электронной промышленности до 2030 года. «Ослабление требований облегчит внесение в реестр локализованной продукции зарубежных производителей <…> Продолжится проникновение зарубежных платформ в критическую инфраструктуру <…>, что приведёт к ухудшению информационной защищённости цифровой экономики в целом. Это— прямая угроза национальной безопасности», — считает Александр Ким.»
Получается довольно интересная ситуация: все время декларируется поддержка отечественных ЭВМ, но в реальности под давлением видимо зарубежных поставщиков и тех кому компьютеры предназначены, меры по импортозамещению не только не усиливаются, но и постоянно ослабляются.
Предлагаю дать четкое определение отечественного компьютера:
ЭВМ с разработанным в России процессором оригинальной отечественной архитектуры, произведенной в России материнской платой и корпусом.
И ЭВМ совместимой с зарубежной архитектурой произведенной в России:
ЭВМ с разработанным в России процессором с лицензированной и/или заимствованной в т.ч. доработанной в России архитектуры, произведенной в России материнской платой и корпусом.
Первые для критического и военного применения, вторые могут допускаться для менее критических применений.
К сожалению система баллов была принята. Это означает что в условиях когда Эльбрусы отрезаны от современных тех процессов они станут совершенно не конкурентноспособны, их и раньше то гос органы покупали без большого желания, а теперь вообще не будут. Мы вообщем можем с Эльбрусами попрощаться. Так же не совсем понятно тогда зачем нам современные тех процессы и огромные инвестиции в них на Микроне. Современные техпроцессы нужны только для ЦПУ и ГПУ если нам собственные процессоры не нужны то и в тех процессы вкладываться бессмысленно. Складывается парадоксальная картина - чем больше против России вводят санкций тем все сильнее Россия под эти санкции прогибается и тем все эффективнее и более открыто действует в России пятная колонна. То же самое например с нефтью. По сути 27-28 декабря Россия подписалась под ценовым потолком на нефть, так как запад выше 60 долларов покупать не будет и в контракты по перевозки ни один вменяемый покупатель пункт о потолке прописывать не будет. Т.е. законопроект абсолютно бессмысленен и только провоцирует нефтяные компании на продажу нефти по цене ниже 60 долларов или на махинации с ценами продать в порту за 50, после перегрузки, получить левыми доходами еще 10-20 долларов и вывести их и России. Доказательством служит то что ни какого скачка цен на нефть не произошло, т.е. Россия просто согласилась на ценовой потолок и нефть уходит за бесценок. Мы могли отказаться продавать нефть всем кто ввел против нас санкции, привязать свою нефть к брент и за счет роста цен продавать меньше за большие деньги, но решили ползать в грязи. Рассказы о том что существуют некие отдельные рынки на которых формируется некая отдельная цена это сказки. Цена на нефть глобальна и формируется на бирже. Разные сорта нефти могут стоить чуть дороже или чуть дешевле, но цена нефти определяется биржей, разные марки нефти во многом взаимозаменяемы, а нефть высоколиквидный товар, который можно доставить в любую точку. Допустим запад отказывается покупать у нас нефть, а Индия говорит что дескать она будет покупать но только за 40-50 долларов. Тогда мы отказываемся продавать нефть Индии, Индия идет на глобальный рынок, а поскольку лишней нефти нет, то она начинает конкурировать за нефть с западом, цены взлетают и вместо 80 долларов она покупает нефть по скажем 120 долларов. И мы спокойной продаем нефть с некоторой скидкой тем кто готов ее у нас купить. Так работает рынок нефти. То что сейчас нам втирают некие авторитетные люди про цены на отдельных рынках это полное вранье и афера. Цена этого решения уже известна - 6 млрд. долларов дефицита бюджета.