Обзор основных концепций проектирования нейронных сетей Pytorch
Pytorch - это среда глубокого обучения, разработанная исследовательской лабораторией искусственного интеллекта Facebook в 2016 году. Она широко известна благодаря приложениям, ориентированным на компьютерное зрение. Более того, он отличается простотой, мощной поддержкой графического процессора и реализованными внутри алгоритмами глубокого обучения. Благодаря этим функциям Pytorch - одна из наиболее часто используемых библиотек в академических исследованиях.
В Интернете есть много руководств по Pytorch, а на веб-сайте Pytorch - много документации. Но слишком много информации может сбить с толку и привести к потере времени. Моя цель - показать обзор основных функций и классов, доступных в Pytorch, а также показать несколько примеров. В этом уроке я легко и интуитивно освещу темы, которые полезно знать перед тем, как приступить к построению нейронной сети.
Содержание:
- Тензор
- Умножение матриц
- От Pytorch до NumPy и наоборот
- Дифференциация в Автограде
- Однослойная нейронная сеть
- Простая нейронная сеть
1. Тензор
Тензор - это объект Pytorch, представляющий многомерный массив. Он похож на массив NumPy. Чтобы лучше понять основные функции построения тензоров, я покажу примеры с использованием Numpy, чтобы показать, что логика такая же.

Numpy и Pytorch используют множество похожих функций для создания матриц.
Исключение составляет функция построения матриц идентичности. Pytorch использует функцию eye, а NumPy - идентификатор функции.
2. Умножение матриц
Когда модель нейронной сети обучается, происходит много умножений матриц. Я покажу два типа умножения.
В NumPy функции dot и matmul используются для произведения между двумя матрицами. Существует также оператор @ в качестве альтернативы, если вы не хотите использовать функции.
Pytorch имеет ту же функцию matmul, что и NumPy. Другая возможность - это функция torch.mm. Разница между ними в том, что torch.mm не поддерживает трансляцию.
В случае поэлементного умножения NumPy использует умножение, а Pytorch использует простой оператор *
3. С Pytorch на NumPy и наоборот.
Массив Numpy можно преобразовать в Tensor с помощью функции from_numpy. Обратную операцию можно выполнить с помощью функции numpy.
4. Дифференциация
Производная составляет фундаментальный аспект нейронных сетей. Действительно, алгоритм градиентного спуска использует производные для изучения модели. Цель этого алгоритма - минимизировать функцию потерь J. Затем значения параметров будут изменяться до тех пор, пока мы не получим оптимальное значение J.
Это правило ускорит или замедлит обучение в зависимости от двух характеристик: скорости обучения и производной функции потерь по рассматриваемому параметру, w или b. Я хочу сосредоточиться на концепции производной.
Что это означает?
Она представляет собой наклон функции. Когда значение производной велико, функция быстро меняется, а когда оно близко к 0, функция не меняется, и это может быть проблемой при обучении в контексте нейронных сетей. В этом примере я сравнил прямую, параболу и гиперболу.
Прямая линия имеет небольшую производную по сравнению с параболой и гиперболой, которые имеют высокие значения. Можно заметить, что значение параболы в 4 раза больше значения прямой линии, а значение гиперболы в 3 раза больше значения параболы, поэтому она изменяется в три раза быстрее, чем парабола.
5. Однослойная нейронная сеть.
В нейронной сети каждый столбец признаков в наборе данных представлен как входной нейрон, а каждое взвешенное значение представлено как стрелка от столбца признаков к выходному нейрону. Мы умножаем характеристики на веса и суммируем их, затем добавляем смещение и прогоняем его через функцию активации. Таким образом мы получаем выход сети.
Например, если у нас есть входной вектор с одной строкой и 10 столбцами, у нас будет 10 нейронов.
Математически это выглядит так:
В коде я создал входной вектор с помощью функции randn, которая используется для создания матриц, заполненных случайными числами из нормального распределения со средним значением 0 и дисперсией 1. Взвешенная матрица будет иметь тот же размер, что и входные данные, но с разными весами. Смещение состоит из одного значения нормального распределения. Мы можем использовать matmul для умножения матриц между входами и весами, затем мы можем применить функцию активации sigm (относящуюся к сигмоиду), чтобы отобразить любое значение от 0 до 1.
Код возвращает ошибку. Очень часто, когда вы обучаете нейронную сеть ,вы будете встречать этот тип ошибки. Это связано с тем, что количество столбцов входных данных не равно количеству строк в w1. Чтобы решить проблему, нам нужно изменит это. В Pytorch есть три способа сделать это:
- w1.reshape (10,1) возвращает новый тензор с теми же данными, что и w1, но с формой (10,1)
- w1.view (10,1) возвращает новый тензор с теми же данными, что и w1, и другой формой (10,1).
- w1.resize_ (10,1) возвращает тот же тензор с другой формой (10,1)
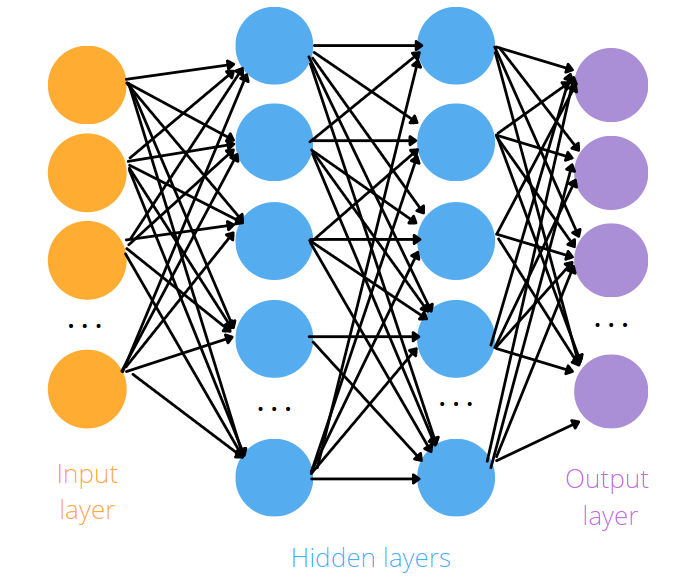
6. Простая нейронная сеть
Теперь мы собираемся изучить простейшую модель нейронной сети, которая называется полностью связанной сетью. Каждый нейрон в слое связан с каждым нейроном следующего слоя. Рассматриваемая ниже архитектура имеет один выходной слой, два скрытых слоя и один выход. Как и раньше, мы получаем входные данные, веса и смещение с помощью функции randn. Вместо того, чтобы делать вычисления только для одного слоя, мы делаем это для каждого слоя.
Ниже я покажу, как определить класс, который определяет Сеть и наследуется от nn.Module. Полностью связанные слои строятся через nn.Linear (in_features, ou_features). Первый аргумент - это количество единиц ввода, а второй аргумент - количество единиц вывода.
Последние мысли:
Я надеюсь, что это руководство помогло вам лучше понять Pytorch посредством общего обзора. Иногда бывает так легко заблокировать при программировании, и, вероятно, потому, что некоторые вещи были непонятны или просматривались слишком быстро, не имея времени на то, чтобы хорошо их запомнить. Код Github здесь.https://github.com/eugeniaring/Pytorch-tutorial/blob/main/pytorch-for-beginners.ipynb Спасибо за прочтение. Хорошего дня!